The biggest misconception that deters people from using Dynamic SQL is the idea that it will always be slower than regular SQL. Nobody questions the fact that if you compare the execution of a plain query with exactly the same query wrapped with EXECUTE IMMEDIATE, you will see some performance degradation. But this is not a fair test. Instead of comparing syntactically equivalent cases, you should compare functionally equivalent ones. If your tests are properly set up, you will find that, in some cases, Dynamic SQL provides a viable alternative and can provide better performance than traditionally written code.
When coding INSTEAD OF UPDATE triggers, you can use Dynamic SQL to generate an UPDATE statement that includes only columns that have changed values. This approach significantly decreases UNDO/REDO generation at the cost of some extra CPU time and latches. In this example, considering that decreasing the number of UNDO entries was critical for the purposes of replication, the price paid was more than offset by the benefit. This means that when comparing slow versus fast, you need to consider not only the time spent in a module, but the overall resource utilization of the system.
The main advantage of Dynamic SQL is that you can fine-tune your code at run time. By adding a small extra layer of complexity, you can utilize the knowledge that was not available at compilation time. This extra knowledge is what can make Dynamic SQL–based solutions more efficient than their hard-coded counterparts. The dynamic search concept covered in this chapter is based on the fact that you know all of the pieces of a SQL query only when an end user enters the search criteria, and not a second earlier. You could try to cover all possible alternatives in regular SQL, or you can do it on the fly. The more complex the possible search criteria, the more performance benefits that are gained from using Dynamic SQL.
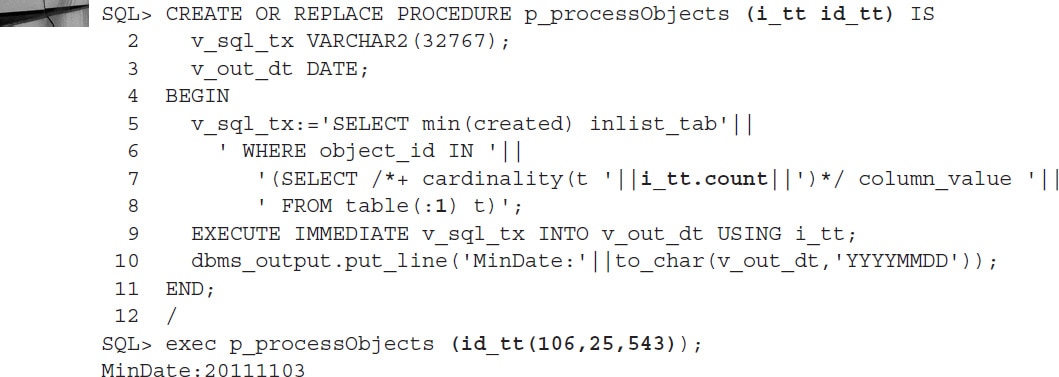
In general, Dynamic SQL thrives on the unknown. The less information that is available now, the more valuable its usage. For example, if you take a look at the previously shown IN-list example utilizing a DYNAMIC_SAMPLING hint, it is still valid to say that because Oracle samples the dataset, there is still a probability of a mistake. Since you would like to be 100 percent certain that Oracle uses the correct cardinality, you can convert the entire module to Dynamic SQL and adjust the CARDINALITY hint on the spot:
Leave a Reply