SQL Server 2014 introduced the new database engine enhancement called In-Memory OLTP. This feature uses new data structures which are optimized for in-memory access of table. People normally call it In-Memory database. In reality, we would like to call it partially in-memory database because SQL Server allows us to have few hot tables in-memory and rest as traditional disk based tables.
In this new feature, the disk structure for storage of in-memory table has also been enhanced. Since there is no 8 KB pages when we are using in-memory OLTP, the data of table is not stored in traditional master database file (mdf). They are stored in checkpoint files.
In-Memory File Creation
Let’s create an In-Memory table in a database and look at those files.
CREATE DATABASE [DemoInMemoryOLTP] ON PRIMARY (NAME = N'DemoInMemoryOLTP', FILENAME = N'E:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\DemoInMemoryOLTP.mdf', SIZE = 4096KB, FILEGROWTH = 1024KB ), FILEGROUP [IMO_FG] CONTAINS MEMORY_OPTIMIZED_DATA (NAME = N'DemoInMemoryOLTP_lFG', FILENAME = N'E:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\DemoInMemoryOLTP_lFG') LOG ON (NAME = N'DemoInMemoryOLTP_log', FILENAME = N'E:\Program Files\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\DATA\DemoInMemoryOLTP_log.ldf', SIZE = 2048KB, FILEGROWTH = 10%) GO
You may need to change the path of the files based on your test environment. Now since we have already created a filegroup which contains MEMORY_OPTIMIZED_DATA, we can now create table which resides in main memory of the machine. We have used template available with SSMS to create below table.
USE DemoInMemoryOLTP
GO
--Drop table if it already exists.
IF OBJECT_ID('dbo.sample_memoryoptimizedtable','U') IS NOT NULL
DROP TABLE dbo.sample_memoryoptimizedtable
GO
CREATE TABLE dbo.sample_memoryoptimizedtable
(
c1 int NOT NULL,
c2 float NOT NULL,
c3 decimal(10,2) NOT NULL INDEX index_sample_memoryoptimizedtable_c3 NONCLUSTERED (c3),
CONSTRAINT PK_sample_memoryoptimizedtable PRIMARY KEY NONCLUSTERED (c1),
-- See SQL Server Books Online for guidelines on determining appropriate bucket count for the index
INDEX hash_index_sample_memoryoptimizedtable_c2 HASH (c2) WITH (BUCKET_COUNT = 131072)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
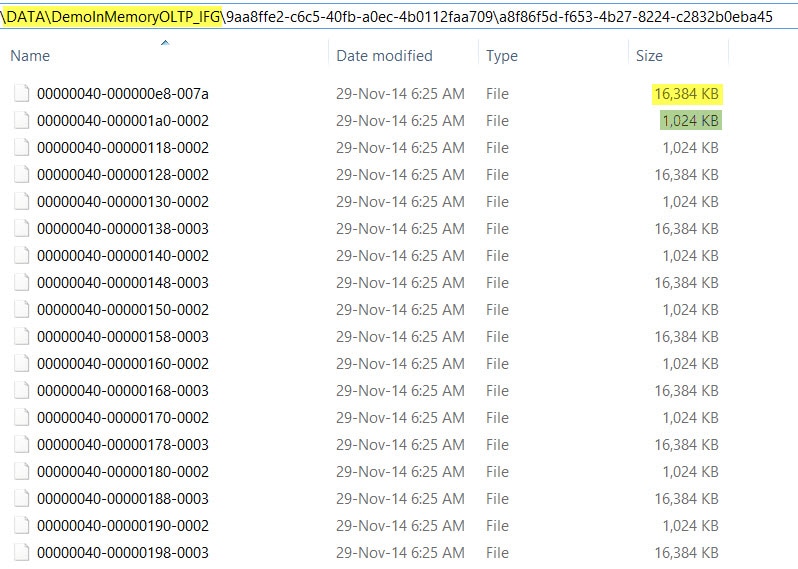
If we go to the path where In-Memory filegroup is created, we could see something like below.
 Notice that there are two kind of files, one is 16 MB in size and another one of 1 MB is size. They are called as Data file and Delta files respectively. The data file contains all the insertion along with the actual data and unique ID. While Delta file contains the pointer of data which is delete from the in-memory tables.
Notice that there are two kind of files, one is 16 MB in size and another one of 1 MB is size. They are called as Data file and Delta files respectively. The data file contains all the insertion along with the actual data and unique ID. While Delta file contains the pointer of data which is delete from the in-memory tables.
So far, we have discussed the behavior seen after creating the in-memory table in SQL Server. If you have worked on performance tuning exercises, you might have heard the importance of placement of data files and transaction log file to different drives. Something similar is also available for in-memory tables too. We will discuss this behavior next.
In-Memory File Placement
SQL Server doesn’t allow us to create multiple In-Memory filegroups but allows us to add multiple containers in single in-memory filegroup. We cannot specify which table should go to which Data/Delta files as they are for specific timestamp range and are not depending on object. Let us assume we have two drives and we want to utilize them equally for in-memory tables, we should not add two containers as a best practice. Here is the reason: Data and Delta files are created in sequence. First file (data file) would go to first container, second file (delta file) would go to second container and third (data fie) would go back to first container. This sequence would go on. The problem with this round robin distribution is that first drive contains only data file and second container contains only delta files. If the workload is having more inserts and less deletes, then usage of both drive would not be equal.
