Relations between countries, or between departments in a company, or between users and developers, are usually the product of particular historical circumstances, which may define current relations even though the circumstances have long since passed. The result of this can be abnormal relations, or, in current parlance, dysfunctional relations. History and circumstance often have the same effect on data—on how it is collected, organized, and reported. And data, too, can become abnormal and dysfunctional.
Normalization is the process of putting things right, making them normal. The origin of the term is norma, the Latin word for a carpenter’s square that’s used for ensuring a right angle. In geometry, when a line is at a right angle to another line, it is said to be “normal” to it. In a relational database, the term also has a specific mathematical meaning having to do with separating elements of data (such as names, addresses, or skills) into affinity groups and defining the normal, or “right,” relationships between them.
The basic concepts of normalization are being introduced here so users can contribute to the design of an application they will be using or better understand one that has already been built. It would be a mistake, however, to think that this process is really only applicable to designing a database or a computer application. Normalization results in deep insights into the information used in a business and how the various elements of that information are related to each other. This will prove to be educational in areas apart from databases and computers.
The Logical Model
An early step in the analysis process is the building of a logical model, which is simply a normalized diagram of the data used by the business. Knowing why and how the data gets broken apart and segregated is essential to understanding the model, and the model is essential to building an application that will support the business for a long time, without requiring extraordinary support.
Normalization is usually discussed in terms of form: First, Second, and Third Normal Form are the most common terms, with Third representing the most highly normalized state. There are Fourth and Fifth normalization levels defined as well, but they are beyond the scope of this discussion.
Consider a bookshelf: For each book, you can store information about it—the title, publisher, authors, and multiple categories or descriptive terms for the book. Assume that this book-level data becomes the table design in Oracle. The table might be called BOOKSHELF, and the columns might be TITLE, PUBLISHER, AUTHOR1, AUTHOR2, AUTHOR3, and CATEGORY1, CATEGORY2, CATEGORY3. The users of this table already have a problem: In the BOOKSHELF table, users are limited to listing just three authors or categories for a single book.
What happens when the list of acceptable categories changes? Someone has to go through every row in the BOOKSHELF table and correct all the old values. And what if one of the authors changes his or her name? Again, all the related records must be changed. What will you do when a fourth author contributes to a book?
These are not really computer or technical issues, even though they became apparent because you were designing a database. These are much more basic issues about how to sensibly and logically organize the information of a business. These are the issues that normalization addresses. Normalization is done with a step-by-step reorganization of the elements of the data into affinity groups, by eliminating dysfunctional relationships and by ensuring normal relationships.
Normalizing the Data
Step one of the reorganization is to put the data into First Normal Form. You do this by moving data into separate tables, where the data in each table is of a similar type, and giving each table a primary key—a unique label or identifier. This eliminates repeating groups of data, such as the authors on the bookshelf.
Instead of having only three authors allowed per book, each author’s data is placed in a separate table, with a row per name and description. Doing this eliminates the need for a variable number of authors in the BOOKSHELF table and is a better design than limiting the BOOKSHELF table to just three authors.
Next, you define the primary key to each table: What will uniquely identify and allow you to extract one row of information? For simplicity’s sake, assume the titles and authors’ names are unique, so AUTHOR_NAME is the primary key to the AUTHOR table.
You now have split BOOKSHELF into two tables: AUTHOR, with columns AUTHOR_NAME (the primary key) and COMMENTS, and BOOKSHELF, with a primary key of TITLE, and with columns PUBLISHER, CATEGORY1, CATEGORY2, CATEGORY3, RATING, and RATING_DESCRIPTION. A third table, BOOKSHELF_AUTHOR, provides the associations: Multiple authors can be listed for a single book and an author can write multiple books—known as a many-to-many relationship. Figure 1 shows these relationships and primary keys.
