NOTE: This three-part article series is based on a presentation originally given by Mike Byrd at SQL Saturday #234 on August 3, 2013; you can read Part 1 here.
1. ETL/data warehouse design overview
This is Part 2 of a three-part series on SQL Server Change Tracking (CT) and this article concentrates mainly on the concept of moving data from a SQL Server data source to a data warehouse or data mart. There are many ways to do this – some good, some bad, but the design methodology I’m presenting here works. I’m not claiming it’s the best, but it’s is in production with minimal maintenance needs.
Usually a data warehouse is designed with the primary emphasis on getting data back out in a meaningful manner (reports, graphs, etc.). It is not unusual for the ETL process to be an after-thought. The emphasis here will be on getting data in-– efficiently, with relatively good performance, and ensuring data integrity.
2. CT ETL cesign considerations
Data integrity is probably the most important attribute for an ETL process. Without that, there is little trust in the data and its reports from the data warehouse. The approach contained herein places major emphasis on data integrity from the source database(s).
2.1 Potential CT data integrity issue
Prior to the change tracking functionality (as described in Part 1 of this series), frequently the ETL designer used a datetime and/or a combination of datetime and last primary key to identify changed rows in the source database. By tracking the last datetime an ETL process was run, any changed rows between then and the start of the ETL process could be identified. However, it has been this author’s experience that this is not perfect. It is possible for a set operation (update or insert) to be in process at the start of the ETL process, but not yet committed, and some rows within the source database are missed using datetime as the change parameter.
Change Tracking swings the pendulum the other direction. Since Change Tracking is synchronized with the transaction log, only committed rows are identified by the Version. By tracking the previous version (as shown in Part 3 of this series), all rows are eventually selected. The only fallacy here is that it is possible to pick up some rows (particularly where there are parent/child tables) that have already been committed but with a later version number. Consider the following example (tables from Part 1 of this series).
?
Suppose you have following update operation underway:

and under a separate SPID you get the current Version:
![]()
where @Current_etl_version has the value of 100.
Now the UPDATE statement completes and the new Version is 101. Any row that had been inserted and/or updated between the previous etl version and the current etl version (100) would have the modified data for Version 101; this data would be picked up in the current extract process. The next time an ETL process is performed that row would be identified as a change row and the extract would pick it up (a second time). This is not necessarily bad, but just needs to be known as a possible kink in the armor. This potential data issue could be overcome with a read-only snapshot of the source database if this causes concern. At one of my current consulting sites, we run the CT ETL process every 5 minutes and this has not caused an issue to date.
2.2 ETL: Which process to use
There are a variety of tools to use for ETL. I’ve used Informatica, SSIS, and T-SQL. Since I am most familiar with T-SQL, that is my tool of choice. While there are pluses and minuses for each of these tools (and others not mentioned), you usually choose the option best suited for the personnel you have available. Other considerations used in the selection include cost (licensing), time allocated to complete, and personnel available to maintain. While SSIS doesn’t have an inherent cost, if your staff doesn’t have a “SSIS expert”, the implementation and maintenance of a SSIS solution should be a consideration.
2.3 Target table design
There are many ways to implement a data load process, but the safest one I’ve found is to embed in the target table the source primary key of the data (in the case where there are parent/child tables in the source extract, I normally use just the parent source primary key). There are a variety of reasons for doing so. First by having the parent source primary key, the load process can easily identify if the data for that row has already been inserted or if it just needs updating. The MERGE operator is perfect for this application. Another reason is to restart the ETL process if there is a failure of some sort. You don’t want to insert a duplicate row if it is already there. By having the source Primary Key embedded in the target table, you can easily prevent duplicate data. Consider a revised version of the AdventureWorksDW2012 below:
?
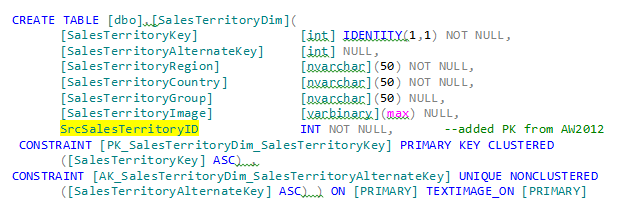
As highlighted in yellow I’ve add the SrcSalesTerritoryID from the AdventureWorks2012 OLTP database.
Yes, CT does give you an indication of whether a row is inserted, updated, or deleted, but I’ve found for ETL restarts after an ETL failure, the Source Primary Key provides the most reliable option. Having said that, I still tend to carry in the staging tables the change operation value (I, U, D) for debugging purposes.
