Note: This is Part 2 of a three-part article on SQL Server primary keys and clustered indexes.
The first article in this three-part series (Primary Key vs. Clustered Index: Maybe they should be different. Part 1) concentrated on the syntax for breaking apart the primary key and the clustered index. This article (Part 2) will look at performance and some benchmarking comparisons of the Primary Key and the Clustered Index being the same and different. The queries used in the following benchmark discussion came from stored procedures used in a real world business OLTP database.
A benchmark analysis of primary key vs. clustered index
The benchmark analysis concentrated on two separate, but related tables: Container and Package. All Package rows are related to a Container row (package.ContainerID = container.ContainerID) by a foreign key relation of package pointing to its parent row in Container. Thus, all packages have an equivalent container row, but also have parent rows (i.e., packages can also aggregate to sacks, pallets, shipments, etc.) as separate rows in the Container table. The Container table does contain a ParentContainerID column and has a foreign key constraint pointing to the ContainerID column.
The SQL Server benchmarking consisted of three separate definitions of the Primary Key and Clustered Key:
- Primary Key Clustered on ContainerID and PackageID for respective tables (both are identity columns).
- Primary Key non clustered and Unique Clustered on CreateDateKey* (natural key) and Identity column
- Primary Key non clustered and Unique Clustered on Identity column and CreateDateKey* (natural key)
*See CreateDateKey definition in Part 1 article.
Case 1 above defines the original definition within the database tables.
ALTER TABLE dbo.Container WITH CHECK ADD CONSTRAINT [PK_Container] PRIMARY KEY CLUSTERED (ContainerID) ALTER TABLE dbo.Package WITH CHECK ADD CONSTRAINT [PK_Package] PRIMARY KEY CLUSTERED (PackageID)
Case 2 breaks apart the Primary Key and has a separate Unique, Clustered index with selectivity on the natural key (CreateDateKey)
CREATE UNIQUE CLUSTERED INDEX CIDX_Container ON dbo.[Container](CreateDateKey, ContainerID); ALTER TABLE dbo.Container WITH CHECK ADD CONSTRAINT [PK_Container] PRIMARY KEY NONCLUSTERED (ContainerID); CREATE UNIQUE CLUSTERED INDEX CIDX_Package ON dbo.[Package](CreateDateKey, PackageID); ALTER TABLE dbo.Package WITH CHECK ADD CONSTRAINT [PK_Package] PRIMARY KEY NONCLUSTERED (PackageID);
Case 3 breaks apart the Primary Key and has a separate Unique, Clustered index with selectivity on the identity column.
CREATE UNIQUE CLUSTERED INDEX CIDX_Container ON dbo.[Container]( ContainerID ,CreateDateKey); ALTER TABLE dbo.Container WITH CHECK ADD CONSTRAINT [PK_Container] PRIMARY KEY NONCLUSTERED (ContainerID); CREATE UNIQUE CLUSTERED INDEX CIDX_Package ON dbo.[Package]( PackageID ,CreateDateKey); ALTER TABLE dbo.Package WITH CHECK ADD CONSTRAINT [PK_Package] PRIMARY KEY NONCLUSTERED (PackageID);
The reason for Case 3 is that most joins in the test database on these two tables use the identity column (Foreign Key) to relate the tables and there was concern that Case 2 might cause an additional table lookup.
A closer look at the query plans
OK, enough on the administrative details, let’s look at example queries with emphasis on their query plans and their statistics IO. Originally, we tested eight individual queries for all three cases, but most had similar results as Queries 1 and 3 below. All queries ran with “SET STATISTICS IO ON” and “Include Actual Query Plan” ON.
Example query 1:
SELECT c.ContainerID, p.PackageID, OrigPostalCode, c.ContainerTypeID, c.Description
FROM dbo.Package p
JOIN dbo.Container c
ON c.ContainerID = p.ContainerID
WHERE p.PackageID between 233439695 and 233647160
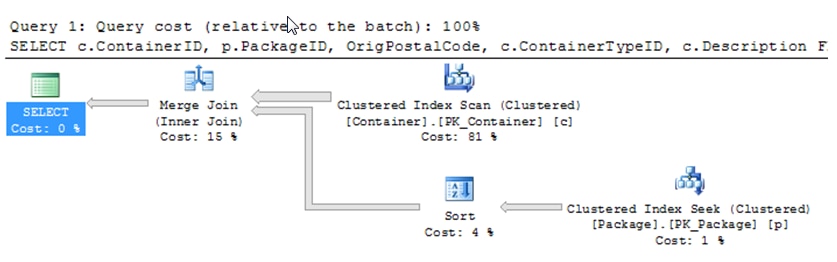
- Original PK (clustered on identity column):
Statistics IO: Table ‘Package’. Scan count 1, logical reads 2934, physical reads 8, read-ahead reads 2917.
