NOTE: This three-part article series is based on a presentation originally given by Mike Byrd at SQL Saturday #234 on August 3, 2013.
1. Introduction to Change Tracking
This multi-part series will concentrate primarily on the Extract portion of the data extraction, transformation, and loading (ETL) process using SQL Server Change Tracking (CT). The second part will concentrate more on design architecture with CT, and the last part also touch on the Translate and Load portions as well as a near-real world example using the AdventureWorks2012 database. This segment will introduce the concept of CT as well as provide a substantive demo (i.e., something better than a hello world example) of CT’s functionality.
CT was introduced with SQL Server 2008R2 and unlike Change Data Capture (CDC) is available for all versions of SQL Server 2008 (and later) including SQL Server Express. CT captures changes to database table rows over a period of time. It does not record each change during that period, but retains the net changes by tracking the individual rows (using the Primary Key) that have changed. Thus, it is great for data extraction/synchronization, but not for auditing (that is CDC’s area of expertise).
2. ChangeTracking Overview
CT is first enabled at the database level. This creates an internal (hidden) table that tracks the CT version. Version can be thought of as a BIGINT identity database variable that is monotonically increasing and increments by one for each DDM (database data modification) set operation in the Transaction Log. It is synchronous with the database Transaction Log and performance effect is minimal. If you enable a database for CT, do some data modifications (on tables selected for CT), disable the database, then re-enable it,. The version will pick up the last value it had when the database was disabled. Version is database wide and not tied to any table.
Then, each table of interest within the database must be enabled with CT. Enabling a table creates additional internal (hidden) table (change_tracking_objectID) to track net row changes as well as some other data to be discussed below. Any table selected for CT must have a Primary Key. The Primary Key can be multi-column, but the Primary Key’s uniqueness is what allows CT to identity the modified rows.
2.1 CT Functions
Since all the CT generated tables are internal tables, Microsoft generated a series of functions to access the data within the tables.
The CHANGETABLE function is the most important and most used. The ChangeTable function has two parameters: the first parameter has the value of “CHANGES” or “VERSION”. The second parameter differs on the value of the first parameter. If the first parameter is “CHANGES”, then the second parameter is <PreviousSyncVersion> (a BIGINT integer denoting the last time an ETL or data synchronization was run). If the first parameter is “VERSION”, then the second parameter(s) are the Primary Key values. I always use the “CHANGES” parameter and track the previous ETL version with a value in a user table. An example of this function is:
![]()
where the first parameter is “CHANGES” followed by the table name and the second parameter is the previous version (last ETL or synchronization) value. In this case zero would be the last ETL version number. The result set would look something like:
| SYS_CHANGE_ VERSION | SYS_CHANGE_ CREATION_VERSION | SYS_CHANGE_ OPERATION | SYS_CHANGE_ COLUMNS | SYS_CHANGE_ CONTEXT | PersonID | AttributeID |
|
2 |
2 |
I | NULL | NULL |
4 |
1 |
|
2 |
2 |
I | NULL | NULL |
4 |
2 |
|
2 |
2 |
I | NULL | NULL |
4 |
3 |
|
2 |
2 |
I | NULL | NULL |
4 |
4 |
where:
- SYS_CHANGE_VERSION is the latest Version for that row’s last modification.
- SYS_CHANGE_CREATION_VERSION is the Version for the row when it is created (inserted, if the row was inserted since the last ETL Version, 0 in this example).
- SYS_CHANGE_OPERATION can have the values of I, U, or D. However, if the row was inserted since the last ETL version (0 in this instance), the value is I even if there are subsequent update row modifications.
- SYS_CHANGE_COLUMNS is a binary value indicating all columns changed since last ETL version. This will be discussed in the sequent demo discussion.
- SYS_CHANGE_CONTEXT is used if you want to track which applications made the row modification.
- PersonID and AttributeID are the Primary Key columns for this table and the values below them are the Primary Key Values for the rows modified
- SYS_CHANGE_COLUMNS and SYS_CHANGE_CONTEXT are rarely used for ETL implementations.
The next most important function is CHANGE_TRACKING_CURRENT_VERSION. This returns the current version after the last committed transaction at the database level. This value is used for the upper (last) value of VERSION for determining the rows that have been modified. Note that is not table dependent and is database wide. An example would be:
![]()
with a result set like:
| (No column name) |
|
5 |
where 5 is the current database version.
