Columnstore index is a new type of index introduced in SQL Server 2012. It is a column-based non-clustered index geared toward increasing query performance for workloads that involve large amounts of data, typically found in data warehouse fact tables.
This new type of index stores data column-wise instead of row-wise, as indexes currently do. For example, consider an Employee table containing employee data, as shown in Table 1.
Table 1: Sample Employee Table
| FirstName | LastName | HireDate | Gender |
| Adam | Jorgensen | 5/9/2008 | Male |
| Sherri | McDonald | 7/1/2009 | Female |
| Brian | McDonald | 09/15/2009 | Male |
| Jose | Chinchilla | 1/10/2010 | Male |
| Tim | Murphy | 7/1/2009 | Male |
| Tim | Moolic | 6/1/2008 | Male |
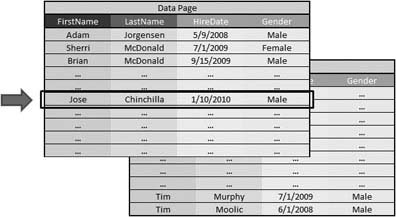
In a row-based index, the data in the Employee table is stored in one or more data pages, as shown in Figure 1.
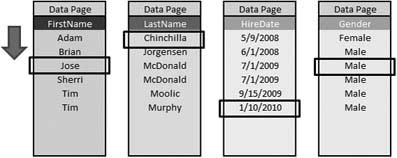
In a column-based index, the data in the Employee table is stored in separate pages for each of the columns, as shown in Figure 2.
Performance advantages in columnstore indexes are possible by leveraging the VertiPaq compression technology, which enables large amounts of data to be compressed in-memory. This in-memory compressed store reduces the number of disk reads and increases buffer cache hit ratios because only the smaller column-based data pages that need to satisfy a query are moved into memory.
For wide tables, such as those commonly found in data warehouses, columnstore indexes come in handy as you essentially reduce the amount and size of data needed to be accessed for any given query. For example, consider the following query:
SELECT FirstName, LastName, FROM EmployeeTable WHERE HireDate >= ‘1/1/2010’
A column-store index is more efficient for this example because only one smaller-sized (compressed) data page is needed to satisfy the query. In this case, the columnstore index for the HireDate column satisfies the WHERE clause. A row-based index is not as efficient because it may need to load one or more larger-sized data pages into memory and read the entire rows, including columns not needed to satisfy the query. A larger-sized data page and additional unnecessary columns increases data size, memory usage, disk reads, and overall query time. Imagine if this table had 20 or more columns!
Columnstore indexes have some requirements and limitations, as shown in Table 2.
Table 2: Requirements and Limitations of Columnstore Index
| Description | Requirement/Limitation |
| No. of columnstore indexes per table | 1 |
| Index record size limit of 900 bytes | No limit/Not applicable |
| Index limit of 16 key columns | No limit/Not applicable |
| Table partitioning support | Yes, as a partition aligned index. |
| Can be combined with row-based indexes? | Yes, if clustered index, all columns must be present in columnstore index. |
| Update, Delete, Insert, Merge supported? | No, columnstore indexes are read-only but workarounds exist. Refer to Books Online: Best Practices: Updating Data in a Columnstore Index. |
| Data types that can be included in a columnstore index | Char, varchar except varchar(max), nchar, nvarchar except nvarchar(max), decimal and numeric except with precision greater than 18 digits, int, bigint, smallint, tinyint, float, real, bit, money, smallmoney, all date and time data types except datetimeoffset with scale greater than 2. |
| Data types that cannot be included in a columnstore index | Binary, varbinary, ntext, text, image, varchar(max), nvarchar(max), uniqueidentifier, rowversion, timestamp, sql_variant, decimal and numeric with precision greater than 18 digits, datetimeoffset with scale greater than 2, CLR types including hierarchyid and spatial types, xml. |
Following is the basic syntax to create a columnstore index:
CREATE COLUMNSTORE INDEX idx_cs1 ON EmployeeTable (FirstName, LastName, HireDate, Gender)
You can also create columnstore indexes using SQL Server Management Studio. Simply navigate to the Indexes section of the table, and select New Index > Non-clustered Columnstore Index.
Hi,
Great article!
As far as I know, Microsoft started out with the non clustered column store indexes in their 2012 version. Was there any particular reason for this? And if a column store index is created on a table which was previously stored row wise, does the whole orientation of the data change or another copy of the data is created?
Let me know what you guys think about this.
Thanks!
Best,
Sakshi
Good Articlee
good article.
can you tell me. how to update database from sql 2012 to Sql 2016 with column store index?
Why not just a covering index on the 4 columns, or Hiredate and include Firstname, Lastname & Gender ?
In a sense, it would seem that the feature of column store / vertipaq indices is taking the concept of covering a query with an index to the extreme. While adding indices speeds can read performance, it has the disadvantage of requiring more work when updating existing records and/or writing new records since the indices must all be updated, as well. Looks like the column store feature just deals with that by not allowing data to be updated at all. Is my understanding correct?!?
I’ll start by saying I’m not an expert on column stores, but I think the big benefit is that the data itself is stored in a column format. I think about it this way – if I want to just pull a list of last names that meet the condition lastname = ‘JONES’ from my emp database, even going after the data in an indexed fashion, I still have to retrieve the full rows for each emp record that matches that condition. If I had implemented a column store index on lastname, I can get the data much more efficiently since the required pages I need don’t contain the full record – just that columns value. I can get a lot more lastname values in the same 8k page size than I could if I have to also include their empid, SSN, firstname, etc. in that same page.
There is definitely overhead for transactions – I think that’s why the cost/benefit comes out more favorably when talking about data warehouses or OLAP type of databases. I believe you can still update the data though…
Others may have thoughts on this as well?
I may be mistaken but i believe that in your representation of the columstore the name lastname and other columns entries should keep the same order as when they were in the rowstore representation otherwise i don’t see how you can link your data back.
The columnstore maintains each column in it’s own segment or segments. This allows each column’s data to be accessed independently and results in less I/O and CPU because it doesn’t have to read the entire row. A segment is a highly compressed Large OBject (LOB) and data within each column’s segment matches row-by-row so that the rows can always be assembled correctly. The matched rows across all segments form a row group. I don’t believe the order of the columns matter.