Table ‘Container’. Scan count 1, logical reads 418197, physical reads 188, read-ahead reads 423482.
Query Plan for Query 1:
2. PK (NonClustered, Clustered on CreateDateKey, Identity column):
Statistics IO: Table ‘Package’. Scan count 5, logical reads 846903, physical reads 363, read-ahead reads 448.
Table ‘Container’. Scan count 0, logical reads 1496460, physical reads 376, read-ahead reads 344.
Query Plan:

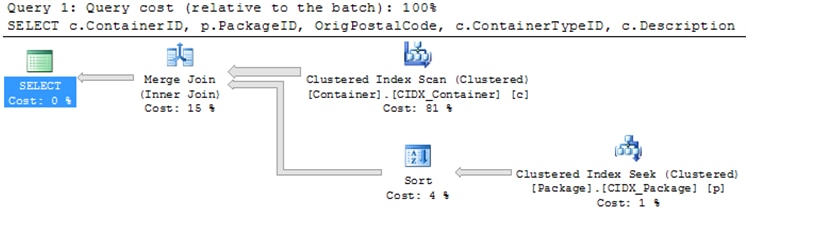
3. PK (NonClustered, Clustered on Identity column, CreateDateKey):
Statistics IO: Table ‘Package’. Scan count 1, logical reads 2936, physical reads 1, read-ahead reads 2925.
Table ‘Container’. Scan count 1, logical reads 418565, physical reads 18, read-ahead reads 423075.
Query Plan:
Discussion Query 1:
When comparing queries, the number of logical reads is usually the best choice. Physical reads can vary because of data caching. Note that the statistics IO and the query plans for Cases 1 and 3 are nearly identical. Case 2 has a Key Lookup causing a significant increase in IO reads (about double the logical reads). As noted earlier, the concern that basing the clustered index on the natural key first may cause SQL Server query performance issues is valid for most queries in this analysis.
Example query 2
SELECT c.ContainerID, p.PackageID, OrigPostalCode, c.ContainerTypeID, c.Description
FROM dbo.Package p
JOIN dbo.Container c
ON c.ContainerID = p.ContainerID
WHERE p.CreateDateKey = 20120601
- Original PK (clustered on identity column):
Statistics IO: Table ‘Package’. Scan count 1, logical reads 702935, physical reads 506, read-ahead reads 698652.
Table ‘Container’. Scan count 1, logical reads 418197, physical reads 52, read-ahead reads 631.
Query Plan:
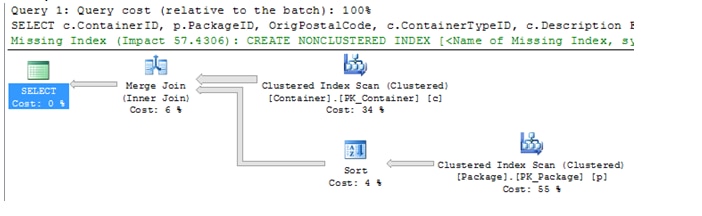
2. PK (NonClustered, Clustered on CreateDateKey, Identity column):
Statistics IO: Table ‘Package’. Scan count 1, logical reads 2936, physical reads 0, read-ahead reads 0.
Table ‘Container’. Scan count 0, logical reads 1478212, physical reads 0, read-ahead reads 0.
Query Plan (really bad – even after update statistics fullscan):
3. PK (NonClustered, Clustered on Identity column , CreateDateKey):
Statistics IO: Table ‘Package’. Scan count 5, logical reads 704154, physical reads 11495, read-ahead reads 261280.
