Oracle’s index merge feature allows you to merge two separate indexes and use the result of the indexes instead of going to the table from one of the indexes.
Consider the following example (in 11g, if you use a rule-based hint, which Oracle does not support, Oracle includes a note in the EXPLAIN PLAN that specifically suggests you use the cost-based optimizer). Also note that OPTIMIZER_MODE set to CHOOSE is not supported either, so use either ALL_ROWS or FIRST_ROWS instead. The following statistics are based on 1,000,000 records. The table is 210M.
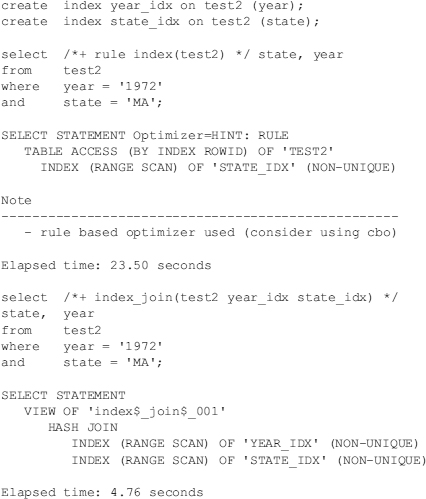
In the first query, I test the speed of using just one of the indexes and then going back to the table (under certain scenarios, Oracle tunes this with an AND-EQUAL operation to access data from the indexes). I then use the INDEX_JOIN hint to force the merge of two separate indexes and use the result of the indexes instead of going back to the table. When the indexes are both small compared to the size of the table, this can lead to better performance. On a faster system, the second query takes only 0.06 seconds, so your mileage will vary.
Now, let’s consider a query to the 25M row SALES3 table on a faster server with separate indexes on the CUST_ID and PROD_ID columns. Using an index merge of the two indexes yields a very slow response time and many blocks read (over 200K physical reads):
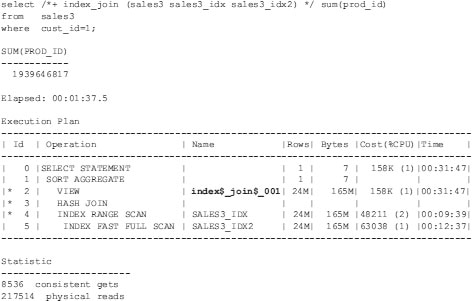
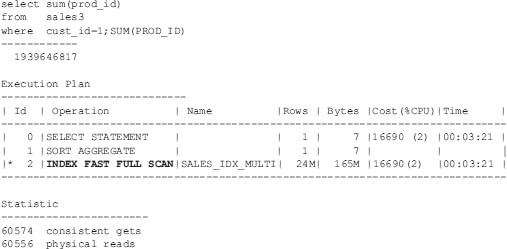
If I drop the two indexes on SALES3 and replace them with a two-part single index on the CUST_ID and PROD_ID columns, performance improves greatly—over ten times faster. Another benefit is the reduction of physical block reads from over 200K to only 60K.
Leave a Reply