2.4 Staging tables
Typically staging tables are exact representations of the extract process. I’ve modified them somewhat to also include any source foreign key references (in the target database) to assist in identifying the target table foreign key values. I also tend to perform data modifications (other than aggregations) during the extract process. For example, consider the staging table and extract stored procedure below (these will be available for download in part 3 of this series – these are shown below for illustrative purposes):
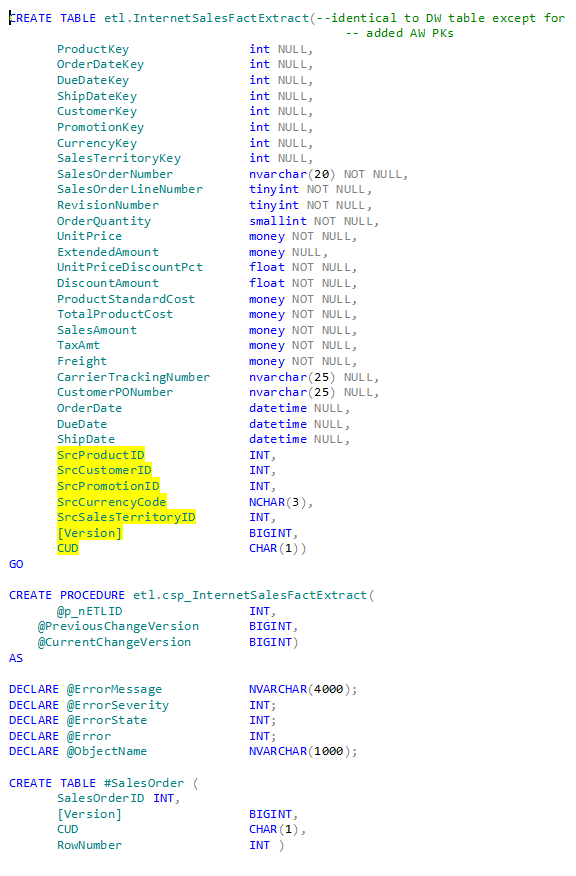



Note that the staging table is almost an exact duplicate of the target table except with the addition of the applicable source primary keys (for identifying the DW primary keys), the Version, and the CUD columns (all highlighted in yellow). The Version and CUD columns were used in the initial design and debugging. They are currently not being used, but would be useful for trouble-shooting an ETL failure. The CUD (Create/Update/Delete) column identifies the operation identified by CT.
In the extract stored procedure the first primary operation is to identify the changed rows applicable to the parent table. In this case if a child table row is modified, then we need to identify the parent table primary key for the actual data extract. In each of the SELECT statements you will see a join to ETLSourceRecord table. This table contains all the changed parent/child table Primary Keys since the last update. I’ll save the scripting and how this is accomplished for Part 3.
The second set of code then identifies and deletes any duplicates identified by the first operation. This could easily be the case when a parent table row and its child table rows are created and/or updated.
In the actual data extract we do not have the target table Foreign Keys yet, so their values are set to NULL. These will be updated in the load procedure (Part 3).
However, we can identify the target table DateKeys because of the design of our DateDim table in the target database. The Primary Key for the DateDim table is an integer of the form yyyymmdd. Thus the determination of the DateKey can easily be accommodated with the CONVERT function using the 112 formatting option.
2.5 CT ETL tables location
Questions abound about having the OLTP and DW on the same server. In the one system that I’ve implemented CT they were on the same server. Yes, it is a hefty server and we are watching performance closely, but so far no significant performance hits. If separate servers are needed for the OLTP (source) database and the DW, then a read-only snapshot of the source DB on the warehouse server would provide what is needed for the ETL as described herein.
Choices about where to put the CT ETL tables and stored procedures include the source server, the target server, or a separate server. Each has its pros and cons, but our design decision was to put the ETL tables and stored procedures on the target server and in the target database, but under a separate schema:
![]()
This seems to have worked well, except the Change Tracking functions are on the source database. To access them we used dynamic SQL as shown below:
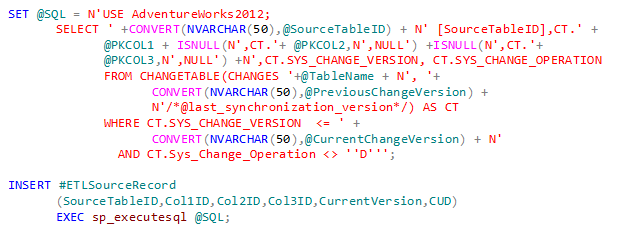
We had to use dynamic SQL to get the current Version since we are calling the source CHANGETABLE function from the Target database. The above query is parameterized and will be discussed further in Part 3.
If you have to use a Snapshot on the Target server, the CT values and functions are carried over quite nicely.
2.6 CT data delete
The DELETE aspect of Change Tracking is not included in the scripts by design. Rarely are there data deletes in the OLTP database and those that occur are due primarily to data archival and purging. Therefore, the DELETE functionality of CT is not part of this ETL design.
2.7 CT sources
While it should be obvious, Change Tracking is only valid when the source is SQL Server 2008 or later database. It does not work for any other databases and/or flat file sources. If you need data from another source, then CT is not the answer.
3.0 CT ETL design summary
Hopefully I’ve given the reader something to think about. Data Warehouse design and architecture is not something you just sit and do. It requires considerable insight into the source data and the target data. What is described above is an approach to getting data from source to target. It may not be the best approach, but it works for the cases I’ve implemented with minimal DBA care-taking. Part 3 of this series is mainly a series of scripts defining a modified AdventureWorksDW2012 database with CT as the impetus for the ETL. Stay tuned, these scripts are clones of a real-world implementation currently in production.
[…] Read Part 2: ETL and data warehouse design considerations here […]