The nested loop join, also called nested iteration, uses one join input as the outer input table (shown as the top input in the graphical execution plan; see Figure 1 below) and the other input as the inner input table. The outer loop consumes the outer input table row by row. The inner loop, executed for each outer row, searches for matching rows in the inner input table. The listing below is an example that produces a nested loop join.
--Nested Loop Join SELECT C.CustomerID, c.TerritoryID FROM Sales.SalesOrderHeader oh JOIN Sales.Customer c ON c.CustomerID = oh.CustomerID WHERE c.CustomerID IN (10,12) GROUP BY C.CustomerID, c.TerritoryID
Note: This is available for download on wrox.com.
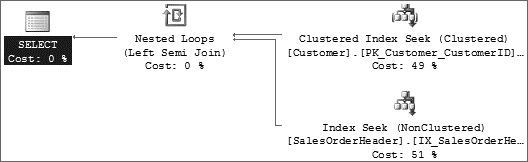
Figure 1. Sample Execution Plan for Nested Loop Join
A nested loop join is particularly effective if the outer input is small and the inner input is sorted and large. In many small transactions, such as those affecting only a small set of rows, indexed nested loop joins are superior to both merge joins and hash joins. In large queries, however, nested loop joins are often not the optimal choice. Of course, the presence of a nested loop join operator in the execution plan doesn’t indicate whether it’s an efficient plan. A nested loop join is the default algorithm. This does not mean that it is the first algorithm used (that would be the in-memory hash join), but that it can always be applied if another algorithm does match the specific criteria. For example, the “requires join” algorithm must be equijoin. (The join condition is based on the equality operator.)
In the example query, a clustered index seek is performed on the outer table Customer where CustomerID is 10 or 12, and for each CustomerID, an index seek is performed on the inner table SalesOrderHeader. Therefore, Index IX_SalesOrderHeader_CustomerID is sought two times (one time for CustomerID 10 and one time for CustomerID 12) on the SalesOrderHeader table.
Leave a Reply