Don’t believe everything you read on the web about clustered vs. nonclustered indexes
I suspect almost every reader of this article has seen or heard the following, as it is posted “everywhere” on the web. Yet if the advice is taken blindly, it can rob your system of top performance.
- Every table should have a primary key (good idea)
- Every table should have a clustered index (good idea)
- Every table should have a primary key that is a single column, integer, identity key (not a bad idea, but too simplistic to take without a grain of salt)
- Every primary key should be a clustered index (herein lies the rub, and the focus of this article)
First, a few facts. Any index may be clustered or nonclustered, but you can have only one clustered index per table (this is one important reason to think carefully before choosing your clustered index). A primary key is instantiated with an index, but this does not have to be a clustered index. This last note surprises more than a few folks, but has been true at least since SQL 4.0 running on OS/2 (anybody remember that one?).
Let’s start with clustered vs. nonclustered indexes.
Clustered indexes are b-tree indexes whose leaf level is the data page of the table; hence, the data pages are physically sorted in index order (this is mostly true, and you can act and tune as if it is completely true).
Nonclustered indexes are also b-tree indexes, but the leaf level is standard, and contains pointers to the data pages.
Let’s do this graphically:

Presume this is a “customer” table which is clustered on the customer’s last name. The data pages become physically sorted by last name at index creation time. Then, further index levels are built out as follows:
While (number of pages in the index level) > 1
Begin
Create a new index level
Copy the first entry from each page of the prior level
Sort it
end
In the above, simplistic example, we have three levels of index, with the first index level being the data (this is unique to the clustered index).
Finding a row in the table via a b-tree structure, we start in the root page. Now find rows whose key is the last name “Baker.”
We start at the root page, and see that “Baker” is between “Albert” and “Jones” by following the “Albert” pointer to the next level. Then we see that Baker is between “Albert” and “Brown” by following the “Albert” pointer yet again. Now, we find ourselves on the data page, and have done so using three page requests.
Since you can have only one clustered index (because you can only sort the data one way), all other indexes will be nonclustered.
Nonclustered index graphically:
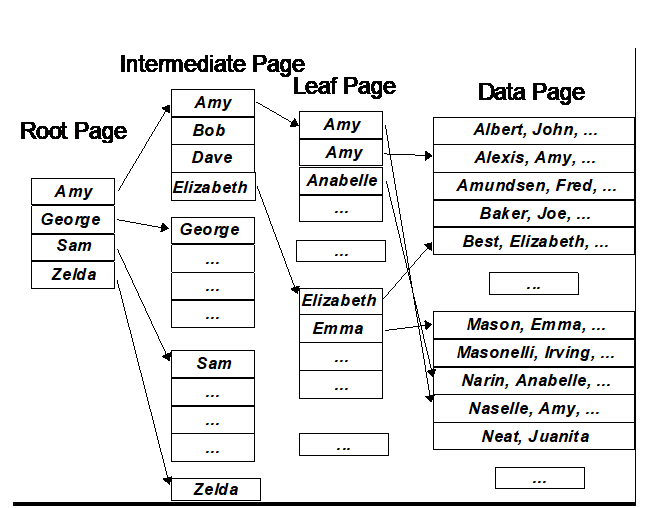
This graphic represents an index on the customer’s first name. The nonclustered index build starts a bit differently than the clustered, as the data is sorted on last name, not first name.
The first index level will have an entry for every row of data (vs. every page of data for the clustered index). So, 1 million customers, 1 million index entries.
The rest of the nonclustered index levels are built the same way the clustered index levels are built.
So, looking for all the “Amy” entries: Amy is between Amy and George, so we follow the Amy pointer to the next level. Amy is between Amy and Bob, so we again follow the Amy pointer. Now we are on the nonclustered index level leaf page and have the list of row IDs that we will use to identify all the Amys. We’re still not done, though, because for each matching entry, we still need to retrieve the matching rows.
Doing some math:
Finding Baker cost us three page requests. Finding Amy cost us three page requests plus one for each entry, which gets us five page requests. When we start diving into this, we see that if we want multiple rows, the clustered index performs much better.
For example, if there are 50 Bakers to retrieve: possibly still three I/Os, possibly four if they run over to the next page. If there are 50 Amys, then it’s three I/Os to get to the leaf level, then 50 more page requests to retrieve the rows, for a total of 53.
(Compared to a table scan, I’ll still prefer the index!)
Now, let’s talk about a simple join, say an invoice header to an invoice detail. Let’s further speculate that there’s an average of 50 detail rows per header.
If you have a nonclustered index on the detail, you have 50 page requests to perform after you have reached the right index page. If you have a clustered index on the detail, you may have no more of this to deal with, or you may need to simply read the next page on the chain.
In short, for simple joins, joining on a clustered index is dramatically faster than joining on a nonclustered index.
As the joins become more complex (say, a three table join), keep multiplying by 50 with each level.
Index covering
Refer back to the nonclustered index, and look at the index pages, which are in fact chained together.
Doesn’t that list look remarkably like the base page of the clustered index? In fact, think about a different query: select count(*) from the table where first_name = ‘Amy.’
Now we don’t have to read the extra pages, as the data we want is directly on the index page. The optimizer is aware of this, and the DBMS picks the data right off of the index page. This is called “index covering.”
Index covering is the one time that the nonclustered index may be faster than the clustered index, as more entries are likely to fit on an index page (entry width) than on the data page (full row width). In fact, it’s common to add columns to nonclustered indexes for this very reason. If all columns referenced in a query (where clause, join clauses, select list) are in the index, the server will not bother reading the data pages.
Summary
Don’t drink the Kool-Aid.
Don’t choose indexes based upon white papers you’ve read. Choose indexes based upon your knowledge of how the optimizer chooses indexes, and what it can do with them.
The Kool-Aid trademark is the exclusive property of Kraft Foods, Inc. All other trademarks the property of their respective owners.
[…] Editor’s Note: “Don’t Drink the Kool-Aid” which was originally published at https://logicalread.com/dont-drink-kool-aid/#.Wud159PwZTZ. […]