In Part 1 of this series, we looked at a brief description of in-memory tables, the syntax for creation, and benchmarked data insertion and update. Part 2 will continue with a concentration on the SELECT statement for benchmarking, and also touch on in-memory stored procedures.
In-Memory SELECT Performance
For the purpose of the following demos, I use SET STATISTICS IO, TIME ON, and also turn on Include Actual Execution Plan. For next demo, we’ll look at a simple SELECT:
SELECT COUNT(*) FROM Sales.SalesOrderDetail_inmem
SELECT COUNT(*) FROM Sales.SalesOrderDetail_inmemcs
SELECT COUNT(*) FROM Sales.SalesOrderDetail_disk
--note nonclustered index scan on SalesOrderDetail_Disk; note column store scan on cs table
inmem: CPU time = 1062 ms, elapsed time = 150 ms. -- query cost 40% --(table scan)
inmemCS: CPU time = 15 ms, elapsed time = 149 ms. -- query cost 7% --(columnstore scan) disk: CPU time = 1016 ms, elapsed time = 186 ms. -- query cost 53% --(nonclustered scan)
-- ~62x performance increase (with ColumnStore); roughly same performance in-memory vs disk based (remember disk base table completely in buffer cache)

Figure 1: Simple SELECT with COUNT Insert (© 2017 | ByrdNest Consulting)
I had several dialogues with Bob Ward at Microsoft® about the lackluster in-memory performance on this query. Following experimentation, Bob said that the compiler didn’t optimize in-memory table scans, and that performance should be compatible with a disk-based table. In the case of the in-memory table with a ColumnStore index, performance was significantly improved (62X, but with the baggage (extra RAM) of the ColumnStore index).
So, let’s now look at a few cases where the result set is only a few rows for a SELECT query.
SELECT * -- Don’t use a * in a Production Database
FROM Sales.SalesOrderDetail_inmem
WHERE SalesOrderID IN (51172,51847,53057)
SELECT *
FROM Sales.SalesOrderDetail_inmemcs
WHERE SalesOrderID IN (51172,51847,53057)
SELECT *
FROM Sales.SalesOrderDetail_disk
WHERE SalesOrderID IN (51172,51847,53057)
inmem: CPU time = 0 ms, elapsed time = 134 ms. -- query cost 15% (non-clustered index seek)
inmemCS: CPU time = 0 ms, elapsed time = 133 ms. -- query cost 15% (non-clustered index seek)
disk: CPU time = 0 ms, elapsed time = 122 ms. -- query cost 71% (clustered index seek)
-- roughly same performance for this size table (with disk-based table completely in buffer cache); capture extended event CPU time in microseconds, but still 0 microseconds
-- notice that don't need covering index for the in-memory table(s)

Figure 2: SELECT with WHERE clause (© 2017 | ByrdNest Consulting)
In-memory tables have roughly the same performance as disk-based tables (no physical reads in this example). Notice that the in-memory tables access a non-clustered index without covering columns. This is because covering columns are not needed for in-memory indexes; the index points to the actual memory address of the row, hence all columns are immediately accessible! I tried using extended events to capture CPU, which you can do in microseconds, but capture was not always consistent.
Another select statement with specified WHERE clause:
SELECT *
FROM Sales.SalesOrderDetail_inmem
WHERE ProductID = 717
SELECT *
FROM Sales.SalesOrderDetail_inmemcs
WHERE ProductID = 717
SELECT *
FROM Sales.SalesOrderDetail_disk
WHERE ProductID = 717
inmem: CPU time = 16ms, elapsed time = 181ms. -- query cost 1% (nonclustered index seek)
inmemCS: CPU time = 16ms, elapsed time = 268ms. -- query cost 1% (nonclustered index seek)
disk: CPU time = 62 ms, elapsed time = 150ms. -- query cost 99% (nonclustered index seek
with key lookup)
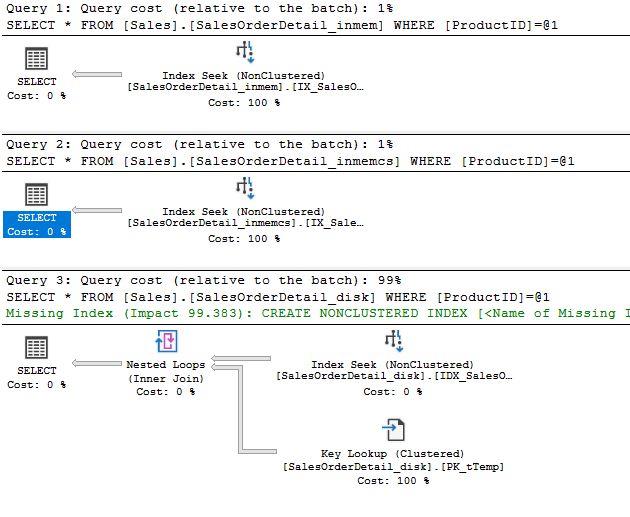
Figure 3: SELECT with WHERE Clause on ProductID (© 2017 | ByrdNest Consulting)
Even with a SELECT* we still have non-clustered indexes with no covering columns for the in-memory tables. Interestingly, for the disk-based table, even though there were 8938 rows returned, the optimizer still selected a key lookup, of course 8938/4973997 = 0.18%, which is well below the predictive criteria for switching to a clustered index scan. Query 3 also asked for a missing index, which essentially was a covering index for the entire table.
