As user communities require more and more detailed information to remain competitive, it has fallen to database designers and administrators to help ensure that the information is managed effectively and can be retrieved for analysis efficiently. In this section, we discuss partitioning data and the reasons why it is so important when working with large databases. Afterward, you’ll follow the steps required to make it all work.
Why Use Data Partitioning
Let’s start by defining data partitioning. In its simplest form, it is a way of breaking up or subsetting data into smaller units that can be managed and accessed separately. It has been around for a long time, both as a design technique and as a technology. Let’s look at some of the issues that gave rise to the need for partitioning and the solutions to these issues.
Tables containing very large numbers of rows have always posed problems and challenges for DBAs, application developers, and end users alike. For the DBA, the problems are centered on the maintenance and manageability of the underlying data files that contain the data for these tables. For the application developers and end users, the issues are query performance and data availability.
To mitigate these issues, the standard database design technique was to create physically separate tables, identical in structure (for example, columns), but each containing a subset of the total data (this design technique will be referred to as non-partitioned here). These tables could be referred to directly or through a series of views. This technique solved some of the problems, but still meant maintenance for the DBA with regard to creating new tables and/or views as new subsets of data were acquired. In addition, if access to the entire dataset was required, a view was needed to join all subsets together.
Figure 1 illustrates a non-partitioned design. In this sample, separate tables with identical structures have been created to hold monthly sales information for 2005. Views have also been defined to group the monthly information into quarters using a union query. The quarterly views themselves are then grouped together into a view that represents the entire year. The same structures would be created for each year of data. In order to obtain data for a particular month or quarter, an end user would have to know which table or view to use.

Similar to the technique illustrated in Figure 1, the partitioning technology offered by Oracle Database 12c is a method of breaking up large amounts of data into smaller, more manageable chunks, with each of the partitions having their own unique name and their own storage definitions. But, like the non-partitioned technique, it is transparent to the end user, offering improved performance and reduced maintenance. Figure 2 illustrates the same SALES table, but implemented using Oracle Database 12c’s partitioning option. From the end user’s perspective, there is only one table called SALES and all that is required to access data from the correct partition is a date (or a month and year).
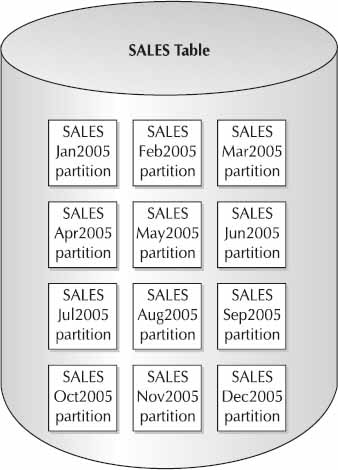
Oracle partitioning was first introduced in Oracle 8, is only available with the Enterprise Edition, and is an additional option to the core database license. As previously suggested, it is one database option that is a must-have for anyone with a large volume of data that needs to be quickly retrievable or with a need for speedy data archiving. Many improvements have been made since then, and Oracle Database 12c contains all of the latest features and enhancements to maintain the objects. The remainder of this section discusses these features in more detail.
Manageability
When administering large databases, DBAs are required to determine the most efficient and effective ways to configure the underlying data files that support the tables in the database. The decisions made at this time will affect your data accessibility and availability as well as backup and recovery.
Some of the benefits for database manageability when using partitioned tables include the following:
- Historical partitions can be made read-only and will not need to be backed up more than once. This also means faster backups. With partitions, you can move data to lower-cost storage by moving the tablespace, sending it to an archive via an export (datapump), or some other method.
- The structure of a partitioned table needs to be defined only once. As new subsets of data are acquired, they will be assigned to the correct partition, based on the partitioning method chosen. In addition, with Oracle 12c you have the ability to define intervals that allow you to define only the partitions that you need. It also allows Oracle to automatically add partitions based on data arriving in the database. This is an important feature for DBAs, who currently spend time manually adding partitions to their tables.
- Moving a partition can now be an online operation, and the global indexes are maintained and not marked unusable. ALTER TABLE…MOVE PARTITION allows DDL and DML to continue to run uninterrupted on the partition.
- Global index maintenance for the DROP and TRUNCATE PARTITION happens asynchronously so that there is no impact to the index availability.
- Individual tablespaces and/or their data files can be taken offline for maintenance or archiving without affecting access to other subsets of data. For example, assuming data for a table is partitioned by month (later in this chapter, you learn about the different types of partitioning) and only 13 months of data is to be kept online at any one time, the earliest month is archived and dropped from the table when a new month is acquired. This is accomplished using the command ALTER TABLE abc DROP PARTITION xyz and does not affect access to the remaining 12 months of data.
- Other commands that would normally apply at the table level can also be applied to a particular partition of the table. These include but are not limited to DELETE, INSERT, SELECT, TRUNCATE, and UPDATE. TRUNCATE and EXCHANGE PARTITION operations allow for cascading data maintenance for related tables. You should review the Oracle Database VLDB and Partitioning Guide for a complete list of the commands that are available with partitions and subpartitions.
Performance
One of the main reasons for partitioning a table is to improve I/O response time when selecting data from the table. Having a table’s data partitioned into subsets can yield much faster query results when you are looking for data that is contained within one subset of the total. Let’s look at an illustrative example.
Assume the SALES table contains 100 million records representing daily sales revenue for the years 2008 to 2010 inclusive. You want to know what the total revenue is for February 2010. Your query might look something like this:

With a non-partitioned table design, all 100 million rows would need to be scanned to determine if they belong to the date criteria. With a partitioned table design based on monthly partitions, with about 2.8 million rows for each month, only those rows in the February 2012 partition (and therefore only about 2.8 million rows) would be scanned. The process of eliminating data not belonging to the subset defined by the query criteria is referred to as partition pruning.
Leave a Reply