The title describes what I started up to do, but as usual, I like to experiment with queries to see if I can beat the optimizer for an acceptable query plan. Initially I thought the OR clause described below would be the best solution, but with a little experimentation, I found the order of columns in an IN clause does have a profound effect.
The other day I encountered the following query in a client’s database:
SELECT cp.ConsumerPhoneID FROM dbo.ConsumerPhone co WHERE cp.CreateDate >= '1900-01-01' AND cp.CreateDate <= '2016-09-15' AND NOT EXISTS (SELECT 1 FROM dbo.Consumer c WHERE cp.ConsumerPhoneID IN (c.Phone1ID, c.Phone2ID, c.Phone3ID)) ORDER BY cp.ConsumerPhoneID
And its performance was just terrible, especially looking at its query plan:
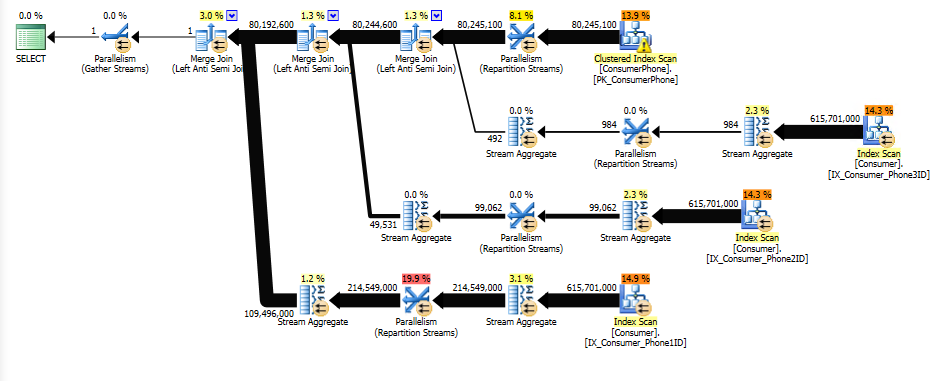
Figure 1: Query Plan 1 (© 2017 | ByrdNest Consulting)
FYI: dbo.Consumer has 61.5 m rows and dbo.ConsumerPhone has almost 106m rows. There are also the following indexes (all with DATA_COMPRESSION = ROW):
IX_Consumer_Phone1ID IX_Consumer_Phone2ID IX_Consumer_Phone3ID
and
IX_ConsumerPhone_CreateDate
This estimated query plan had an estimated cost of 6690 and just looking at the plan, you wonder why there are three index scans on the IX_Consumer_PhonenID indexes. It had 2,580,604 logical reads from dbo.Consumer and 1,283,250 logical reads from dbo.ConsumerPhone, with a CPU time of 752.483 seconds and an elapsed time of 386.660 seconds.
But if I reverse the order of the parameters in the IN clause, as shown below:
SELECT parent.ConsumerPhoneID INTO #t FROM dbo.ConsumerPhone parent WHERE parent.CreateDate >= '1900-01-01' AND parent.CreateDate <= '2016-09-15' AND NOT EXISTS (SELECT 1 FROM dbo.Consumer c WHERE parent.ConsumerPhoneID IN (c.Phone3ID, c.Phone2ID, c.Phone1ID)) ORDER BY parent.ConsumerPhoneID
We get:

Figure 2: Query Plan 2 (© 2017 | ByrdNest Consulting)
Hmmm, interesting. Just changing the order of the parameters in the IN clause gives us a different query plan with an estimated cost of 3179 (almost half the previous cost). Note the two Index seeks: IX_Consumer_Phone2ID and IX_Consumer_Phone3ID.
So, even though I am not thrilled with using ORs for performance, I rewrote the query just changing the NOT EXISTS subquery as shown below:
SELECT cp.ConsumerPhoneID FROM dbo.ConsumerPhone cp WHERE cp.CreateDate >= '1900-01-01' AND cp.CreateDate <= '2016-09-15' AND NOT EXISTS (SELECT 1 FROM dbo.Consumer c WHERE cp.ConsumerPhoneID =c.Phone1ID OR cp.ConsumerPhoneID = c.Phone2ID OR cp.ConsumerPhoneID = c.Phone3ID) ORDER BY cp.ConsumerPhoneID
We now get the following query plan. Note that now we have index seeks on two of what were scans:

Figure 3: Query Plan 3 (© 2017 | ByrdNest Consulting)
with a query cost of 3179. This query had a CPU time of 260.453 seconds and an elapsed time of 283.779 seconds. It had 933,370 logical reads from dbo.Consumer and 1,183,478 logical reads from dbo.ConsumerPhone.
So, the second and third queries ended up getting same query plan with repetitive performance. What is really interesting is that just changing the order of the column names in the IN clause caused a significant change in query plans and performance.
As always, you must test, test, test! In this case, the inquiring mind might just come up with something better than Microsoft®!
Leave a Reply