I’ve always been fascinated by performance, and my careers and hobbies have shown this. I’ve been a rocket scientist, sports car driver, USAF fighter pilot, and now a SQL Server® geek. When in-memory tables first came out in SQL Server 2014, I was highly intrigued by the prospect of something that did not require the “baggage” of accessing a spinning drive and traversing the SQL Server index b-trees.
This paper provides a brief description of in-memory tables, a concentration on benchmarking a series of T-SQL queries with in-memory table performance, and a performance comparison to a corresponding disk-based table. I had intended this to be a single blog, but the breadth of the topic has made this a two parter.
These tests were conducted on an i7 dual processor machine with 64 GB ram, 1TB SSD, and 1TB spinning drive. The disk-based queries were based on tables stored on the spinning drive. However, with this much memory for a laptop, all performance reads were essentially logical reads. Physical reads are pointed out where encountered.
These tests were an eye-opener for me. A couple of the benchmark tests gave results I didn’t expect. I corresponded with Bob Ward from Microsoft® about the performance, and he was gracious enough to point out what was happening and why. Portions of those discussions can be found in Part 2.
Technical Overview In-Memory Tables?
Memory (RAM) has been growing increasingly cheaper over the past 20 years. What would have cost a considerable amount then is now affordable, even to smaller businesses. For example, you can now purchase a Dell® PowerEdge® R330 Rack Server with 1TB ram for less than $15,000 (storage not included).
CPU processors have leveled off in performance (ops/sec). We are now down at the atomic level for processing, and there isn’t more that can be done to make them faster, other than to parallelize the tasks.
Almost all the current relational databases are based on 1980s design. There just hasn’t been much to improve their design to take advantage of cheaper and more processors and cheaper memory.
So, the big question is what can be done to improve current database performance? One answer is to reduce the number of CPU cycles needed to accomplish the same tasks currently being performed. This is exactly what Microsoft did.
Their design goals were:
- Accomplish same operations with fewer instructions
- Integrate new approach into existing compiler/query optimizer
- Reduce concurrency issues with lock-free transactions
- Speed, speed, speed (desired goal was a 10x improvement in performance)
So, their approach was to construct in-memory tables using C# data structures. This data—clustered and non-clustered—would be there without need for a b-tree; data could be accessed directly through a memory location. This is not the old “pinned table” methodology, but a new approach in accessing table data that makes data more accessible with fewer instructions.
All in-memory table data, including heap, clustered, and non-clustered, exists in memory and can be accessed directly without the need to traverse a b-tree or a buffer pool. In-memory tables now exist as DLLs and are accessed directly with machine instructions.
The big question is how is the data refreshed when restarting SQL Server? There are two types of in-memory table structures. One is Schema Only and the other is Schema and Data. In the Schema Only structure, when restarting SQL Server, the table is created without data. This sounds like a good option for an ETL staging table to me. In the Schema and Data tables, the table is restored and the data is streamed back from a disk-based file that was specified upon table creation. This may cause a longer restart time, but is well worth the improved performance (shown later in this presentation).
Finally, Microsoft wanted to reduce waits for high concurrency scenarios. They applied their multi-version optimistic concurrency control with full ACID support. The core engine for in-memory tables uses lock-free algorithms with versioning. This means no lock manager, latches, or spinlocks. There still exists a conflict possibility and the methodology to handle that is discussed in Part 2. By using a more optimistic approach, the possibility for frictionless scale-up, (more processors) is increased.
While the above is a great start, there was still a need to go even faster using in-memory stored procedures. This was implemented with a C# code generator using highly aggressive code optimization. So now, invoking an in-memory stored procedure is just a DLL entry-point. Currently, the major restriction for in-memory stored procedures is that they can only reference in-memory tables and not disk-based tables.
Finally, the last Microsoft design objective was to seamlessly integrate all this with the current SQL Server tools. That is, to add the in-memory tables with minimal impact on user manageability, administration, and development practices by having integrated (in-memory tables and disk-based tables) queries and transactions and minimal impact in HA and backup/restore administration.
Now that we know a little about how they work, let’s look at how to create and use in-memory tables.
