Knowing how to select appropriately between SQL-based and PL/SQL-based solutions is one of the most important skills in Oracle database development. Let’s look at two less common examples of using PL/SQL in actual systems development. The first example illustrates the notion of performance tuning by going outside of the regular solution patterns, while the second describes a case of extending standard SQL functionality. Both of these examples demonstrate the depth of the PL/SQL language. It can do significantly more than you might imagine.
Making Life Simpler by Switching to PL/SQL
It is common for SQL statements to grow more complex over time. When a system has been in production for a while, the once-good decision to use SQL may eventually become less and less desirable. This is especially true when data volumes change. Solutions that worked well in a smaller scope often only scale so far, and can eventually lead to catastrophe. The following example demonstrates how switching from SQL to PL/SQL saved the day when the requirements went beyond the scope of the original implementation.
One of the most common problems related to fluctuating between SQL and PL/SQL is the never-ending quest to find an efficient implementation of the “main search” functionality in a system. About 90 percent of contemporary applications include some type of main screen with a number (usually a lot) of different filtering criteria that presents a grid with matching results. At first glance, this would seem to be a straightforward SQL implementation, especially if the search is limited to one table. But sooner or later, you will need to search using data from a group of sources, using multi-select and/or a proximity search (LIKE, SOUNDEX, and so forth). Gradually, the original simple query becomes so convoluted that any time you are asked to add an extra filter, you must automatically budget at least a week of work time because you are not sure of the potential impact on other possible permutations.
It is important to mention some key syntactical aspects of dynamic SQL. First, it allows you to build and execute SQL and PL/SQL on the fly. You can also use object collections in conjunction with Dynamic SQL. Combining these features means that the results of the search can be represented as an output of object collections and the search query that will be generated on the fly to represent the specified search criteria. Instead of building a single generic SQL statement that can survive all possible search permutations, it is much more efficient to create customized SQL statements for each case.
The following is a basic example of such an implementation. Assume that there are requirements to filter employees by employee name, employee ID, and employee location (two filters are from the EMP table, while the third one is from the DEPT table). The output structure that will represent your search results is shown here:
![]()
NOTE
It is critical to make EMP_SEARCH_NT a SQL type, using a CREATE TYPE statement, and not a part of any PL/SQL package. This is necessary because SQL object collection types can be converted into a regular SQL set using the built-in function TABLE (each object attribute becomes a column). Starting with Oracle Database 12c, you can also use package-defined collections for TABLE functions within PL/SQL program units. Even then, you will not be able to run direct SQL statements or make the TABLE function a part of a view if you don’t have a SQL type.
Now you can build a function that will return an object collection, as shown next. Note that, in addition to filters, there is a default limit included. This should become a habit for anyone working with collections. You really don’t want to bring millions of rows into memory just because a user didn’t specify any conditions.


This function has a number of points that require explanation:
Table EMP is always used, while table DEPT is joined only when location is specified. ANSI SQL comes in very handy here because it allows for clearly split filtering and joining.
- You do not want to build permutations of EXECUTE IMMEDIATE to match different combinations of bind parameters that could be referenced. For this reason, it is much easier to generate anonymous blocks to contain all parameters and pass real values as defaults. Using this approach, you still have the full power of bind variables, but you do not have to worry about their order or number.
- The EMP_SEARCH_OT constructor must be included in the query because the output result is an object collection, not a record.
- While building all portions of the queries, it is critical to keep the attributes fully qualified (TABLE.COLUMN).
- If you are using Dynamic SQL, always output it before execution. Doing this saves a lot of debugging time.