And now another simple SELECT with ModifiedDate in the WHERE clause:
SELECT *
FROM Sales.SalesOrderDetail_inmem
WHERE ModifiedDate BETWEEN '7/1/2007' AND '7/31/2007'
SELECT *
FROM Sales.SalesOrderDetail_inmemcs
WHERE ModifiedDate BETWEEN '7/1/2007' AND '7/31/2007'
SELECT *
FROM Sales.SalesOrderDetail_disk
WHERE ModifiedDate BETWEEN '7/1/2007' AND '7/31/2007'
inmem: CPU time=156 ms, elapsed time = 1,020 ms. -- query cost 7%; nonclustered index seek
inmemCS: CPU time=110 ms, elapsed time = 1,103 ms. -- query cost 3%; Columnstore scan
disk: CPU time=577 ms, elapsed time = 1,012 ms. -- query cost 90%; Clustered Index scan
-- ~3.5 performance increase
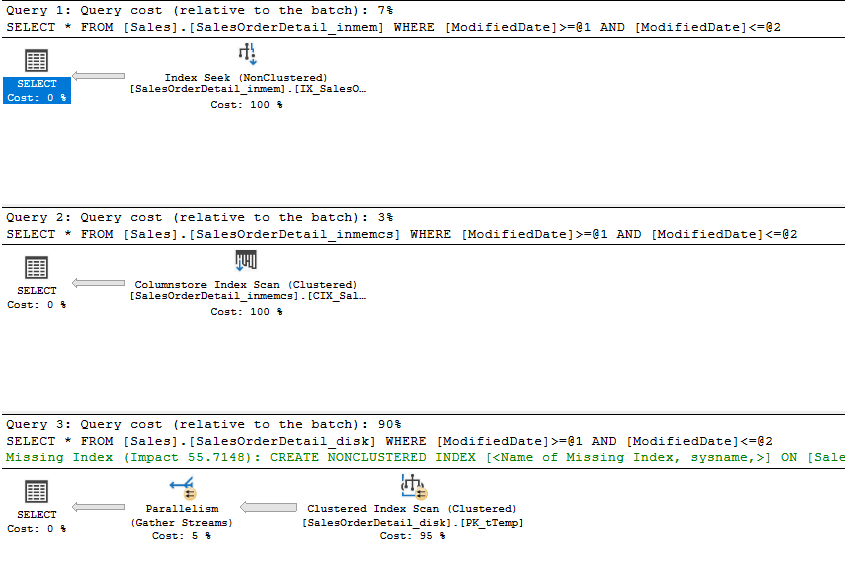
Figure 4: Simple SELECT with ModifiedDate (© 2017 | ByrdNest Consulting)
The ColumnStore index is starting to have an effect on the result. Query 1 uses an Index Seek, while Query 2 uses the ColumnStore clustered index scan. The disk-based Query 3 is forced to do a Clustered Index scan because all columns are being returned (SELECT *).
Now let’s look at creating an equivalent in-memory table to Sales.SalesOrderHeader and using it with joins to the three benchmark tables.