Let us look at the above theory in code. I have two drives, C and E on my system and let me go ahead and create two containers, one on each drive:
CREATE DATABASE DemoInMemoryOLTP
GO
ALTER DATABASE DemoInMemoryOLTP
ADD filegroup DemoInMemoryOLTP_IMO_FG CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE DemoInMemoryOLTP
ADD FILE (
NAME = 'DemoInMemoryOLTP_C',filename = 'C:\DemoInMemoryOLTP'
) TO filegroup DemoInMemoryOLTP_IMO_FG
GO
ALTER DATABASE DemoInMemoryOLTP
ADD FILE (
NAME = 'DemoInMemoryOLTP_E',filename = 'E:\DemoInMemoryOLTP'
) TO filegroup DemoInMemoryOLTP_IMO_FG
GO
use DemoInMemoryOLTP
go
CREATE TABLE dbo.sample_memoryoptimizedtable
(
c1 int NOT NULL,
c2 float NOT NULL,
c3 decimal(10,2) NOT NULL INDEX index_sample_memoryoptimizedtable_c3 NONCLUSTERED (c3),
CONSTRAINT PK_sample_memoryoptimizedtable PRIMARY KEY NONCLUSTERED (c1),
-- See SQL Server Books Online for guidelines on determining appropriate bucket count for the index
INDEX hash_index_sample_memoryoptimizedtable_c2 HASH (c2) WITH (BUCKET_COUNT = 131072)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
If we look at folders created under C and E drives, this is what we can see:

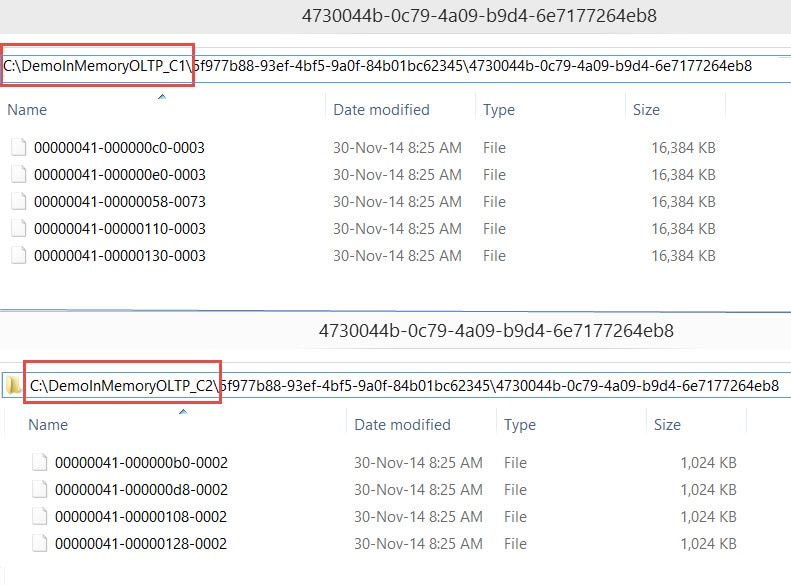
The solution to this problem is by creating two folders on each drive. Let’s say C1, C2 on C drive and E1, E2 on E Drive. This would create files in sequence on C1 (Data), C2 (Delta) {both on C} and then E1 (Data), E2 (Delta) {both on E}. This would help in balancing the IO when we have two physical drives for keeping In-Memory Data.
CREATE DATABASE DemoInMemoryOLTP
GO
ALTER DATABASE DemoInMemoryOLTP
ADD filegroup DemoInMemoryOLTP_IMO_FG CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE DemoInMemoryOLTP
ADD FILE (
NAME = 'DemoInMemoryOLTP_C1',filename = 'C:\DemoInMemoryOLTP_C1'
) TO filegroup DemoInMemoryOLTP_IMO_FG
GO
ALTER DATABASE DemoInMemoryOLTP
ADD FILE (
NAME = 'DemoInMemoryOLTP_C2',filename = 'C:\DemoInMemoryOLTP_C2'
) TO filegroup DemoInMemoryOLTP_IMO_FG
GO
ALTER DATABASE DemoInMemoryOLTP
ADD FILE (
NAME = 'DemoInMemoryOLTP_E1',filename = 'E:\DemoInMemoryOLTP_E1'
) TO filegroup DemoInMemoryOLTP_IMO_FG
GO
ALTER DATABASE DemoInMemoryOLTP
ADD FILE (
NAME = 'DemoInMemoryOLTP_E2',filename = 'E:\DemoInMemoryOLTP_E2'
) TO filegroup DemoInMemoryOLTP_IMO_FG
GO
use DemoInMemoryOLTP
go
CREATE TABLE dbo.sample_memoryoptimizedtable
(
c1 int NOT NULL,
c2 float NOT NULL,
c3 decimal(10,2) NOT NULL INDEX index_sample_memoryoptimizedtable_c3 NONCLUSTERED (c3),
CONSTRAINT PK_sample_memoryoptimizedtable PRIMARY KEY NONCLUSTERED (c1),
-- See SQL Server Books Online for guidelines on determining appropriate bucket count for the index
INDEX hash_index_sample_memoryoptimizedtable_c2 HASH (c2) WITH (BUCKET_COUNT = 131072)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
If we look at the distribution now, C drive contains both Data files (in C1) and Delta files (in C2), as shown below. The same would be true for E drive as well.
Conclusion
In this post, we discussed the ways to create In-Memory Optimized tables with SQL Server. Going further, we saw how we can optimize IO performance of In-Memory OLTP tables using a two drive configuration. The concept can be extended for odd number of drives too with some variations. As DBA’s deploy SQL Server 2014 with In-Memory tables, these performance tips will get even more powerful tools of use. The concepts of In-Memory are here to stay and is the future for applications being built for today’s needs. Explore these concepts on your test environment and become familiar with the deployment options.
Leave a Reply