The next function is CHANGE_TRACKING_MIN_VALID_VERSION; it returns the minimum version for a specified table. An example is:
![]()
with results like:
| (No column name) |
|
2 |
The last two functions are CHANGE_TRACKING_IS_COLUMN_IN_MASK (used when tracking data for changed columns) and WITH CHANGE_TRACKING_CONTEXT (can differentiate the changes being done by your own application compared to others). These two columns are generally not needed in an ETL implementation, but the demo below will show an example of how CHANGE_TRACKING_IS_COLUMN_IN_MASK can be used to identify which columns are changed. You can find out more about WITH CHANGE_TRACKING_CONTEXT with your friend Google or Bing.
2.2 Enabling Change Tracking
First the database must be enabled. This can be done from a script (as shown below) or from SQL Server Management Studio (SSMS). Right click on database name, select Properties, then select Change Tracking:
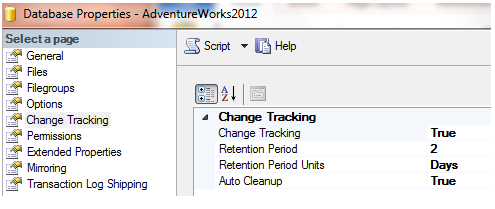
A cleaner way to do this is via script, as shown below:

Note that you specify the database name (CT_Demo in this instance) and that there are two primary functions that are specified: one is the Retention Period (the default is two days); the second is the Auto Cleanup – sort of like a garbage collection. If Auto Cleanup is set to OFF, the hidden tables for CT will grow and eventually fill up your hard drive. It is wise to setup Auto Cleanup to True with a reasonable Retention Period. Microsoft Books On Line states the following about data retention:
The change retention value specifies the time period for which change tracking information is kept. Change tracking information that is older than this time period is removed periodically. When you are setting this value, you should consider how often applications will synchronize with the tables in the database. The specified retention period must be at least as long as the maximum time period between synchronizations. If an application obtains changes at longer intervals, the results that are returned might be incorrect because some of the change information has probably been removed. To avoid obtaining incorrect results, an application can use the CHANGE_TRACKING_MIN_VALID_VERSION system function to determine whether the interval between synchronizations has been too long.
If you fail to do a synchronization within the data retention period, you will probably have to do a full data load (again). It is important in your Disaster Recovery procedures to have some means to prevent data loss due to Auto Cleanup. It is also important in normal day-to-day operations to have a reasonable/workable data retention value to prevent unnecessary and hidden database growth.
Next, you must enable CT for each applicable table. Not all tables need change tracking, for example, lookup tables rarely change and could be manually updated as required. As with the database, table CT can be enabled via SSMS or script. I prefer scripting, but both are shown below:
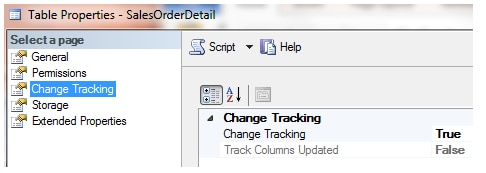
The Change Tracking functionality is True or False and The Track Columns Update is also True or False. Generally for most ETLs, the Track Columns Updated is left to the default of False. An example of its usage is shown later in the script demo. The script to enable a table for CT is:
![]()
The enable scripts takes almost no time and have minimal performance impact.
2.3 Demo Setup
CT_Demo_Script 1 creates the CT_Demo database as well as 3 tables: dbo.Person, dbo.Attribute, and dbo.PersonAttribute. It also populates all 3 tables with test data.
CT_Demo_Script 2 enables Snapshot Isolation and Change Tracking. This is necessary for change tracking to provide consistency in its results. If your hardware is properly sized for its database(s), I’ve found minimal effect on database performance. Script 2 also enables the database for CT and also two tables: dbo.Person and dbo.PersonAttribute. This is shown below just to show how simple the commands are and they run in unmeasureable duration:
If we run the following query before enabling the database Change Tracking:
![]()
Then we get null result set. But after running the following:
Then we get a 0 for a result set (this is initial value before any data modifications).