In-memory Table Create Syntax
The demos below use a modified version of AdventureWorks2012 that I call AdventureWorks2012big. It is essentially the original database with two additional tables: Sales.SalesOrderHeaderBig and Sales.SalesOrderDetailBig using a slightly modified script I downloaded from http://sqlskills.com/blogs/jonathan. This increased the size of Sales.SalesOrderHeaderBig from 31,465 rows to 1,290,065 and Sales.SalesOrderDetailBig from 121,317 rows to 4,973,997. This was necessary for the demos to show scalability, as well as giving some reasonable statistics IO and Time values. The database was upgraded to compatibility 14.0 (SS 2017); however, I’ve noticed almost no change in performance from SS 2014 to SS 2016 to SS 2017.
The statements below create a new file group (for data streaming) and a file for data to stream in and out. This is necessary to establish in-memory tables for the database.
IF NOT EXISTS (SELECT * FROM sys.data_spaces WHERE TYPE='FX')
ALTER DATABASE CURRENT ADD FILEGROUP [AdventureWorks2012Big_mod]
CONTAINS MEMORY_OPTIMIZED_DATA;
GO
IF NOT EXISTS (SELECT *
FROM sys.data_spaces ds
JOIN sys.database_files df
ON ds.data_space_id=df.data_space_id
WHERE ds.TYPE='FX')
ALTER DATABASE CURRENT
ADD FILE (name='AdventureWorks2012Big_mod',
filename='D:\Database2017\Data\AdventureWorks2012Big_mod')
TO FILEGROUP [AdventureWorks2012Big_mod];
Microsoft then recommends that you automatically map all lower isolation levels, including read committed, to SNAPSHOT:
ALTER DATABASE CURRENT SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON
This setting is important when using transactions involving in-memory tables and disk-based tables, the so-called “cross-container transactions.” This elevates the isolation level for every cross-container transaction with lower isolation levels.
Let’s now create an in-memory table:
CREATE TABLE [Sales].[SalesOrderDetail_inmem](
[SalesOrderID] [int] NOT NULL INDEX IXSalesOrderDetail_inmem__SalesOrderID NONCLUSTERED,
[SalesOrderDetailID] [int] NOT NULL IDENTITY(1,1),
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL INDEX IX_SalesOrderDetail_inmem_ProductID NONCLUSTERED,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL ,
[ModifiedDate] [datetime] NOT NULL INDEX IX_SalesOrderDetail_inmem_ModifiedDate
NONCLUSTERED,
CONSTRAINT [imPK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID] PRIMARY KEY NONCLUSTERED
HASH ([SalesOrderID],[SalesOrderDetailID]) WITH (BUCKET_COUNT=8388608) )
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA);
You use similar syntax when creating a disk-based table. Non-clustered, single column indexes are defined as usual. The major differences here are the Primary Key definition with HASH and a bucket count, and also the last statement (WITH) turning on memory optimized and specifying the DURABILITY, in this case SCHEMA_AND_DATA. As specified earlier, with the schema_and_data specification, the data is retained between SQL Server shutdowns and startups. If an empty table is required, SCHEMA_ONLY would have been specified. Schema-Only tables can also be used in lieu of temporary tables.
There is an excellent article on determining bucket count, but general guidance is 1-2 times the number of distinct index values in the index key. I’ve found from a performance and storage point of view that generally hash indexes are most beneficial for the Primary Key and in a WHERE clause when looking for a specific row. For in-memory tables, Microsoft takes the specified HASH value to the next power of 2. So, for 4,973,997 distinct rows, POWER(2,22) = 4,194,304 and POWER(2,23) = 8,388,608 hence this bucket count. Even if I had specified the bucket count = 4,973,997, the actual implementation table would have an 8,388,608-bucket count.
