The SQL Server Database Engine uses different replication types to distribute data between different nodes (transactional, snapshot, peer-to-peer, and merge), and these provide the functionality for maintaining replicated data. Replication models are used by a company to design its own data replication. Each replication model can be implemented using one or more existing replication types. Both the replication type and replication model are usually specified at the same time.
Depending on requirements, several replication models can be used. The basic ones are as follows:
- Central publisher with distributor
- Central publisher with a remote distributor
- Central subscriber with multiple publishers
- Multiple publishers with multiple subscribers
The following sections describe these models.
Central publisher with distributor
In the central publisher with distributor model, there is one publisher and usually one distributor, which are hosted on one instance of the Database Engine. The publisher creates publications that are distributed by the distributor to several subscribers. The publications designed by this model and received at a subscriber are usually read-only.
The advantage of this model is its simplicity. For this reason, the model is usually used to create a copy of a database, which is then used for interactive queries and simple report generation. (Another situation for using this model is to maintain a remote copy of a database, which could be used by remote systems in the case of communication breakdown.)
On the other hand, if your instance of the Database Engine is tuned such that all system resources are maximized, you should choose another data replication model.
Central publisher with a remote distributor
If the amount of publishing data is not very large, the publisher and distributor can reside on one server. Otherwise, using two separate servers for publishing and distribution is recommended because of performance issues. (If there is a heavy load of data to be published, the distributor is usually the bottleneck.) Figure 1 shows the replication model with the central publisher and a separate distributor.
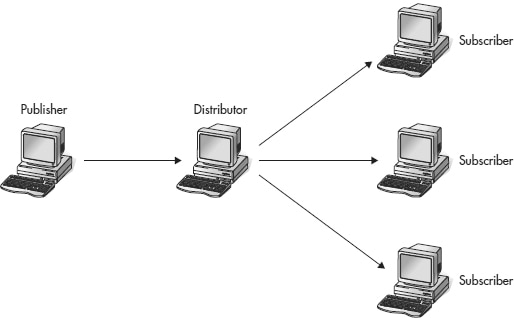
Figure 1. Central publisher with a remote distributor
NOTE
This scenario can be used as a starting point to increase a number of publishing servers and/or subscribing servers.
Central subscriber with multiple publishers
The scenario described at the beginning of this chapter of the traveling salesperson who transmits data to headquarters is a typical example of the central subscriber with multiple publishers. The data is gathered at a centralized subscriber, and several publishers send their data.
For this model, you can use either the peer-to-peer transactional or merge replication type, depending on the use of replicated data. If publishers publish (and therefore update) the same data to the subscriber, merge replication should be used. If each publisher has its own data to publish, peer-to-peer transactional replication should be used. (In this case, published tables will be filtered horizontally, and each publisher will be the owner of a particular table fragment.)
Multiple publishers with multiple subscribers
The replication model in which some or all of the servers participating in data replication play the role of the publisher and the subscriber is known as multiple publishers with multiple subscribers. In most cases, this model includes several distributors that are usually placed at each publisher (see Figure 2).
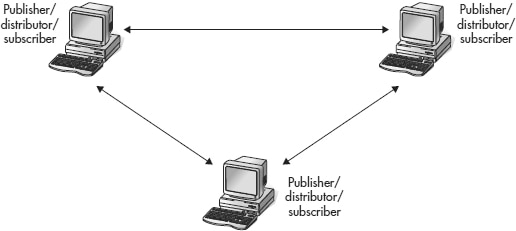
Figure 2. Multiple publishers with multiple subscribers
This model can be implemented using merge replication only, because publications are modified at each publishing server. (The only other way to implement this model is to use the distributed transactions with two-phase commit.)
Leave a Reply