Prior to Oracle 8i, you always had to access the table unless the index contained all of the information required. As of Oracle 8i, if a set of indexes exists that contains all of the information required by the query, then the optimizer can choose to generate a sequence of HASH joins between the indexes. Each of the indexes are accessed using a range scan or fast full scan, depending on the conditions available in the WHERE clause. This method is extremely efficient when a table has a large number of columns, but you want to access only a limited number of those columns. The more limiting the conditions in the WHERE clause, the faster the execution of the query. The optimizer evaluates this as an option when looking for the optimal path of execution.
You must create indexes on the appropriate columns (those that will satisfy the entire query) to ensure that the optimizer has the INDEX-MERGE join as an available choice. This task usually involves adding indexes on columns that may not be indexed or on columns that were not indexed together previously. The advantage of INDEX-MERGE joins over fast full scans is that fast full scans have a single index satisfying the entire query. INDEX-MERGE joins have multiple indexes satisfying the entire query.
Two indexes (one on ENAME and one on DEPTNO) have been created prior to the execution of the corresponding query in this next listing. The query does not need to access the table! Table 1 shows this INDEX-MERGE join in graphical format.
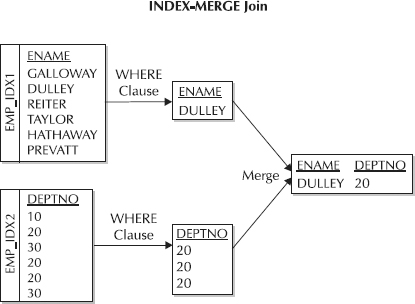
Table 1. An INDEX MERGE join of EMP_IDX1 and EMP_IDX2

To show the improved efficiency, consider this example that uses the TEST2 table. The TEST2 table has 1 million rows and is 210M in size. First, you create the indexes:
![]()
Neither DOBY nor STATE are very limiting when queried individually; consequently, the first indication is to execute a full table scan, as shown in this listing:
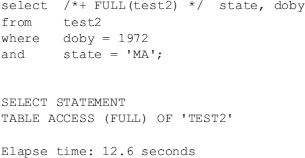
Using a single index on DOBY is slower than the full table scan:
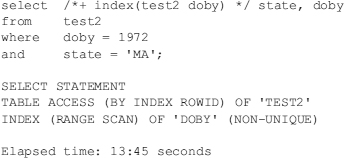
Using a single index on STATE is also slower than a full table scan:
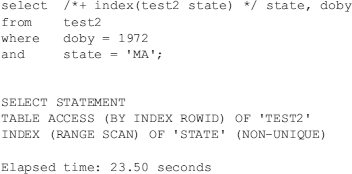
However, using an INDEX-MERGE join of DOBY and STATE is quicker than a full table scan because the table does not need to be accessed, as in this listing:
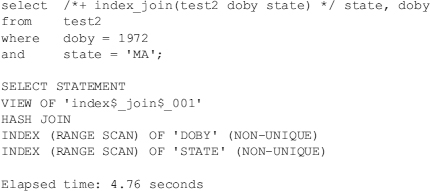
However, the INDEX_FFS (if a single index on all needed columns exists) is still the most efficient method, as shown here:

Although fast full scan is the most efficient option in this case, the INDEX join accommodates more situations. Also, an INDEX_FFS is often a problem as it scans through many index blocks and shows up as a severe amount of ‘db file sequential read’ waits (so try to tune it by using a better index or having a more selective query so it doesn’t need to scan the whole index). Your mileage will vary; this example is only to show how to tune. Which solution is best will be clearer on your unique system after detailed testing.
Leave a Reply