A clustered index determines the physical order of the data in a table. The Database Engine allows the creation of a single clustered index per table, because the rows of the table cannot be physically ordered more than one way. When using a clustered index, the system navigates down from the root of the B+-tree structure to the leaf nodes, which are linked together in a doubly linked list called a page chain.
The important property of a clustered index is that its leaf pages contain data pages. (All other levels of a clustered index structure are composed of index pages.) If a clustered index is (implicitly or explicitly) defined for a table, the table is called a clustered table. Figure 1 shows the B+-tree structure of a clustered index.
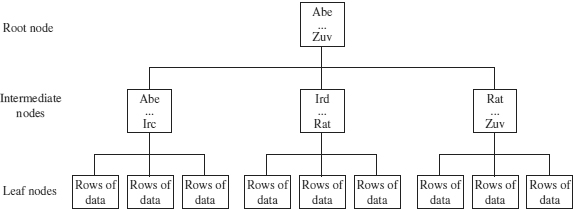
Figure 1. Physical structure of a clustered index
A clustered index is built by default for each table for which you define the primary key using the primary key constraint. Also, each clustered index is unique by default—that is, each data value can appear only once in a column for which the clustered index is defined. If a clustered index is built on a nonunique column, the database system will force uniqueness by adding a 4-byte identifier to the rows that have duplicate values.
NOTE
Clustered indices allow very fast access in cases where a query searches for a range of values.
[…] nonclustered index has the same index structure as a clustered index, with two important […]