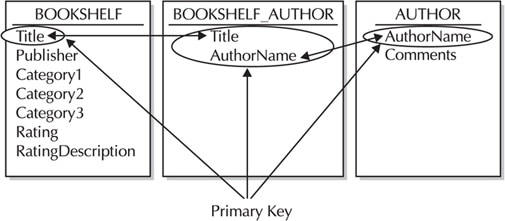
FIGURE 1. The BOOKSHELF, AUTHOR, and BOOKSHELF_AUTHOR tables
The next step in the normalization process, Second Normal Form, entails taking out data that are only dependent on a part of the key. If there are attributes that do not depend on the entire key, those attributes should be moved to a new table. In this case, RATING_DESCRIPTION is not really dependent on TITLE—it’s based on the RATING column value, so it should be moved to a separate table.
The final step, Third Normal Form, means getting rid of anything in the tables that don’t depend solely on the primary key. In this example, the categories are interrelated; you would not list a title as both Fiction and Nonfiction, and you would have different subcategories under the Adult category than you would have under the Children category. Category information is, therefore, moved to a separate table. Figure 2 shows the tables in the Third Normal Form.
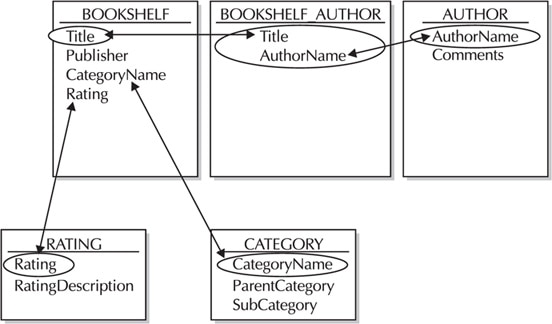
FIGURE 2. BOOKSHELF and related tables
Anytime the data is in Third Normal Form, it is already automatically in Second and First Normal Form. The whole process can, therefore, actually be accomplished less tediously than by going from form to form. Simply arrange the data so the columns in each table, other than the primary key, are dependent only on the whole primary key. Third Normal Form is sometimes described as “the key, the whole key, and nothing but the key.”
Navigating Through the Data
The BOOKSHELF database is now in the Third Normal Form. Figure 3 shows a sample of what these tables might contain. It’s easy to see how these tables are related. You navigate from one to the other to pull out information on a particular author, based on the keys to each table. The primary key in each table is able to uniquely identify a single row. Choose Stephen Jay Gould, for instance, and you can readily discover his record in the AUTHOR table because AUTHOR_NAME is the primary key.

FIGURE 3. Sample data from the BOOKSHELF tables
Look up Harper Lee in the AUTHOR_NAME column of the BOOKSHELF_AUTHOR table and you’ll see that she has published one novel, whose title is To Kill a Mockingbird. You can then check the PUBLISHER, CATEGORY, and RATING for that book in the BOOKSHELF table. You can check the RATING table for a description of the rating.
When you looked up To Kill a Mockingbird in the BOOKSHELF table, you were searching by the primary key for the table. To find the author of that book, you could reverse your earlier search path, looking through BOOKSHELF_AUTHOR for the records that have that value in the TITLE column—the column TITLE is a foreign key in the BOOKSHELF_AUTHOR table. When the primary key for BOOKSHELF appears in another table, as it does in the BOOKSHELF_AUTHOR table, it is called a foreign key to that table.
These tables also show real-world characteristics: There are ratings and categories that are not yet used by books on the bookshelf. Because the data is organized logically, you can keep a record of potential categories, ratings, and authors even if none of the current books use those values.
This is a sensible and logical way to organize information, even if the “tables” are written in a ledger book or on scraps of paper kept in cigar boxes. Of course, there is still some work to do to turn this into a real database. For instance, AUTHOR_NAME probably ought to be broken into FIRST_NAME and LAST_NAME, and you might want to find a way to show which author is the primary author, or if one is an editor rather than an author.
This whole process is called normalization. It really isn’t any trickier than this. Although some other issues are involved in a good design, the basics of analyzing the “normal” relationships among the various elements of data are just as simple and straightforward as I’ve explained. It makes sense regardless of whether a relational database or a computer is involved at all.
One caution needs to be raised, however. Normalization is a part of the process of analysis. It is not a design. The design of a database application includes many other considerations, and it is a fundamental mistake to believe that the normalized tables of the logical model are the “design” for the actual database. This fundamental confusion of analysis and design contributes to the stories in the press about the failure of major relational applications.
Leave a Reply