NOTE: This three-part article series is based on a presentation originally given by Mike Byrd at SQL Saturday #234 on August 3, 2013; you can read Part 1 here and Part 2 here.
1. Data Warehouse Implementation Overview
This is the third and last part of a series on SQL Server Change Tracking and focuses on the code to implement a data warehouse from creation to actual change tracking ETL. There are links to several scripts at the end of this article and the discussion below will detail the contents of these scripts.
2. Data Warehouse Creation and Setup
The architecture design of the data warehouse was discussed in part 2 of this series. The code used to implement the data warehouse is discussed below. It is patterned after code implemented this last summer for a production database with a few changes per this author’s design philosophy. Not to say my way is right, but just represents code and procedural steps that I am comfortable with from data integrity and process maintainability (reliability) design.
It is recommended as you read this article, you also have a separate window open with the appropriate script for comparison and review.
2.1 Data Warehouse Creation (CT_Script1)
CT_Script1 creates a new database named AdventureWorksDW2012lite. It is patterned after the AdventureWorksDW202 database but with fewer tables, some table revisions, and a revised naming convention. It contains only one fact table – InternetSalesFact. Note the transformation of the original name from FactInternetSales to InternetSalesFact. This is a personal preference that the table function should come at the end of the name rather than the beginning.
As stated in Part 2 of this series, the source Primary Key was added to each of the tables referenced for change tracking. This allows immediate process flow to determine if an existing row is to be updated and a new row inserted. It also allows easier trouble-shooting of errors as well as an ETL restart capability in case of failure.
Originally my intent was to include all the tables within the original AdventureWorksDW2012 database, but there is almost no documentation for the table mappings from the OLTP AdventureWorks2012 database to AdventureWorksDW2012. Since the purpose of this entire series is to illustrate Change Tracking ETL, this author decided on a subset of data movement from the OLTP database to the new Data Warehouse.
Line 36 shows the creation of the ETL schema. As stated in Part 2, this schema is used to identify all tables and stored procedures used in the ETL process.
Dimension tables can be categorized as either slowly changing dimensions or current dimensions. The slowly changing dimensions are relatively static tables and in this design, were not candidates for change tracking. As shown in this script they include dbo.DateDim, dbo.ProductCategoryDim, dbo.ProductSubCategoryDim, dbo.SalesTerritoryDim, and dbo.GeographyDim. If the data needs to be revised for these tables, I generally use a one-time script to make the revisions. Note that in the population of dbo.SalesTerritory the key values of -1 (Not Assigned) and 0 (Not Applicable) are manually inserted (line 514). This is to allow Foreign Key Integrity during the data load if the SalesTerritory data reference is not found or known.
2.2 ETL Tables (CT_Script2)
This script adds the ETL tables and the extract tables (sometimes called staging tables) to the newly created AdventureWorks2012DWlite database. As stated earlier these use the ETL schema. These could have been put in a separate database, but for this instance and demonstration I put them in the target database.
The etl.ETL table (line 9) is used to track each instance of an ETL run. Note that it contains the StartDate, EndDate, CTCompleteFlag, ExtractCompleteFlag, LoadCompleteFlag, PreiousChangeVersion, and CurrentChangeVersion. If an ETL run is completed successfully then all columns are populated. If there are columns not populated, then either the previous ETL run is still executing or it errored out before it could populate the columns. The ETL_Admin stored procedure discussed below allows for a graceful restart.
The etl.SourceTable table (line 21) and its data population (line 33) script contains the source tables and their primary key columns needed for finding the change tracking data for each table identified for change tracking. It not only contains the parent tables, but any child tables needed for the data extract process. Its usage will be explained further down in the discussion about the etl.csp_GetChangedRecords in CT_Script4.
The etl.TargetTable table (line 58) and its data population (line 64) script contain the target tables for the CT etl process.