CREATE TABLE Sales.SalesOrderHeader_inmem(
SalesOrderID int NOT NULL IDENTITY(1,1),
RevisionNumber tinyint NOT NULL ,
OrderDate datetime NOT NULL INDEX IX_OrderDate NONCLUSTERED ,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
[Status] tinyint NOT NULL ,
OnlineOrderFlag BIT NOT NULL ,
PurchaseOrderNumber NVARCHAR(25) NULL,
AccountNumber NVARCHAR(15) NULL,
CustomerID int NOT NULL INDEX IX_SOH_CustomerID NONCLUSTERED,
SalesPersonID int NULL ,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL ,
TaxAmt money NOT NULL ,
Freight money NOT NULL ,
Comment nvarchar(128) NULL,
ModifiedDate datetime NOT NULL ,
CONSTRAINT PK_SalesOrderHeader_SalesOrderID_inmem PRIMARY KEY NONCLUSTERED HASH
(SalesOrderID) WITH (BUCKET_COUNT=2097152)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA)
Loading it:
SET IDENTITY_INSERT Sales.SalesOrderHeader_inmem ON;
INSERT Sales.SalesOrderHeader_inmem
(SalesOrderID,RevisionNumber,OrderDate,DueDate,ShipDate,[Status],OnlineOrderFlag,
PurchaseOrderNumber,AccountNumber,CustomerID,SalesPersonID,TerritoryID,BillToAddressID,
ShipToAddressID,ShipMethodID,CreditCardID,CreditCardApprovalCode,CurrencyRateID,SubTotal,
TaxAmt,Freight,Comment,ModifiedDate)
SELECT SalesOrderID,RevisionNumber,OrderDate,DueDate,ShipDate,[Status],OnlineOrderFlag,
PurchaseOrderNumber,AccountNumber,CustomerID,SalesPersonID,TerritoryID,BillToAddressID,
ShipToAddressID,ShipMethodID,CreditCardID,CreditCardApprovalCode,CurrencyRateID,
SubTotal,TaxAmt,Freight,Comment,ModifiedDate
FROM Sales.SalesOrderHeaderBig;
SET IDENTITY_INSERT Sales.SalesOrderHeader_inmem OFF;
This loaded 1,290,065 rows in seven seconds, so now we can join two in-memory tables and compare joins to similar disk-based tables:
SELECT soh.SalesOrderID, count(sod.SalesOrderDetailID)
FROM Sales.SalesOrderHeader_inmem soh
JOIN Sales.SalesOrderDetail_inmem sod
ON sod.SalesOrderID = soh.SalesOrderID
WHERE soh.OrderDate BETWEEN '7/1/2007' AND '12/31/2007'
GROUP BY soh.SalesOrderID
SELECT soh.SalesOrderID, count(sod.SalesOrderDetailID)
FROM Sales.SalesOrderHeader_inmem soh
JOIN Sales.SalesOrderDetail_inmemcs sod
ON sod.SalesOrderID = soh.SalesOrderID
WHERE soh.OrderDate BETWEEN '7/1/2007' AND '12/31/2007'
GROUP BY soh.SalesOrderID
SELECT soh.SalesOrderID, count(sod.SalesOrderDetailID)
FROM Sales.SalesOrderHeaderBig soh
JOIN Sales.SalesOrderDetailBig sod
ON sod.SalesOrderID = soh.SalesOrderID
WHERE soh.OrderDate BETWEEN '7/1/2007' AND '12/31/2007'
GROUP BY soh.SalesOrderID;</code
inmem: CPU time = 2,564 ms, elapsed time = 803 ms -- query cost 36%
inmemCS: CPU time = 125 ms, elapsed time = 602 ms. -- query cost 8% (cs only for
SalesOrderDetail)
disk: CPU time = 1,124 ms, elapsed time = 633 ms. -- query cost 56%
-- ~0.5 for performance decrease in-memory (non-column store); ~18x performance increase (with ColumnStore)
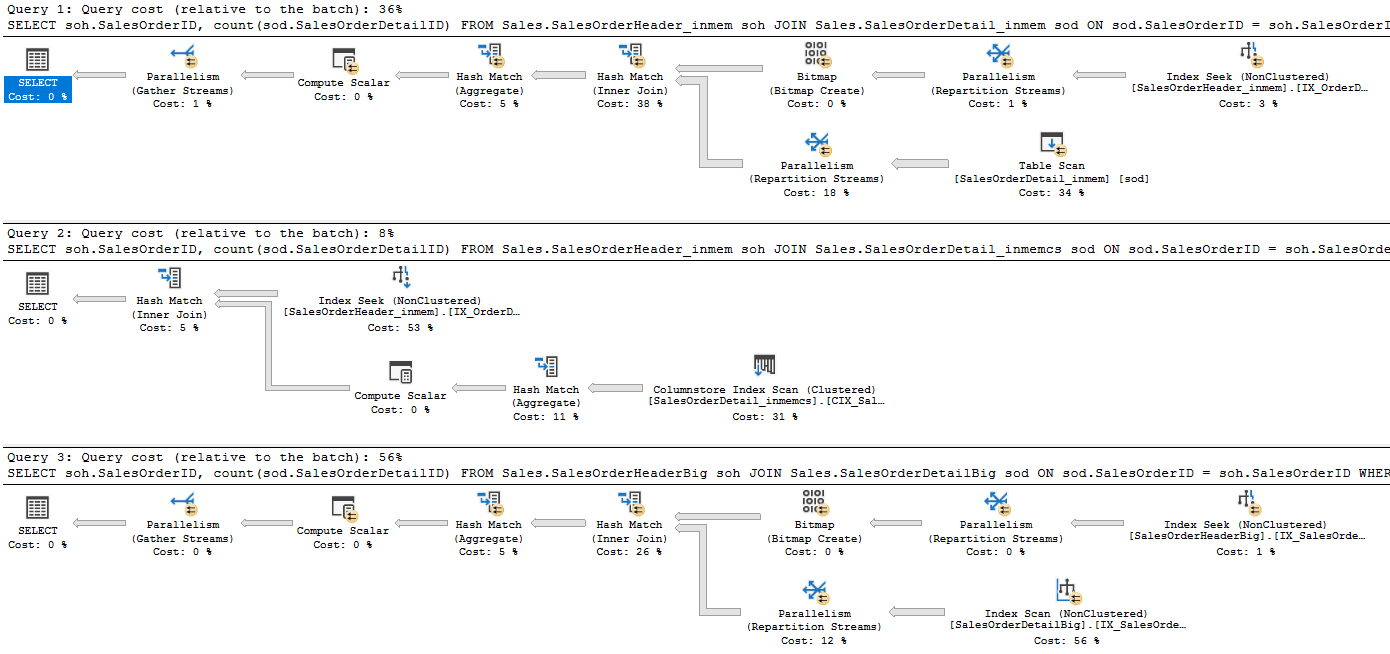
Figure 5: In-Memory vs Disk Joins (© 2017 | ByrdNest Consulting)
Oops! Once again, a table scan causes issues with an in-memory table. In Query 2, the optimizer takes advantage of the ColumnStore index. In Query 3 (disk-based), the optimizer took advantage of a non-clustered index for the count on SalesOrderDetailID. This is not the result I expected.