For the purpose of these demos, I am going to create a duplicate in-memory table with a column store clustered index, as shown below:
CREATE TABLE [Sales].[SalesOrderDetail_inmemcs](
[SalesOrderID] [int] NOT NULL INDEX IXSalesOrderDetail_inmem__SalesOrderID NONCLUSTERED,
[SalesOrderDetailID] [int] NOT NULL IDENTITY(1,1),
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL INDEX IX_SalesOrderDetail_inmem_ProductID NONCLUSTERED,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL ,
[ModifiedDate] [datetime] NOT NULL INDEX IX_SalesOrderDetail_inmem_ModifiedDate
NONCLUSTERED,
CONSTRAINT [imPK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID] PRIMARY KEY NONCLUSTERED
HASH ([SalesOrderID],[SalesOrderDetailID]) WITH (BUCKET_COUNT=6000000) )
WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA);
ALTER TABLE [Sales].[SalesOrderDetail_inmemcs] ADD INDEX CIX_SalesOrderDetail_inmemscs CLUSTERED COLUMNSTORE; --add ColumnStore index
And for purpose of benchmarking, we will create an equivalent disk-based table with similar indexes:
CREATE TABLE [Sales].[SalesOrderDetail_disk](
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL IDENTITY(1,1),
[CarrierTrackingNumber] [nvarchar](25) NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL ,
[ModifiedDate] [datetime] NOT NULL ,
CONSTRAINT [PK_tTemp] PRIMARY KEY CLUSTERED
([SalesOrderID] ASC,[SalesOrderDetailID] ASC));
CREATE NONCLUSTERED INDEX IDX_SalesOrder_SalesOrderID
ON [Sales].[SalesOrderDetail_disk] (SalesOrderID)
CREATE NONCLUSTERED INDEX IDX_SalesOrder_Product
ON [Sales].[SalesOrderDetail_disk] (ProductID)
INCLUDE (SalesOrderID,UnitPrice)
CREATE NONCLUSTERED INDEX IDX_SalesOrder_ModifiedDate
ON [Sales].[SalesOrderDetail_disk] (ModifiedDate)
In-Memory Data Inserts (and Delete)
For all of the following demos, I use SET STATISTICS IO, TIME ON, and also turn on Include Actual Execution Plan. For the first demo, we’ll look at a BULK INSERT:
BULK INSERT Sales.SalesOrderDetail_inmem --485,268 rows
FROM 'D:\Misc\Test\SalesOrderDetailTabDelimited.txt'
WITH (FIELDTERMINATOR = '\t',ROWTERMINATOR = '\n' );
BULK INSERT Sales.SalesOrderDetail_inmemcs --485,268 rows
FROM 'D:\Misc\Test\SalesOrderDetailTabDelimited.txt'
WITH (FIELDTERMINATOR = '\t',ROWTERMINATOR = '\n' );
BULK INSERT Sales.SalesOrderDetail_disk --485,268 rows
FROM 'D:\Misc\Test\SalesOrderDetailTabDelimited.txt'
WITH (FIELDTERMINATOR = '\t',ROWTERMINATOR = '\n' );
Table 'SalesOrderDetail_disk'. Scan count 0, logical reads 43099, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 3, logical reads 1392318, physical reads 0, read-ahead reads 6888, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
inmem: CPU time = 1,547 ms, elapsed time = 1,675 ms. -- Query cost 26%
inmemCS: CPU time = 1,578 ms, elapsed time = 1,742 ms. -- Query cost 26%
disk: CPU time = 4,235 ms, elapsed time = 4,591 ms. -- Query cost 49%
--~2.7 performance increase!
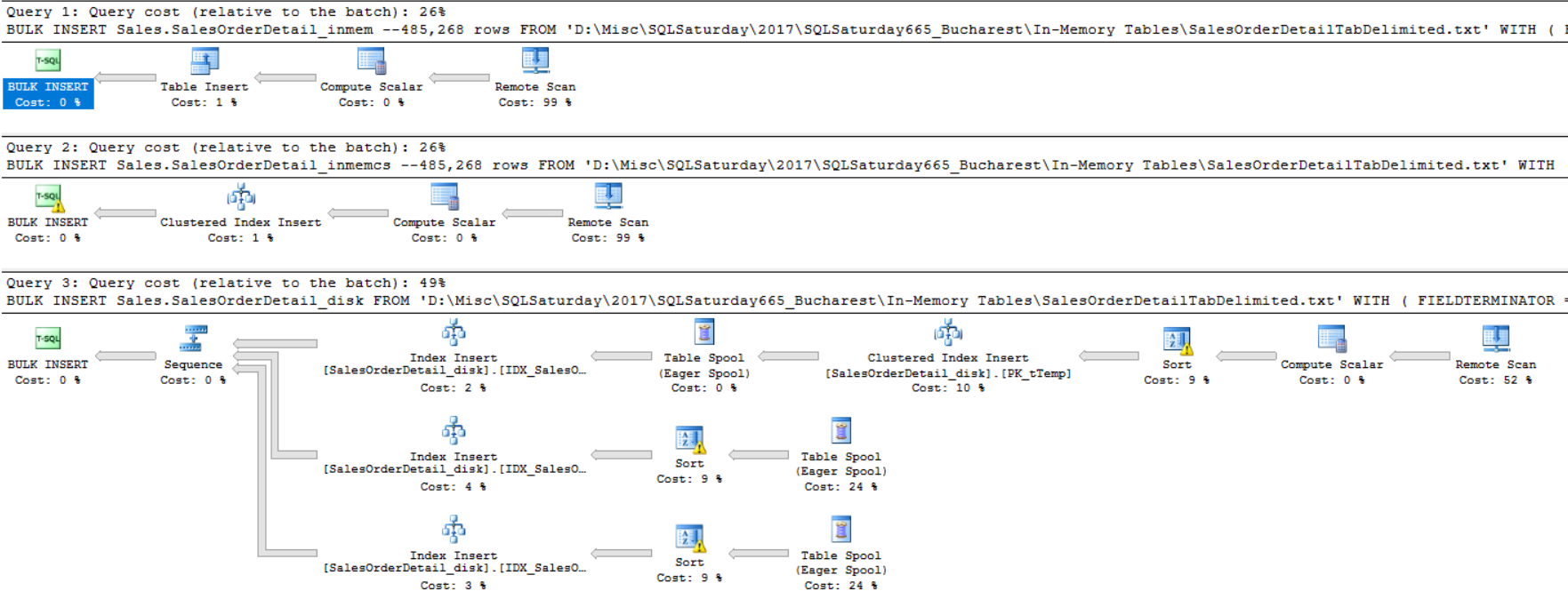
Figure 1: Query Plan for Bulk Insert (© 2017 | ByrdNest Consulting)
The above format is what I will display for all the benchmarking demos. Where applicable, I’ll show the SET STATISTICS results, including CPU, Elapsed, and Query cost for the three tables.