Table ‘Container’. Scan count 207466, logical reads 888655, physical reads 0, read-ahead reads
Query Plan:
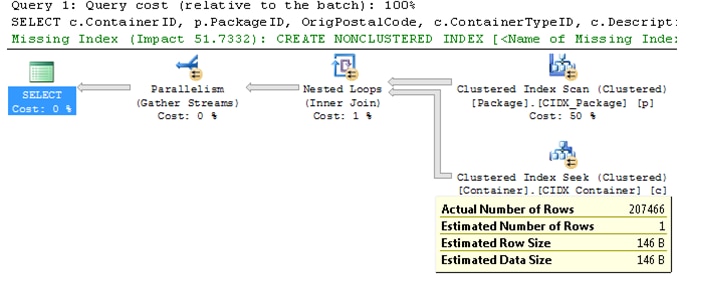
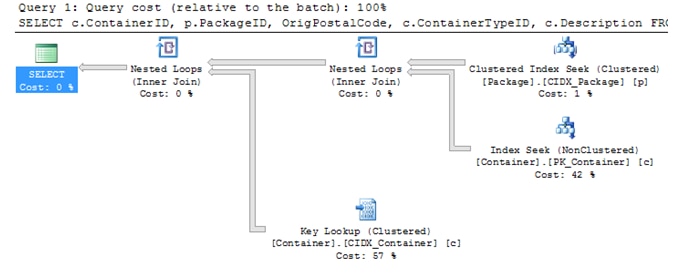
Note there is a recommended index for Cases 1 and 3:
CREATE NONCLUSTERED INDEX IDX_Package_CreateDateKey ON dbo.Package (CreateDateKey) INCLUDE (PackageID,ContainerID,OrigPostalCode)
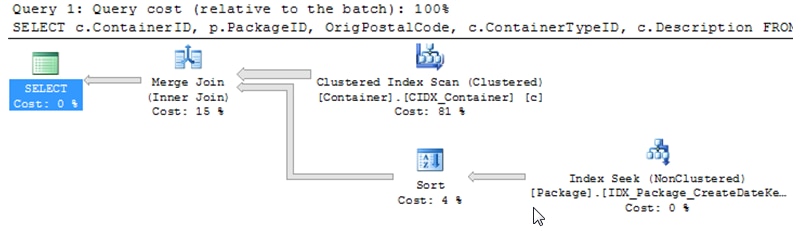
Implementing this index gives (for Case 3)
Statistics IO: Table ‘Package’. Scan count 1, logical reads 699, physical reads 0, read-ahead reads 0.
Table ‘Container’. Scan count 1, logical reads 418565, physical reads 69, read-ahead reads 420281.
Discussion Query 2:
The where clause in Query 2 uses the CreateDateKey as a means to select only a single days’ worth of package/container data. This query took advantage of the clustered index based on the CreateDateKey in the package table with an index seek on the clustered index (2936 logical reads), but still required a Key Lookup on the Container table because of the join criteria based on only the Primary Key (1478213 logical reads – had to hit container indexes twice). What troubles me though is that the query optimizer picked the wrong query plans for Query 1 and 3 (even with a fullscan update statistics). The query optimizer estimated that only one row from the PK_Container seek (actually it returned 207466 rows) and picked a inner join for both the PK_Container result set and the CIDX_Container result set. Inner joins in this context are not a good choice for those large result sets.
As noted for Queries 1 and 3, Management Studio suggested an index and the query plan above shows those results. As it turns out, for the three cases the latter case (with the suggested index) had the best overall performance (less disk reads).
Example query 3 (results representative of the remaining benchmark queries)
--csp_GetShipmentDetails
DECLARE @p_nContainerID int = 241949111
declare @nContainerCount int
declare @nPackageContainerType int
select @nPackageContainerType = ContainerTypeID FROM ContainerType
WHERE Description = 'Package' AND DelFlag = 'N';
WITH PackageContainerIDs (ContainerID, ContainerTypeID)
AS
( SELECT ContainerID, ContainerTypeID
FROM dbo.Container
WHERE ContainerID = @p_nContainerID
UNION ALL
SELECT c2.ContainerID, c2.ContainerTypeID
FROM dbo.Container c2
JOIN PackageContainerIDs p
ON p.ContainerID = c2.ParentContainerID
)
SELECT @nContainerCount = Count(*)
FROM PackageContainerIDs p
WHERE p.ContainerTypeID = @nPackageContainerType;
So is there a benefit to separating the primary key from the clustered index?
In most cases, it appears there is little if any reward for separating the Primary Key from the Clustered Index (although we did see one example where performance was better). And there could be some cons: additional index maintenance, key lookups, etc. If the natural key is the primary join mechanism to other tables, then separate Primary Keys and Clustered Indexes may be a viable choice. As usual the old Microsoft adage of “testing, testing, and more testing” is still applicable.
However, one case where breaking apart the Primary Key from the Clustered Index may be viable and that is in selecting a Partition Key for table partitioning. Part 3 of this discussion will dive into that.
Leave a Reply