Another critical performance question is how all operations with such large data volumes will impact the buffer cache. Oracle provides enough flexibility to adjust the caching option in a number of ways:
- NOCACHE is the default value. It is designed to be used only if you are rarely accessing the LOBs or if the LOBs are extremely large. From a physical standpoint, the existing implementations are completely different:
- BasicFile Uses DirectRead/DirectWrite. These mechanisms allow tunneling to storage for a lot of data, completely avoiding buffer cache and the DBWR process. The data is written directly from PGA. Although direct operations do not clog the buffer cache, in an I/O-active system (especially OLTP), they could cause significant “hiccups” because DirectWrite has to (a) wait for the disk to be free from other I/O operations, and (b) wait for the I/O system to confirm that the write was successful. While the first wait could slow down the session where LOBs are manipulated, the second wait can intermittently slow down the whole database because it prevents DBWR from touching the I/O system.
- SecureFile Utilizes a special shared pool area that is managed by SHARED_IO_POOL and is handled well by Oracle. The authors did not find any cases in which manual adjustment of this parameter significantly impacted overall performance. However, if you are running in a highly concurrent environment with large LOB files, you can try to manually set SHARED_IO_POOL to higher values (the default is currently 4MB and the maximum is 64MB) and test the effect.
- CACHE is the best option for LOBs requiring a lot of read/write activity.
- CACHE READS helps when you create the LOB once and read data from it and the size of LOBs to be read in the system at any time does not take too much space out of the buffer pool. “Write” processes are implemented in the same way as in the NOCACHE option.
The impact of the cache settings on system performance can be significant. Although it is possible to examine a number of tests here, the two most interesting are BasicFile NOCACHE vs. SecureFile NOCACHE, and SecureFile NOCACHE vs. SecureFile CACHE. Together, these tests fully represent all of the existing LOB-related I/O mechanisms. The following script creates two more columns in addition to SECURE_TAB.DEMO_CL (which is SecureFile NOCACHE):
![]()
First, it makes sense to check the effect of switching from BasicFile to SecureFile:
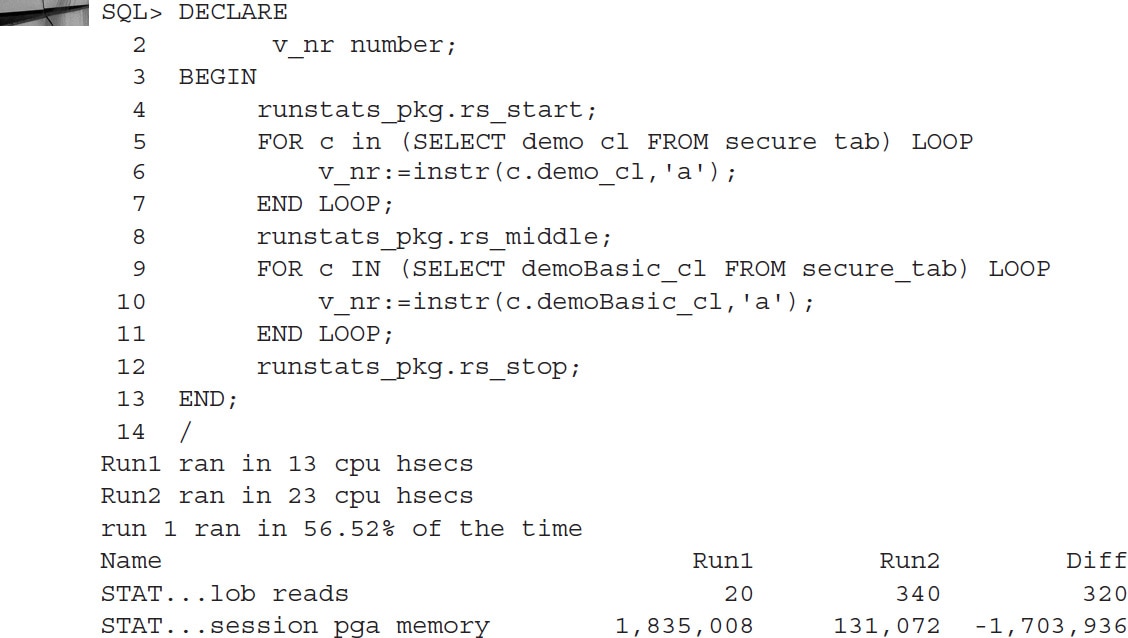
It seems that the SecureFile implementation is much faster, but you are paying a price for it in the form of higher PGA usage. On the other hand, there are fewer LOB operations, so overall, the SecureFile implementation proves that this is a much more efficient way of working with LOBs.
The next test checks the effect of CACHE vs. NOCACHE for SecureFile. Considering that the CACHE option makes sense only if the same data is being accessed multiple times, the following test attempts to read exactly the same CLOB 20 times:

In this case, you are trading logical reads for physical reads. Of course, logical reads are faster and you will achieve performance benefits. But this works only as long as you do not have to worry that LOB operations are pushing more frequently accessed data blocks out of the buffer cache. In general, you should enable the CACHE option only if you are sure that this data is constantly needed. Otherwise, by speeding up LOB operations, you may slow down everything else.
In the final article in this series, we will consider logging modes.
Leave a Reply