Wow! Putting data into a table allows nearly a 2.7 percent increase in performance.
Now let’s look at emptying a table.
DELETE Sales.SalesOrderDetail_inmem; --485,268 rows
DELETE Sales.SalesOrderDetail_inmemcs; --485,268 rows
DELETE Sales.SalesOrderDetail_disk; --485,268 rows
Table 'SalesOrderDetail_disk'. Scan count 1, logical reads 7369470, physical reads 0, read-ahead reads 7,...
/*
inmem: CPU time = 172 ms, elapsed time = 191 ms. -- query cost 7%
inmemCS: CPU time = 156 ms, elapsed time = 202 ms. -- query cost 7%
disk: CPU time = 5,500 ms, elapsed time = 5,765 ms. -- query cost 86%
-- Wow! ~35x performance increase

Figure 2: DELETE Query Plan Insert (© 2017 | ByrdNest Consulting)
Interestingly, the Truncate Table command is not supported for In-Memory tables. But with this type of speed, I am not sure it is needed. In any case, all rows are logged in the transaction log. Granted, the transaction log still needs to stream the data before the transaction is complete, but I’ve not noticed any decrement to transaction log performance for any of these benchmark demos.
Now that the tables are empty, let’s go back and insert almost 5 million rows to each table from a disk- based table:
SET IDENTITY_INSERT Sales.SalesOrderDetail_inmem ON;
INSERT Sales.SalesOrderDetail_inmem
(SalesOrderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,ModifiedDate)
SELECT SalesOrderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,ModifiedDate
FROM Sales.SalesOrderDetailBig --4,973,997 rows
SET IDENTITY_INSERT Sales.SalesOrderDetail_inmem OFF;
SET IDENTITY_INSERT Sales.SalesOrderDetail_inmemcs ON;
INSERT Sales.SalesOrderDetail_inmem
(SalesOrderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,ModifiedDate)
SELECT SalesOrderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,ModifiedDate
FROM Sales.SalesOrderDetailBig --4,973,997 rows
SET IDENTITY_INSERT Sales.SalesOrderDetail_inmemcs OFF;
SET IDENTITY_INSERT Sales.SalesOrderDetail_Disk ON;
INSERT Sales.SalesOrderDetail_inmem
(SalesOrderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,ModifiedDate)
SELECT SalesOrderID,SalesOrderDetailID,CarrierTrackingNumber,OrderQty,ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,ModifiedDate
FROM Sales.SalesOrderDetailBig
SET IDENTITY_INSERT Sales.SalesOrderDetail_Disk OFF;
look at query cost from three inserts; optimizer does know about memory optimized tables for INSERTS! Also note physical reads on first query
notice index inserts in 3rd query plan
--00:01:41 total query batch time
inmem: CPU time = 13,125 ms, elapsed time = 39,944 ms., 3 physical reads Query cost 4%
inmemCS: CPU time = 13,453 ms, elapsed time = 15,767 ms., Query cost 4%
disk: CPU time = 46,752 ms, elapsed time = 44,062 ms., Query cost 92%
almost 4x performance increase

Figure 3: Large Insert Query Plan Insert (© 2017 | ByrdNest Consulting)
Both of the inserts indicate much better performance for data inclusion. It sure does make a case for using in-memory tables for data staging or load tables, and possibly also for replacing temporary tables (SCHEMA_ONLY).