The most important idea behind the function shown previously is to achieve the highest level of flexibility without losing performance or readability. Use the following code to run a basic search and see what happens:
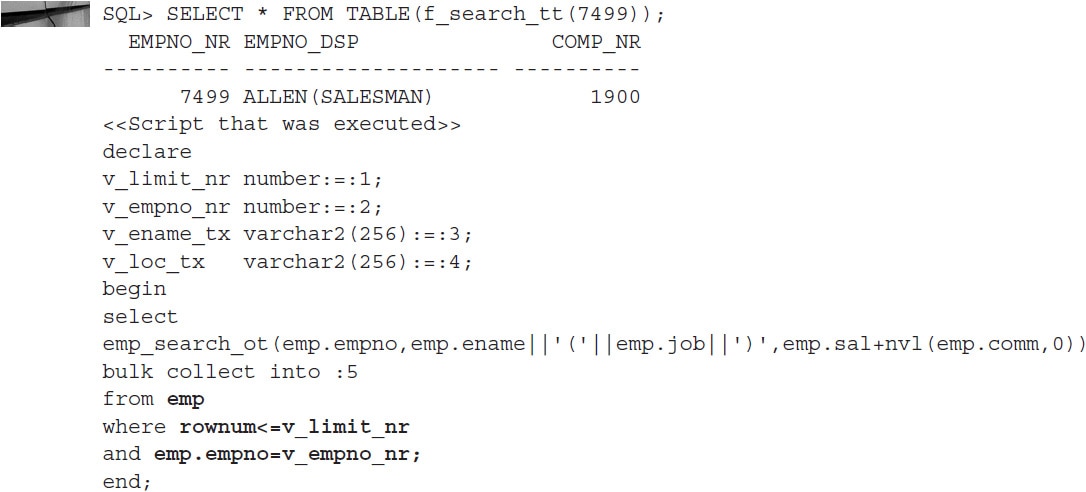
From the printout of executed Dynamic SQL, it is clear that only the EMP table was used and only two conditions were added: EMPNO and ROWNUM. The following shows a different scenario specifying a number of filters:
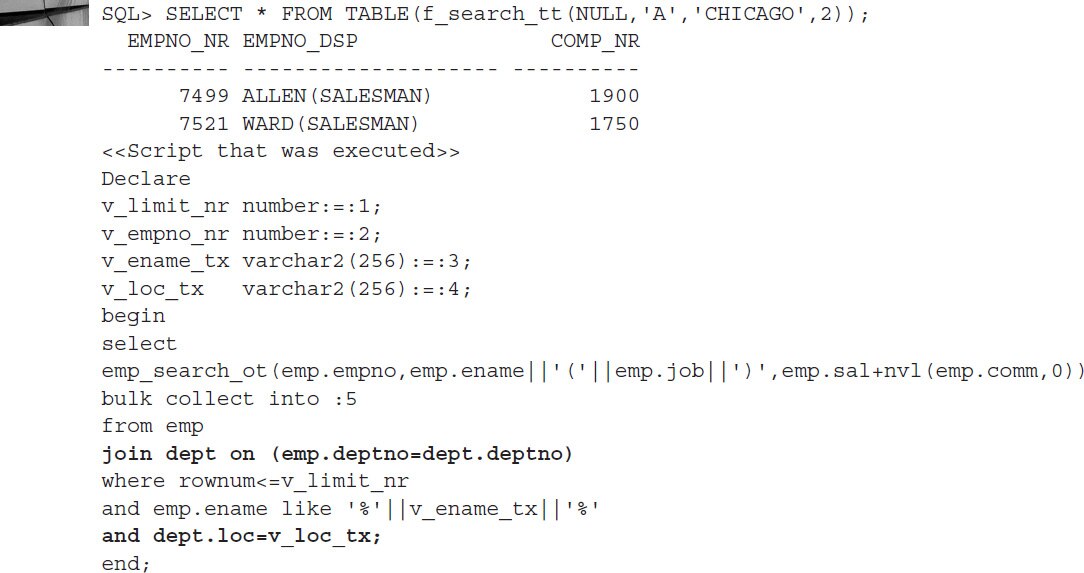
Now the join was built on-the-fly, exactly as specified and only when it was actually needed. This example illustrates the notion that the best tuning approach is to do nothing unless action is unavoidable. It also points out that constructing SQL statements dynamically can significantly shift the focus of all development efforts.
Instead of trying to find a universal solution, you can divide the task into a set of smaller subtasks and solve them one at a time. For example, depending upon the columns and tables involved, you can also add hints, change AND conditions to OR conditions, and so forth. As mentioned previously, you pay the price of overhead but gain a lot of flexibility, which can often be more important.
Leave a Reply