The hash join has two inputs like every other join: the build input (outer table) and the probe input (inner table). The query optimizer assigns these roles so that the smaller of the two inputs is the build input. A variant of the hash join (hash aggregate physical operator) can do duplicate removal and grouping, such as SUM (OrderQty) GROUP BY TerritoryID. These modifications use only one input for both the build and probe roles.
The following query is an example of a hash join, and the graphical execution plan is shown in Figure 1 below:
--Hash Match SELECT p.Name As ProductName, ps.Name As ProductSubcategoryName FROM Production.Product p JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID ORDER BY p.Name, ps.Name
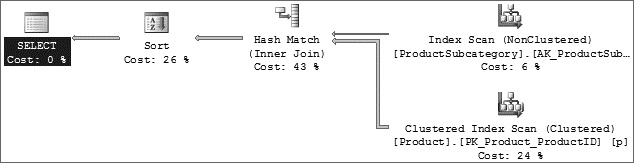
Figure 1. Sample Execution Plan for Hash Join
As discussed earlier, the hash join first scans or computes the entire build input and then builds a hash table in memory if it fits the memory grant. Each row is inserted into a hash bucket according to the hash value computed for the hash key, so building the hash table needs memory. If the entire build input is smaller than the available memory, all rows can be inserted into the hash table. (You see what happens if there is not enough memory shortly.) This build phase is followed by the probe phase. The entire probe input; it is the Production.Product table) is scanned or computed one row at a time, and for each probe row (from the Production.Product table), the hash key’s value is computed, the corresponding hash bucket (the one created from the Production.ProductSubCategory table) is scanned, and the matches are produced. This strategy is called an in-memory hash join.
If you’re talking about the AdventureWorks database running on your laptop with 1GB of RAM, you won’t have the problem of not fitting the hash table in memory. In the real world, however, with millions of rows in a table, there might not be enough memory to fit the hash table. If the build input does not fit in memory, a hash join proceeds in several steps. This is known as a grace hash join. In this hash join strategy, each step has a build phase and a probe phase. Initially, the entire build and probe inputs are consumed and partitioned (using a hash function on the hash keys) into multiple files. Using the hash function on the hash keys guarantees that any two joining records must be in the same pair of files. Therefore, the task of joining two large inputs has been reduced to multiple, but smaller, instances of the same tasks. The hash join is then applied to each pair of partitioned files. If the input is so large that the preceding steps need to be performed many times, multiple partitioning steps and multiple partitioning levels are required. This hash strategy is called a recursive hash join.
NOTE
SQL Server always starts with an in-memory hash join and changes to other strategies if necessary.
Recursive hash joins (or hash bailouts) cause reduced performance in your server. If you see many Hash Warning events in a trace (the Hash Warning event is under the Errors and Warnings event class), update statistics on the columns that are being joined. You should capture this event if you see that you have many hash joins in your query. This ensures that hash bailouts are not causing performance problems on your server. When appropriate indexes on join columns are missing, the optimizer normally chooses the hash join.
Leave a Reply