We also now need to enable CT for dbo.Person and dbo.PersonAttribute tables as shown below:

Rerunning ![]() still yields a zero for the current version (there have been no data modifications).
still yields a zero for the current version (there have been no data modifications).
CT_Demo_Script3 contains the rest of the query examples below.
So now if we add one row to the Person table (yes, Sandra Bullock has a house in Austin):
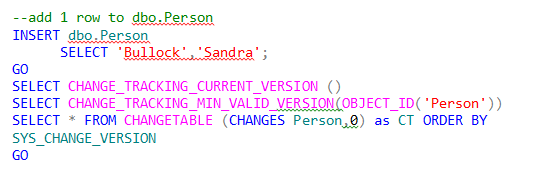
Then we get:
| (No column name) | |||||
|
1 |
|||||
| (No column name) | |||||
|
0 |
|||||
| SYS_CHANGE_ VERSION | SYS_CHANGE_ CREATION_VERSION | SYS_CHANGE_ OPERATION | SYS_CHANGE_ COLUMNS | SYS_CHANGE_ CONTEXT | PersonID |
|
1 |
1 |
I | NULL | NULL |
4 |
Now if we give Sandra Bullock some attributes and run the same three queries (only now looking at the table dbo.PersonAttribute) as shown below:
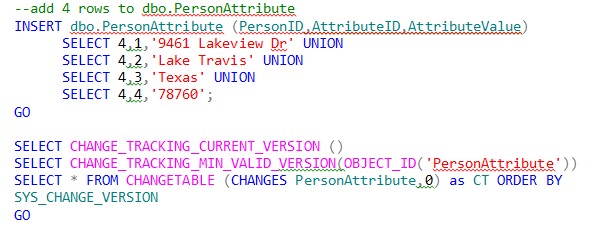
Then we get:
| (No column name) | ||||||
|
2 |
||||||
| (No column name) | ||||||
|
0 |
||||||
| SYS_CHANGE_ VERSION | SYS_CHANGE_ CREATION_VERSION | SYS_CHANGE_ OPERATION | SYS_CHANGE_ COLUMNS | SYS_CHANGE_ CONTEXT | PersonID | AttributeID |
|
2 |
2 |
I | NULL | NULL |
4 |
1 |
|
2 |
2 |
I | NULL | NULL |
4 |
2 |
|
2 |
2 |
I | NULL | NULL |
4 |
3 |
|
2 |
2 |
I | NULL | NULL |
4 |
4 |
Note that the current version is 2, but the min version (for dbo.PersonAttribute) is still 0.
Now we go back and update the state attribute from ‘Texas’ to ‘TX’ with the same after queries:
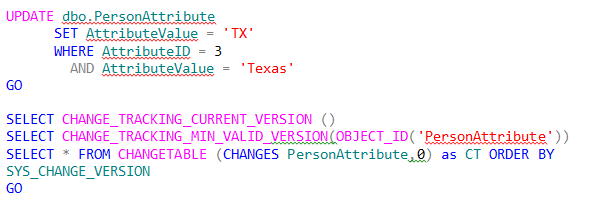
This yields:
| (No column name) | ||||||
|
3 |
||||||
| (No column name) | ||||||
|
0 |
||||||
| SYS_CHANGE_ VERSION | SYS_CHANGE_ CREATION_VERSION | SYS_CHANGE_ OPERATION | SYS_CHANGE_ COLUMNS | SYS_CHANGE_ CONTEXT | PersonID | AttributeID |
|
2 |
2 |
I | NULL | NULL |
4 |
1 |
|
2 |
2 |
I | NULL | NULL |
4 |
2 |
|
2 |
2 |
I | NULL | NULL |
4 |
4 |
|
3 |
2 |
I | NULL | NULL |
4 |
3 |
The state attribute has now changed to version 3. Also note that the SYS_CHANGE_OPERATION is still has ‘I’ and the creation version is still 2.
If we re-run the last query above, but with a last synchronization value of 2, we get the following:
| SYS_CHANGE_ VERSION | SYS_CHANGE_ CREATION_VERSION | SYS_CHANGE_ OPERATION | SYS_CHANGE_ COLUMNS | SYS_CHANGE_ CONTEXT | PersonID | AttributeID |
|
3 |
NULL | U | NULL | NULL |
4 |
3 |
Note also that the Creation_Version and Operation have changed.