HASH Parameters
Now let’s look at the hash indexes and bucket count parameters with the query.
SELECT object_name(hs.object_id) AS 'object name',
i.name as 'index name',
hs.total_bucket_count,
hs.empty_bucket_count,
floor((cast(empty_bucket_count as float)/total_bucket_count)*100) 'empty_bucket_%',
hs.avg_chain_length,
hs.max_chain_length
FROM sys.dm_db_xtp_hash_index_stats AS hs
JOIN sys.indexes AS i
ON hs.object_id=i.object_id AND hs.index_id=i.index_id
ORDER BY 1,2;
This yields:
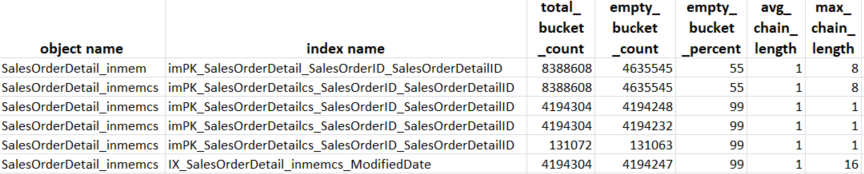
Figure 4: Hash Bucket Parameters (© 2017 | ByrdNest Consulting)
When I first started the benchmarking process, I had hash indexes on SalesOrderID and ProductID, but replaced them with non-clustered indexes. Although the white paper doesn’t specifically say so, duplicate values in hash buckets causes issues, including the fact that more values in a specific bucket causes performance issues. As you can see above, there is at least one bucket with eight values in it. Normally, you would want a bucket count where the average chain length is five or less. Remember, the more buckets you have, the more RAM memory the index is taking. Note that the total bucket count for both tables is now 8388608, even though the second table (inmemcs) was created with a specified bucket count of 6000000.
In SQL Server 2014, the above query only yielded the first two rows. In SQL Server 2016 columnstore indexes were added and the additional four rows added to the result set (for the table having a defined columnstore index). This is an active bug with Microsoft (ID=2979362). For now, ignore the results in rows 3, 4, 5, and 6.
UPDATE performance
Let’s look at update performance on five million rows:
UPDATE Sales.SalesOrderDetail_inmem
SET UnitPrice = UnitPrice * 1.05;
UPDATE Sales.SalesOrderDetail_inmemcs
SET UnitPrice = UnitPrice * 1.05;
UPDATE Sales.SalesOrderDetail_Disk
SET UnitPrice = UnitPrice * 1.05;
giving results of
inmem: CPU time = 11,359 ms, elapsed time = 12,475 ms. -- Query cost: 3%
inmemCS: CPU time = 23,985 ms, elapsed time = 25,542 ms. -- Query cost: 2% --hmmmm,
--ColumnStore takes longer for update
disk: CPU time = 126,953 ms, elapsed time = 128,314 ms. -- Query cost: 95% --but in-
--memory still much, much faster
-- ~11x performance increase (non-ColumnStore); ~5x performance increase (with ColumnStore)

Figure 5: Large Update (© 2017 | ByrdNest Consulting)
Update performance for the in-memory table (non-ColumnStore) provided about an 11X performance increase while the in-memory table with ColumnStore was only about a 5X performance increase. This is most likely due to the rebuild of the entire ColumnStore index, which includes all columns in the table. In any case, both in-memory tables are considerably faster than the disk-based table. Also, note the Sort operator for the disk-based table in the query plan; the index rebuild was costly.
Here’s an interesting tidbit: When I ran the above UPDATE statements on a laptop with 8gb ram, the in-memory tables ran slower. Upon investigation, I found Windows® was paging memory causing the slowdown.