The etl.SourceTargetMapping table (line 77) and its data population (line 85) script contain the metadata needed to link the source tables (parent and child) to the target tables.
The etl.ETLSourceRecord table (line 107) is used to track the changed rows (from Change Tracking) between the current Version and the preceding Version. It contains Primary Key data for all parent and child source tables changed since the last preceding Version. Its use also becomes apparent in the etl.csp_GetChangedRecords discussion in CT_Script4.
The table etl.ETLSource table (line 121) is an admin table used during the ETL process.
The rest of the sql code in this script creates the extract (staging) tables as well as populating the dbo.PromotionDim table.
2.3 Data Warehouse Initial Data Load (CT_Script3)
This script populates (moves) the data from the AdventureWorks2012 database to the AdventureWorksDW2012lite database for the dbo.ProductDim, dbo.CustomerDim, and the dbo.InternetSalesFact tables (except for CustomerID 11566 for the CustomerDim and InternetSaleFact tables). This completes the population of all the tables in the AdventureWorksDW2012lite database except as noted. The reason for not bringing over this specific CustomerID was to provide an easy means to generate change data in the following demonstration scripts.
Note that the last SQL statement in this script also populates the etl.ETl table (to provide a starting point (initial data load complete) for the subsequent ETL process.
In a live, on-going system, you might have to snapshot the source database to provide a consistent initial data load source immediately followed by turning on change tracking. It is important to understand there may have to be a downtime between the initial data load and turning on change tracking for data consistency. If you are using a snapshot for the initial data load, this downtime is minimal. However, in any case, if you turn on change tracking first immediately followed by the initial data load, you should still get all the data, but the first ETL run would also pick up data changed during the initial data load. If you are using the primary source keys as demonstrated in the scripts herein, the data integrity should still be intact.
2.4 ETL CT and Extract Stored Procedures (CT_Script4)
etl.csp_GetChangedRecords (Line 1) is the heart of the CT methodology. This procedure finds all the parent/child table rows that have been modified since the last ETL instance and populates this data into the etl.ETLSourceRecord table. The corresponding extract stored procedures uses this data to populate the extract tables.
Dynamic SQL is necessary to access the Change Tracking functions in the AdventureWorks2012 database as well as using the 2 metadata tables (etl.Source Table and elt.SourceTableMapping) identifying the source tables and their parent/child relationships. Note the last step in this stored procedure is to set the CTCompleteFlag to ‘Y’.
Following this stored procedure are the three extract procedures: etl.csp_CustomerDimExtract, etl.csp_ProductDimExtract, and etl.csp_InternetSalesExtract. All are similar in construct as first the Primary Key for the parent table is identified for all parent/child changed data, duplicates are removed, and then data moved to the appropriate extract table. Note that in csp_CustomerDimExtract, XML SQL is used to extract specific data from the source xml column.
Following the extract procedures are the 3 load procedures (starting at line 753). These are also similar in construct with each using a MERGE statement with the Parent Table Primary Key as the deciding point on whether the operation is an insert or update. Although not present in this code, the load stored procedures are usually where I aggregate any counts or totals.
2.5 CT Database and Table Implementation (CT_Script5)
As stated in Part 1, Snapshot Isolation is recommended to Change Tracking . This is shown in Line 5 of this script. Usually, but not necessarily required, I also set READ_COMMITTED_SNAPSHOT On also.
The sql code to turn on database Change Tracking is shown at Line 22. There are two parameters here that need further discussion: CHANGE_RETENTION and AUTO_CLEANUP. If AUTO_CLEANUP is set to OFF, then the CHANGE_RETENTION parameter has no meaning. If you allowed the database to retain the change tracking data, the database would grow mysteriously (since the CT tables are hidden) and eventually use up a considerable amount of disk space. Therefore, when AUTO_CLEANUP is set to ON, SQL Server looks at the CHANGE_RETENTION parameter and essentially does garbage collection based on the retention criteria. The defaults are two days for CHANGE_RETENTION and AUTO_CLEANUP ON.
