Scaling of existing software solutions is never a linear process. Contemporary database systems consume different kinds of resources (CPU time, memory, I/O channels) and behave differently when some of these resources become sparse. Considering that hardware is always limited by available budgets and technologies, it is critical to understand potential bottlenecks. Typically, this is accomplished by readjusting the technological process and utilizing what is readily available (or easier to expand) at the time.
The following example occurred when the total number of users in the existing system increased from 150 to 2500. The new hardware was adequately scaled up, and no one expected any significant performance changes. Contrary to expectations, users started to log a lot of issues with various modules suddenly slowing down. These issues were too sporadic to suspect anything wrong on the business logic side.
It definitely seemed like a case of “blaming the infrastructure.” But what part of the infrastructure? Normally, this type of problem is hard to solve, especially with the limited code instrumentation available. However, in this case, luck played a role—at about the same time, the DBAs noticed an abnormally high number of wait events associated with log file switches. This meant that the system was firing too many DML statements and the I/O mechanism of the server couldn’t handle them fast enough.
Of course, the conventional DBA wisdom to increase the size of the REDO logs would have mitigated the issue somewhat, but this approach would only serve as a temporary bandage. The unexpectedly high volume of log file switches had to have a valid explanation and a resolution needed to be found. Otherwise, this issue could recur later at inconvenient times.
The report by Oracle’s LogMiner showed that about 75 percent of generated log entries were related to operations against Global Temporary Tables (GTTs). That was a surprise because developers rarely associate UNDO/REDO operations with GTTs. In reality, if you have session-level GTTs (ON COMMIT PRESERVE), they are subject to transaction activities. This means that even though for such operations there is no COMMIT, there is a ROLLBACK:
- INSERT Very little UNDO is generated. To restore the table to the original state, it is enough to generate the DELETE entry using ROWID as a unique identifier.
- UPDATE As it does for the real table, Oracle needs to preserve the pre-DML state of the row.
- DELETE The entire row should be preserved to be restored if needed.
If you are doing a lot of UPDATE and DELETE operations against GTTs, you will generate lots of UNDO entries. Unfortunately, it is extremely difficult to improve the bandwidth of the I/O system for the existing server. You may get faster hard drives, but the total improvement would not be that dramatic. The solution was in the code itself.