Let’s look at another Update with a join to a disk-based table:
UPDATE sod
SET UnitPrice = UnitPrice * 1.05
FROM Sales.SalesOrderDetail_inmem sod
JOIN Production.Product p
ON p.ProductID = sod.ProductID
WHERE p.Name = 'HL Mountain Tire';
UPDATE sod
SET UnitPrice = UnitPrice * 1.05
FROM Sales.SalesOrderDetail_inmemcs sod
JOIN Production.Product p
ON p.ProductID = sod.ProductID
WHERE p.Name = 'HL Mountain Tire';
UPDATE sod
SET UnitPrice = UnitPrice * 1.05
FROM Sales.SalesOrderDetail_disk sod
JOIN Production.Product p
ON p.ProductID = sod.ProductID
WHERE p.Name = 'HL Mountain Tire';
The TSQL syntax remains the same when joining in-memory tables to disk-based tables. As you may recollect, this was one of the design goals of Microsoft. The company designated these in-memory tables joined to disk-based tables as Interop queries. The results are:
inmem: CPU time = 141 ms, elapsed time = 200 ms. -- query cost 10% --nonclustered beats CS for this query
inmemCS: CPU time = 328 ms, elapsed time = 423 ms. -- query cost 10%
disk: CPU time = 1,469 ms, elapsed time = 1,520 ms. -- query cost 81% --note index update in query plan
-- ~12x performance increase (non ColumnStore); ~5x performance increase (with ColumnStore)
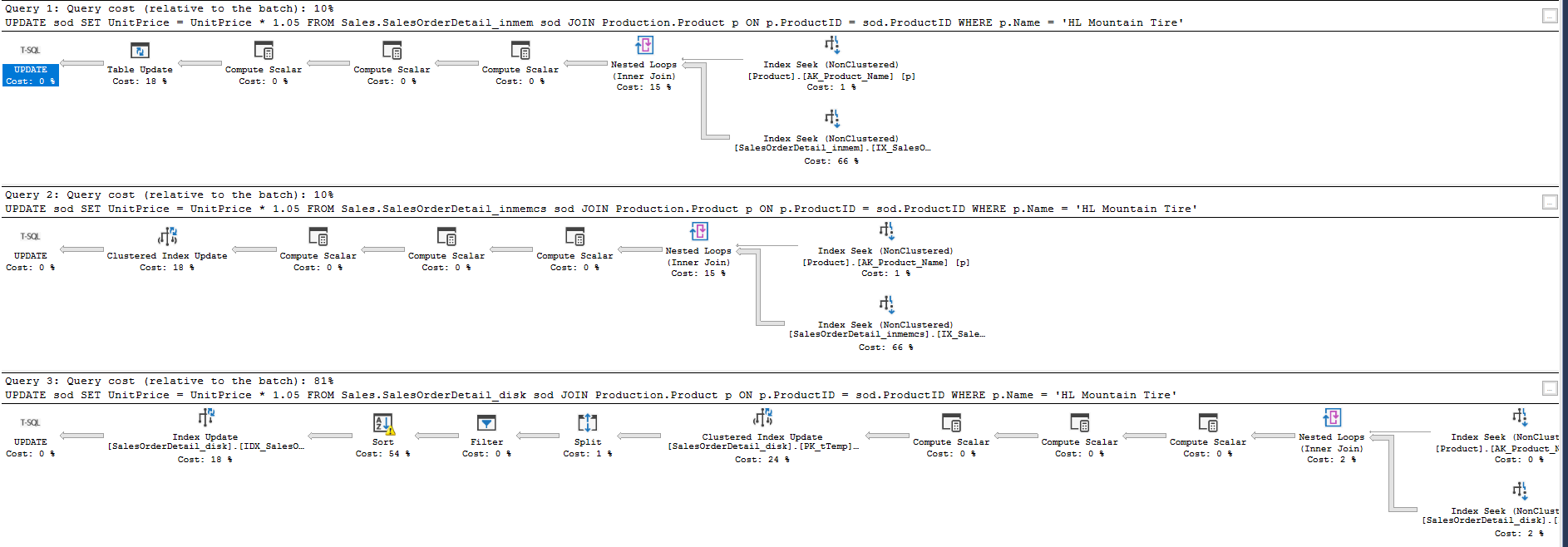
Figure 6: Update with Join to Disk Base table (© 2017 | ByrdNest Consulting)
We still see similar performance as before.
Summary to Date
The concludes Part 1 of this series. Performance has been fairly spectacular so far. In Part 2, we will look at the performance of various SELECT statements as well as in-memory stored procedures. We will also see why I have the question mark in the title. Stay tuned!
Leave a Reply