Your ETL process needs to be scheduled more frequently than the CHANGE_RETENTION period. In the current CT process I have in production we are running CT ETL every 5 minutes with data retention of 2 days. Should we have a failure we need to get a fix in before the retention period is up and we may lose change tracking data and that would require another initial data load. The CHANGE_RETENTION PERIOD can be easily changed through either SSMS or a TSQL script:
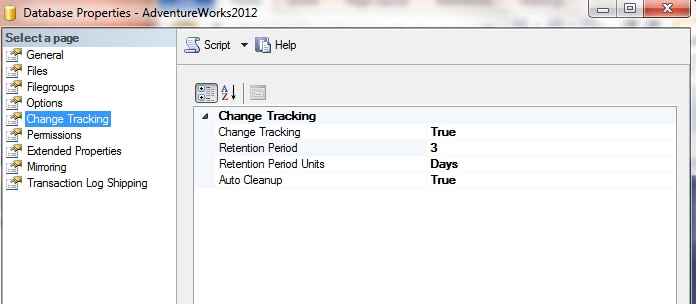
Or:
USE [master] GO ALTER DATABASE [AdventureWorks2012] SET CHANGE_TRACKING (CHANGE_RETENTION = 3 DAYS) GO
where the CHANGE_RETENTION was changed from 2 days to 3 days.
The key here is to have a well-planned and reliable alert system to let you know when an ETL job has failed.
The remaining code turns on CT for the applicable tables (both parent and child). Note the commented out code at the bottom of the script. Immediately after turning on change tracking for the first time the VERSION is zero. However, if you subsequently turn off change tracking for the database and later re-enable it, the VERSION will be the last one prior to the turn off. This author has found no way to reset the VERSION back to zero except by creating a whole new database.
OK, the AdventureWorksDW2012lite database has now been created with initial data load and added etl schema tables and stored procedure. In addition, Change Tracking has been en-abled.
2.6 CT Data Modification (CT_Script6)
As you may recollect, all the CustomerDim and InternetSalesFact data were loaded except for CustomerID = 11566. This script modifies the data in the AdventureWorks2012 OLTP database by updating the ModifiedDate column. The two SELECT statements at the bottom of the code (Line 17( show the affected rows identified by the Primary Key. This script is used to modify source data for the subsequent demo.
2.7 Pre-CT Data Check (CT_Script7)
This script is used to check data in the applicable tables. It will be used again once a ETL job is completed to ensure the data has been transferred over for CustomerID = 11665. I recommend having two tabs open with this script. In one tab you run the script before CT_Script8 and the other tab you run it after execution of CT_Script8. This allows easy examination of before and after data in the affected tables.
2.8 ETL Admin Stored Procedure (CT_Script8)
This stored procedure is the heart of the entire ETL job. It calls the CT stored procedure, calls the extract stored procedures, and finally calls the applicable load stored procedures as well as performing all the admin functions to ensure a stable, reliable ETL job.
The first TSQL code (lines 29-37) checks to ensure the ETL is not running from a previous job. Obviously you don’t want two ETL jobs running at the same time (Lines 29-37). Then the previous VERSION is obtained where the job at least finished the CTComplete step. Additionally the current VERSION is obtained to bound (only get data created before the start of the ETL job; get data created/changed during job in next ETL) the data collection. If there has been no data modification since last ETL, then obviously you would want to stop the current ETL job with a success as shown in Lines 53-62.
The call to csp_GetChangedRecords (line 73) finds all the parent/child records changed since the last ETL. As discussed earlier, this procedure uses Change Tracking to its fullest and is the primary building block in the Extract process.
The subsequent calls to csp_CustomerDimExtract, csp_ProductDimExtract, and csp_InternetSalesFactExtract load the staging tables (lines 76-80). Note that the CTFlag is marked Complete in etl.ETL table. This can only occur (with the Begin Try/Catch logic) if all the extract procedures are successful.