In-Memory Stored Procedures
As mentioned in Part 1, concurrency was a design objective so that optimistic concurrency content was developed for the possibility of a concurrency issue. For example, could two separate TSQL statements update the row at the same time? The possibility is remote—I have not been able to capture such an event—but there is a workaround to catch this possibility. It is to wrap each in-memory stored procedure with another stored procedure to catch any possibility of a concurrency error. Below is a template to catch the error; it is similar to what I use to work a retry when deadlocking occurs:
CREATE PROCEDURE usp_my_procedure @param1 type1, @param2 type2, ...
AS
BEGIN
-- number of retries – tune based on the workload
DECLARE @retry INT = 10
WHILE (@retry > 0)
BEGIN
BEGIN TRY
-- exec usp_my_native_proc @param1, @param2, ...
-- or
-- BEGIN TRANSACTION
-- …
-- COMMIT TRANSACTION
SET @retry = 0
END TRY
BEGIN CATCH
SET @retry -= 1
-- the error number for deadlocks (1205) does not need to be included for
-- transactions that do not access disk-based tables
IF (@retry > 0 AND error_number() in (41302, 41305, 41325, 41301/*, 1205*/)) --1205 is for deadlocking retries
BEGIN
-- these error conditions are transaction dooming - rollback the transaction
-- this is not needed if the transaction spans a single native proc execution
-- as the native proc will simply rollback when an error is thrown
IF XACT_STATE() = -1
ROLLBACK TRANSACTION
-- use a delay if there is a high rate of write conflicts (41302)
-- length of delay should depend on the typical duration of conflicting transactions
-- WAITFOR DELAY '00:00:00.001'
END
ELSE
BEGIN
-- insert custom error handling for other error conditions here
-- throw if this is not a qualifying error condition
;THROW
END
END CATCH
END
END
Normally I use this for any in-memory stored procedure where there is a DML operation. I also usually add code to log any concurrency issues found so that I can investigate after the fact that there may be an issue to look at.
Below is a sample in-memory stored procedure using same SELECT queries from previous demo:
CREATE PROCEDURE dbo.Test_Inmen (
@StartDate DATETIME,
@EndDate DATETIME )
WITH NATIVE_COMPILATION, SCHEMABINDING,EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = 'us_english')
SELECT soh.SalesOrderID, count(sod.SalesOrderDetailID)
FROM Sales.SalesOrderHeader_inmem soh
JOIN Sales.SalesOrderDetail_inmem sod
ON sod.SalesOrderID = soh.SalesOrderID
WHERE soh.OrderDate BETWEEN @StartDate AND @EndDate
GROUP BY soh.SalesOrderID
END
The WITH NATIVE_COMPILATION designates this as an in-memory stored procedure. Also required is the BEGIN ATOMIC WITH… clause. Otherwise, the stored procedure syntax is pretty much the same as a disk-based stored procedure. Besides the restriction of only in-memory tables, there are additional restrictions to include:
- EXISTS, MERGE, CASE, OUTER JOINS, OR, and NOT
- TempDB cannot be used
- ALTER PROCEDURE not supported
- CURSORS not supported
- CTEs not supported
To continue our benchmarking, let’s create the additional two stored procedures. Concurrency error checking is not required because no DML operations are being performed.
