Database systems generally use indices to provide fast access to relational data. An index is a separate physical data structure that enables queries to access one or more data rows fast. Proper tuning of indices is therefore a key for query performance.
An index is in many ways analogous to a book index. When you are looking for a topic in a book, you use its index to find the page(s) where that topic is described. Similarly, when you search for a row of a table, the Database Engine uses an index to find its physical location. However, there are two main differences between a book index and a database index:
- As a book reader, you can decide whether or not to use a book’s index. This possibility generally does not exist if you use a database system: the system component called the query optimizer decides whether or not to use an existing index. (A user can manipulate the use of indices by using index hints, but their use is recommended only in a few special cases.)
- A particular book’s index is edited together with the book and does not change at all. This means that you can find a topic exactly on the page where it is determined in the index. By contrast, a database index can change each time the corresponding data is changed.
If a table does not have an appropriate index, the database system uses the table scan method to retrieve rows. Table scan means that each row is retrieved and examined in sequence (from first to last) and returned in the result set if the search condition in the WHERE clause evaluates to TRUE. Therefore, all rows are fetched according to their physical memory location. This method is less efficient than an index access, as explained next.
Indices are stored in additional data structures called index pages. (The structure of index pages is very similar to the structure of data pages.) For each indexed row there is an index entry, which is stored in an index page. Each index entry consists of the index key plus a pointer. For this reason, each index entry is significantly shorter than the corresponding row. Therefore, the number of index entries per (index) page is significantly higher than the number of rows per (data) page. This index property plays a very important role, because the number of I/O operations required to traverse the index pages is significantly lower than the number of I/O operations required to traverse the corresponding data pages. In other words, a table scan would probably result in many more I/O operations than a corresponding index access would.
The Database Engine’s indices are constructed using the B+-tree data structure. As its name suggests, a B+-tree has a treelike structure in which all of the bottommost nodes (leaf nodes) are the same number of levels away from the top (root node) of the tree. This property is maintained even when new data is added or deleted from the indexed column.
Figure 1 illustrates the structure of the B+-tree and the direct access to the row of the employee table with the value 25348 in its emp_no column. (It is assumed that the employee table has an index on the emp_no column.) You can also see that each B+-tree consists of a root node, leaf nodes, and zero or more intermediate nodes.
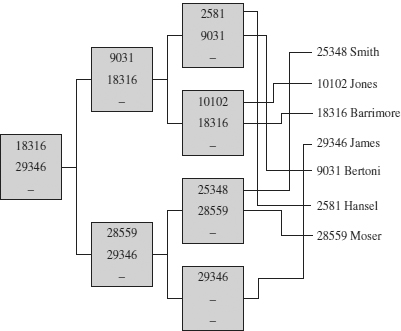
Figure 1 B+-tree for the emp_no column of the employee table
Searching for the data value 25348 can be executed as follows: Starting from the root of the B+-tree, a search proceeds for a lowest key value greater than or equal to the value to be retrieved. Therefore, the value 29346 is retrieved from the root node; then the value 28559 is fetched from the intermediate level, and the searched value, 25348, is retrieved at the leaf level. With the help of the respective pointers, the appropriate row is retrieved. (An alternative, but equivalent, search method would be to search for smaller or equal values.)
Index access is generally the preferred and obviously advantageous method for accessing tables with many rows. With index access, it takes only a few I/O operations to find any row of a table in a very short time, whereas sequential access (i.e., table scan) requires much more time to find a row physically stored at the end of the table.
There are two existing index types: clustered and nonclustered indices.
Leave a Reply