Then the Load procedures (lines 92-96) csp_CustomerDimLoad, csp_ProductDimLoad, and csp_InternetSalesFactLoad are executed for the data load into the respective tables. Following this is admin logic to complete the administrative care-taking of the etl.ETL table with the LoadCompleteFlag set and the EndDate set.
If you add more tables for the ETL process this Admin procedure would grow, but the logic would remain the same.
2.9 CT Demo
Now that all the scripts have been explained, let’s try a demo of moving change data from the source tables to the data warehouse tables.
First you need the AdventureWorks2012 database. This can be obtained at http://msftdbprodsamples.codeplex.com/releases/view/93587.
Then run CT_Script1 to create AdventureWorks2012DWLite database, its tables, and data load for the static tables.
CT_Script2 adds the ETL staging tables, stored procedures and completes data load for a few extra static tables.
CT_Script3 completes the data load for the identified CT tables of CustomerDim, ProductDim, and InternetSaleFact tables (except for customerID = 11566) as well as creates initial row in etl.ETL table.
CT_Script4 then adds the remaining ETL stored procedures for ChangedRecords, Extracts, and Loads for the appropriate table.
CT_Script5 turns on Change Tracking for the AdventureWorks2012 database. If you run (after running CT_Script5) on the AdventureWorks2012 database:
SELECT change_tracking_current_version() [Version]
you will get
Version
0
CT-Script6 “changes” the modifieddate for the records in Sales.Customer and Sales.SalesOrderHeader for CutomerID = 11566. Note the results from the queries (at the end of this script):
SELECT * FROM CHANGETABLE (CHANGES Sales.Customer,0) as CT ORDER BY SYS_CHANGE_VERSION; SELECT * FROM CHANGETABLE (CHANGES Sales.SalesOrderHeader,0) as CT ORDER BY SYS_CHANGE_VERSION;
CT_Script7 should be run before and after CT_Script8 noting changes in the affected tables. Notice before running CT_Script8 that the queries return empty result sets.
CT_Script8 loads the sproc (slightly revised for demo, lines 105-107 are commented out for rerun of CT_Script7) csp_ETLAdmin and then executes it.
Please carefully inspect the results of the rerun of CT_Script7. The ProductDimExtract table has an empty return set (no changes were made to Production.Product table). Changes are shown for the etl.CustomerDimExtract and etl.InternetSalesFactExtract tables and well as now we have results for the Data Warehouse table dbo.CustomerDim and dbo.InternetSalesFact tables. Also note the new second row in the etl.ETL table.
3.0 CT ETL Design Summary
Hopefully I’ve given the reader something to think about. Data Warehouse design and architecture is not something you just sit and do. It requires considerable insight into the source data and the target data. What is described above is an approach to getting data from source to target. It may not be the best approach, but it works for the cases I’ve implemented with minimal DBA care-taking.
While these scripts are fairly inclusive for a real-world implementation, they still need additional logic for reporting failures (I recommend some sort of email alerting to the appropriate personnel).
Any questions and/or comments are welcome.
Any way to get CT_Script1 through CT_Script8? The links seem to be broken.
All the links to the scripts say Forbidden. Any chance of fixing them?
Thanks,
Hi … Still wondering about the scripts. All still say Forbidden.
Great articles & thank you for putting them together !
As stated above – all links terminate in a 503 error page. Nice article but not much use without those scripts
Yes all Scripts sat forbidden. Can you please fix
All script links are errored out? can i please get those scripts?
So here we are more than two years down the line and the scripts are still forbidden. Is anyone listening? I think we know that answer…
All, I just saw this – sorry, we had a change of personnel and this slipped in a crack. Thanks for raising your hand again.
I’ll reach out to Mike and see if I can get the scripts made available.
Hey, links are fixed for the scripts!