CREATE PROCEDURE Test_Inmencs
(@StartDate DATETIME,
@EndDate DATETIME )
WITH NATIVE_COMPILATION, SCHEMABINDING,EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = 'us_english')
SELECT soh.SalesOrderID, count(sod.SalesOrderDetailID)
FROM Sales.SalesOrderHeader_inmem soh
JOIN Sales.SalesOrderDetail_inmemcs sod
ON sod.SalesOrderID = soh.SalesOrderID
WHERE soh.OrderDate BETWEEN @StartDate AND @EndDate
GROUP BY soh.SalesOrderID
END
And
CREATE PROCEDURE dbo.Test_Disk (
@StartDate DATETIME,
@EndDate DATETIME )
AS
SELECT soh.SalesOrderID, count(sod.SalesOrderDetailID)
FROM Sales.SalesOrderHeaderBig soh
JOIN Sales.SalesOrderDetailBig sod
ON sod.SalesOrderID = soh.SalesOrderID
WHERE soh.OrderDate BETWEEN @StartDate AND @EndDate
GROUP BY soh.SalesOrderID
Now testing the in-memory sprocs and disk-based sproc yields:
DECLARE @StartDate DATETIME = '7/1/2007',
@EndDate DATETIME = '12/31/2007'
EXEC dbo.Test_Inmen @StartDate, @EndDate;
EXEC dbo.Test_Inmencs @StartDate, @EndDate;
EXEC dbo.Test_Disk @StartDate, @EndDate;
inmem: CPU time = 141 ms, elapsed time = 370 ms.
inmemCS: CPU time = 78 ms, elapsed time = 433 ms. (cs only for SalesOrderDetail)
disk: CPU time = 1047 ms, elapsed time = 504 ms. --query cost 100%
-- ~ 58x performance increase

Figure 6: Disk based sproc query plan (© 2017 | ByrdNest Consulting)
The results are interesting. The original Query 1 shows a significant performance improvement over the TSQL code syntax, but the ColumnStore (Query 2) still wins. This does suggest that Microsoft® does do a fair amount of query optimization in their stored procedure compiler. Also, note that there was no execution plan for the in-memory sprocs.
Summary of Results
Did Microsoft meet their design goals?
- Wanted 10x performance
- No, at best 4x for data insertions
- Yes, for deletes
- Yes, for data updates (no columnstore)
- Yes, for in-memory sprocs
- ColumnStore indexes may help, but need analyses where and when needed; does take extra RAM
- User interface nearly the same
- Concurrency goal pretty much there; hard to test for, but design seems to be appropriate
- In conversations with Bob Ward, “Memory optimized table access truly shines with concurrent workloads”
Okay, now what can I do with in-memory tables?
- High throughput and low latency transaction processing
- Large volumes of transactions, with consistent low latency for individual transactions (trading of financial instruments, sports betting, mobile gaming, and ad delivery)
- Data ingestion, including Internet of Things (IoT)
- Use memory-optimized tables for data ingestion
- Caching and session state
- NET session state is a very successful case for in-memory OLTP
- Tempdb object replacement
- Memory-optimized table variables and non-durable tables typically reduce CPU and completely remove log IO when compared with traditional table variables and #temp tables
- Extract Transform Load (ELT)
- Use non-durable memory-optimized tables for data staging. They completely remove all IO, and make data access more efficient
Cons for in-memory tables/procedures:
- Need RAM (lots of it)
- May cause some snapshot, mirroring, backup/restore issues on other DB servers
- Enterprise Edition
- Darn, all the good stuff is in Enterprise Edition
- Can use in SS2016 Standard Edition, SP1 and SS2017 Standard Edition, but really do need to closely monitor RAM utilization
- Current limitations
- Need to plan well for max allowable RAM for in-memory tables
- Need to monitor in-memory table growth
- In-memory tables not optimized for table scans
- As confirmed by the benchmark tests and also confirmed by Bob Ward
So, do the pros outweigh the cons? I think so, and I’m just itching to find a customer that will allow me to implement them.
Leave a Reply