A nonclustered index has the same index structure as a clustered index, with two important differences:
- A nonclustered index does not change the physical order of the rows in the table.
- The leaf pages of a nonclustered index consist of an index key plus a bookmark.
The physical order of rows in a table will not be changed if one or more nonclustered indices are defined for that table. For each nonclustered index, the Database Engine creates an additional index structure that is stored in index pages.
A bookmark of a nonclustered index shows where to find the row corresponding to the index key. The bookmark part of the index key can have two forms, depending on the form of the table—that is, the table can be a clustered table or a heap. (In SQL Server terminology, a heap is a table without a clustered index.) If a clustered index exists, the bookmark of the nonclustered index shows the B+-tree structure of the table’s clustered index. If the table has no clustered index, the bookmark is identical to the row identifier (RID), which contains three parts: the address of the file to which the corresponding table belongs, the address of the physical block (page) in which the row is stored, and the offset, which is the position of the row inside the page.
As the preceding discussion indicates, searching for data using a nonclustered index could proceed in either of two different ways, depending on the form of the table:
- Heap Traversal of the nonclustered index structure is followed by the retrieval of the row using the RID.
- Clustered table Traversal of the nonclustured index structure is followed by traversal of the corresponding clustered index.
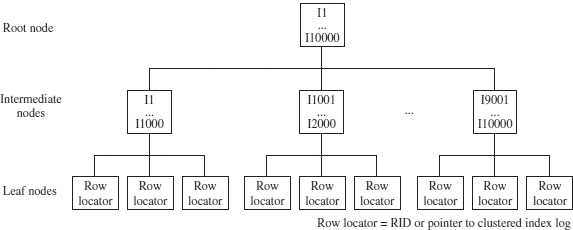
Figure 1. Structure of a nonclustered index
In both cases, the number of I/O operations is quite high, so you should design a nonclustered index with care and only when you are sure that there will be significant performance gains by using it. Figure 1 shows the B+-tree structure of a nonclustered index.
Leave a Reply