When improperly written, distributed queries can sometimes be disastrous and lead to poor performance. In particular, a NESTED LOOPS join between two row sources on separate nodes of a distributed database can be very slow because Oracle moves all the data to the local machine (depending on how the query is written).
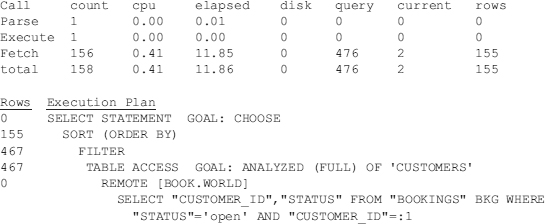
The following listing shows a simple distributed query and its execution plan. This query is slow because, for each row retrieved from the CUSTOMERS table, a separate query is dispatched to the remote node to retrieve records from the BOOKINGS table. This results in many small network packets moving between the two database nodes, and the network latency and overhead degrade performance.

TKPROF output (note that TKPROF still works in 11g and is located in $ORACLE_HOME/bin):
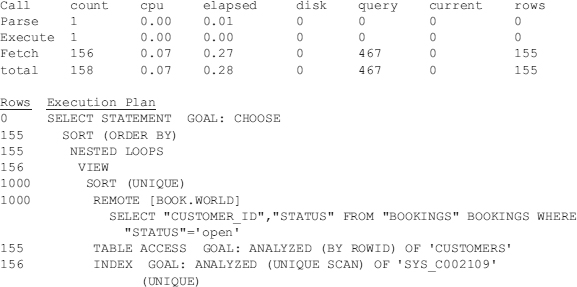
The query in the preceding listing can be rewritten in a form that causes less network traffic. In the next listing, one query is sent to the remote node to determine all customers with open bookings. The output is the same, but performance is greatly improved. Both versions of the query use roughly the same CPU time and logical I/Os on the local node, but the elapsed time is about 97 percent better here. This gain is attributable to reduced network overhead.

TKPROF output:
When distributed queries cannot be avoided, use IN clauses, set operators such as UNION and MINUS, and use everything else you can to reduce the network traffic between nodes of the database. Views that limit the records in a table can also improve performance by reducing what is sent from the remote client to the local client.
TIP
When distributed queries cannot be avoided, use IN clauses, set operators such as UNION and MINUS, and use everything else you can to reduce the network traffic between database nodes. Queries written in a manner that causes looping between distributed nodes (distributed databases) can be extremely slow.
Leave a Reply