Code review showed that all of the GTTs in question were parts of the ETL tool that took a relational representation of the data and converted it into a specific proprietary format, while GTTs were used as buffer storage in between.
The alternative was obvious. Object collections could serve the same role as long as there was enough memory. Adding more memory to modern servers is reasonably simple and cheap (compared with the cost of an I/O system upgrade). Management approved this approach, and the weight of the system was shifted.
The following is the simplified description of the solution. Imagine that you need to simulate a global temporary table that would look exactly like SCOTT.DEPT. First, you need an object type and corresponding object collection. You will also need a package where the local variable will be hosted:
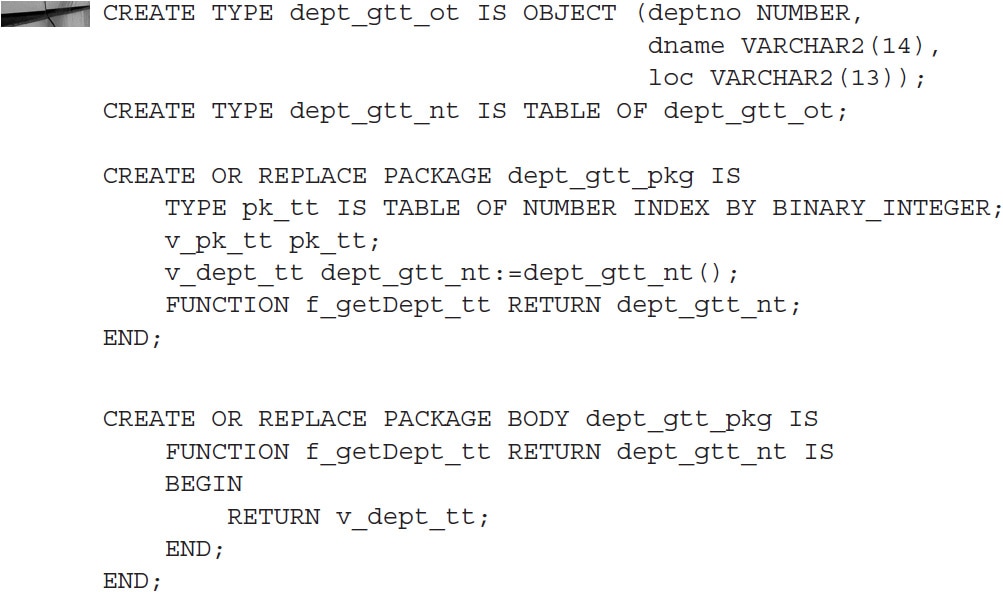
Note that the package also contains one more collection that serves as a logical primary key index lookup. This will be helpful for the purposes of data manipulation. The second step is to create a view, V_DEPT_GTT:
![]()
The view solves the problem of data retrieval. However, if you would like to manipulate the view directly instead of working with the package, you need the following INSTEAD OF trigger:
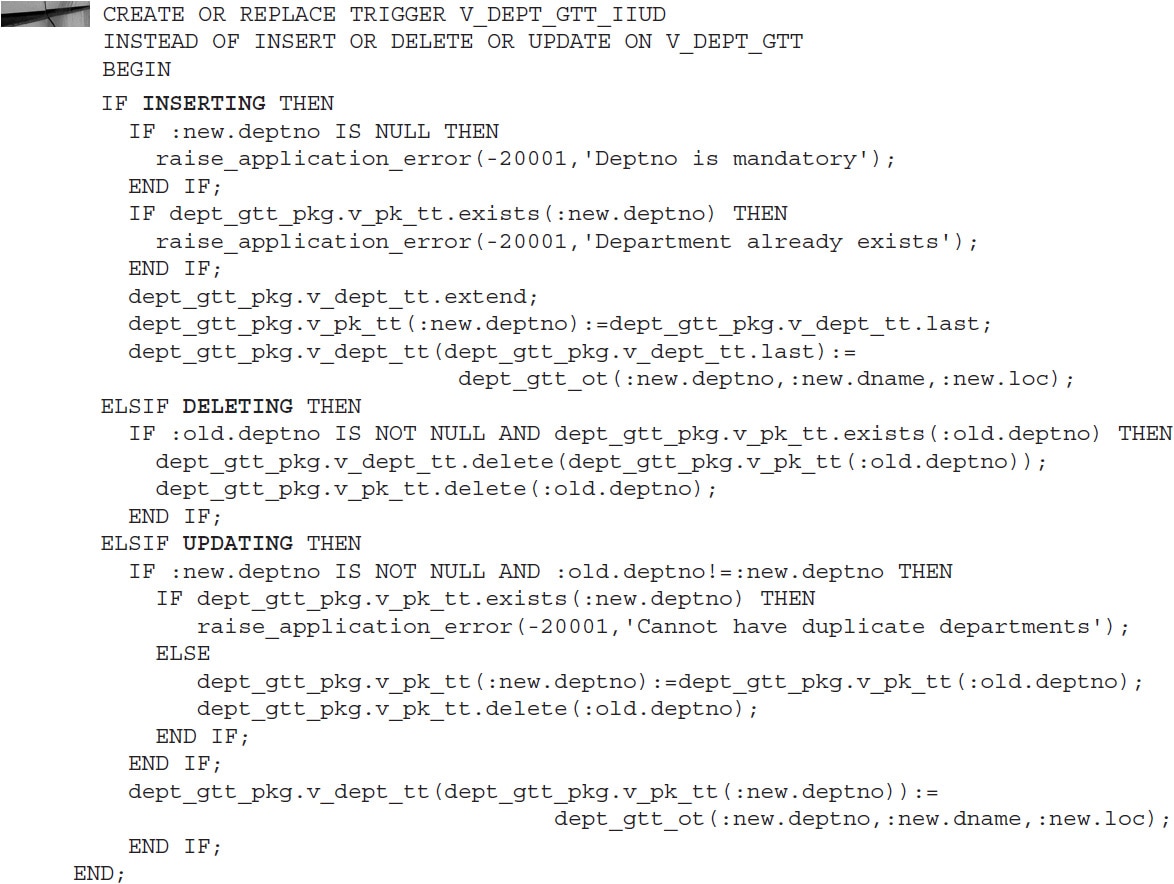
Now all elements are ready to simulate the GTT:

You have all of the DML operations and none of them generates any UNDO/REDO; however, a side effect is that they cannot be rolled back:
Obviously, under normal circumstances, DML statements against GTTs will be much faster than against this view, but such comparison is not fair. In a real-world situation, you may have hundreds of operations firing from hundreds of simultaneous users. In this case, the winning solution should keep the overall system performance adequate. Because the system was heavily I/O bound, it was acceptable to waste extra memory and extra time on the PL/SQL overhead. By spending less critical resources, you decrease the pressure on more critical ones. In this case, you slightly lengthen the total response time (0.3 sec instead of 0.25 sec), although no one would notice that difference. However, you do eliminate spikes of bad performance (15 sec instead of 0.25 sec every so often). In short, you make the system predictable, which is an important factor when managing the user experience.
NOTE:
The authors are aware of SQL recursion using CONNECT BY or Common Table Expressions. However, in some scenarios, PL/SQL recursion is the only option, such as where queries can mutate when going from level to level and Dynamic SQL is required to define what exactly needs to be fired. Another case is where you cannot hold a single cursor open for too long (because of the “snapshot too old” risk).
Leave a Reply