Hybrid columnar compression (HCC) changes the way row data is stored to obtain dramatically better compression ratios, often 10x or more. Rather than storing a series of rows inside a data block, HCC operates on an aggregate group of data blocks called a compression unit. Within the compression unit, HCC-compressed data contains the data for each column. And because most data tables tend to repeat the same column values, HCC saves space by storing each value once. By reducing storage space, HCC also reduces disk I/O requirements and uses less cache memory, too.
Figures 1 and 2 illustrate the difference between uncompressed and HCC-compressed data blocks.
Although HCC was first introduced in Exadata, it is available on certain other Oracle storage technologies. As of this writing, they include Oracle’s family of ZFS storage appliances and Oracle’s Pillar Axiom SAN storage.

HCC has four possible levels: QUERY LOW, QUERY HIGH, ARCHIVE LOW, and ARCHIVE HIGH. These levels provide increased levels of compression, but have an increasingly higher CPU-usage overhead.
Columnar compression has some disadvantages compared to row storage. One disadvantage is CPU usage overhead for compressing and decompressing row data. Another is that DML locks affect entire compression units rather than individual rows. Also, data changes must be done using direct path operations. Examples of direct path operations include
- CREATE TABLE AS SELECT
- INSERT /*+APPEND*/ … SELECT …
- ALTER TABLE MOVE
- SQL*Loader direct path

This list is relatively short; any operation that sends a single row at a time to the database server cannot be used to generate compression units. That means that data created by any of the following row-by-row operations do not utilize HCC compression:
- INSERT without an /*+APPEND*/ hint and SELECT clause
- UPDATE
- DELETE
- SQL*Loader conventional path
What happens when data is loaded by row-by-row operations into an HCC-compressed table? To maintain compatibility with existing applications, HCC transparently reverts to row-based storage. A common mistake is to configure tables with HCC, but not to get HCC compression levels because data was loaded or modified in an incompatible way.
Hybrid Columnar Compression in Action
Remember BIG_TABLE? Let’s see how well it compresses. We’ll compress it with the query high compression level, which generally provides a good trade-off between compression ratio and performance overhead. We’ll use CREATE TABLE AS SELECT, which is compatible with HCC compression.
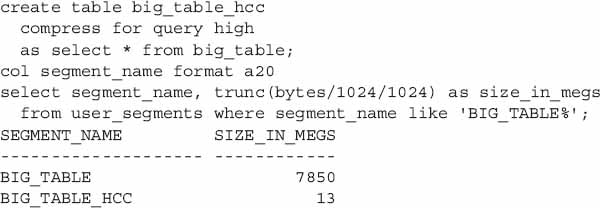
Not bad: From 7.8GB to 13MB, a compression ratio of over 500. Granted, our data is very compressible, as we repeated the same 7000 spaces in each row.
Now let’s try clearing out BIG_TABLE_HCC with a truncate statement and loading it using an insert statement without an /*+APPEND*/ hint, which results in a row-by-row insert that’s not compatible with HCC storage:

You will probably notice that while this command completed successfully, it took quite a bit longer than the CREATE TABLE AS SELECT command. And if you look at the resulting object, it’s even larger than the original, uncompressed table.
Using DBMS_COMPRESSION to Estimate Compression
DBMS_COMPRESSION is a PL/SQL package supplied with the Oracle database, and can be used to estimate compression levels without actually compressing an object. It also allows compression ratios from HCC compression to be estimated on any Oracle database, even those that would not normally support HCC.
To avoid needing another 8+ gigabytes of temporary storage for DBMS_COMPRESSION to run, we’ll create a smaller dataset. HCC_TEST has one million rows like BIG_TABLE, but instead of 7000 spaces, it uses the actual PL/SQL source code from the DBA_SOURCE data dictionary view.

We’ll then call the DBMS_COMPRESSION PL/SQL package. It has many arguments that require a long piece of PL/SQL to call.


While not quite as good as BIG_TABLE_HCC in the previous section, this table compresses pretty well, too, at an estimated compression ratio of 267.9. Most data sets aren’t quite this repetitive, however; try it out on your own tables to see how much storage you can save.
Leave a Reply