From a more practical use, the second attribute in the CHANGETABLE function should be defined as a parameter (@last_etl_version) that is tracked for each ETL (this will be better illustrated in a later part of this series).

Rewriting the query slightly and modifying another row, we get:
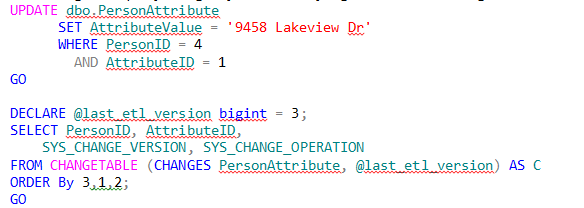
| PersonID | AttributeID | SYS_CHANGE_ VERSION | SYS_CHANGE_ OPERATION |
|
4 |
1 |
4 |
U |
Joining the CHANGETABLE function back to the database table we get:
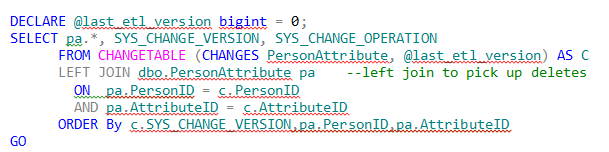
| PersonID | AttributeID | AttributeValue | SYS_CHANGE_ VERSION | SYS_CHANGE_ OPERATION |
|
4 |
2 |
Lake Travis |
2 |
I |
|
4 |
4 |
78760 |
2 |
I |
|
4 |
3 |
TX |
3 |
I |
|
4 |
1 |
9458 Lakeview Dr |
4 |
I |
where AttributeValue is the current (net) data value for that column.
As a last example, let’s consider the option of TRACK_COLUMNS_UPDATE attribute where it is TRUE. I could not find a way of doing this on the fly (even in SSMS), so I generated the following script:
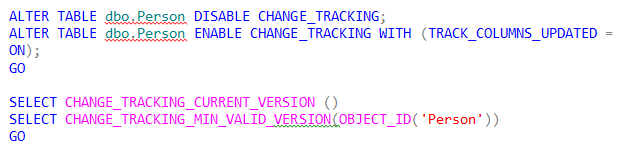
| (No column name) |
|
4 |
| (No column name) |
|
4 |
Now the minimum version is 4 for the Person table. If we update the Person table and rewrite our query to take advantage of Track_Columns_Updated we get:

| SYS_CHANGE_ VERSION | SYS_CHANGE_ CREATION_ VERSION | SYS_ CHANGE_ OPERATION | SYS_CHANGE_COLUMNS | SYS_CHANGE_ CONTEXT | PersonID |
|
5 |
NULL | U | 0x0000000003000000 | NULL |
3 |
| PersonID | SYS_CHANGE_ OPERATION | FirstName | LastName | FirstName Changed? | LastName Changed? |
|
3 |
U | James | Smith |
1 |
0 |
It is possible to see what columns changed, but depending on your synchronization schedule, you only get the net result and no interim changes.
There is another CT function (CHANGE_TRACKING_CONTEXT), but its value (to me) is fleeting at best and will not be discussed here.
3. Review
These demos should have given you a fairly strong understanding of Change Tracking. There are three scripts available for download as referenced within this article. They are commented and should be relatively self-documenting. Run them, modify them, play with them! It is amazing to see how much you will learn in a very short time.
The next part of this series will be to concentrate on a data architecture that will support CT. The third part will be an actual application to the AdventureWorks2012 OLTP database with TSQL code ETL to a modified version of AdventureWorksDW2013.
Stay tuned, the best is yet to come.
Read Part 2: ETL and data warehouse design considerations here
.
Scripts referenced in this article
Note: These scripts are provided courtesy of the author. SolarWinds does not bear responsibility in any way for the results of downloading or using these scripts.
TO DOWNLOAD, PLEASE RIGHT-CLICK ON EACH LINK AND SAVE EACH FILE TO A LOCAL DRIVE:
[…] on a presentation originally given by Mike Byrd at SQL Saturday #234 on August 3, 2013; you can read Part 1 here and Part 2 […]