Read Part 1
Read Part 3
This is a continuation of Climbing the SQL Server Index B-tree. In Part 1, we dove down into the SQL Server® pages for a Clustered Index in the Sales.SalesOrderDetail table in the AdventrueWorks2012 database. In this paper, we will look at the data pages of the same table/database for unique-nonclustered and nonclustered indexes. We do this in an effort to ascertain how the SQL optimizer might use them and to gain some insight from a performance advantage.
This paper is not to replace or even compete with more technological index papers by Paul Randall or Kimberly Tripp (see references). Its purpose is mainly to try and understand how SQL Server implements indexes, their underlying structure, and where performance benefits might lie from a layman’s viewpoint.
The TSQL script used to evaluate the indexes and the discussion below can be copied from this post.
It is well-commented so that similar results can be obtained on the reader’s computer (this script applies to Parts 1 and 2). I will note, however, that depending on SQL Server configuration and local computer memory, that specific page IDs may vary from that discussed here (however, the actual data values should remain constant).
Unique NonClustered Index
To create a unique single column, let’s define a unique computed column, persist it, and create a unique index. Since SalesOrderDetailID is an identity column, we can use it to establish uniqueness:
ALTER TABLE Sales.SalesOrderDetail ADD uSalesOrderDetail AS (SalesOrderDetailID + 100) Persisted;
GO
CREATE UNIQUE NONCLUSTERED INDEX IDX_SalesOrderDetail_uSalesOrderDetail
ON Sales.SalesOrderDetail(uSalesOrderDetail)
Run the following to determine the index id:
SELECT ID,Name,Dpages,reserved,used,rowcnt,indid
FROM sys.sysindexes
WHERE [Name] IN ('IDX_SalesOrderDetail_uSalesOrderDetail');
yields an indid (Index ID) = 5
Looking at the index contents:
SELECT OBJECT_NAME(object_id), index_id, partition_id,allocated_page_page_id, is_iam_page,
page_type, page_type_desc, page_level, next_page_file_id, next_page_page_id,
previous_page_file_id, previous_page_page_id, is_page_compressed
FROM sys.dm_db_database_page_allocations (DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'), 5,1,'Detailed')
WHERE page_level IS NOT NULL
ORDER BY (page_level+page_type) DESC,allocated_page_page_id
We get

Figure 1: sys.dm_db_database_page_allocations results unique index (© 2017 | ByrdNest Consulting)
There is only one page at page level 1 and that is the root node. There are no intermediate levels, since the remaining pages are all at page level = 0. So, looking at the root node (page) and second result set:

Figure 2: Root page b-tree unique index (© 2017 | ByrdNest Consulting)
Wow! The root level is not carrying the Primary Key—hence the advantage of Unique Indexes. In this case, saving two columns of data is not necessary to get to the leaf level, allowing the root page to be more compacted (potentially less logical and physical IO).
Traversing the next child page (leaf level, 25504)
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,25504,3) WITH TABLERESULTS
GO
DBCC TRACEOFF(3604)
We get (in the second result set):
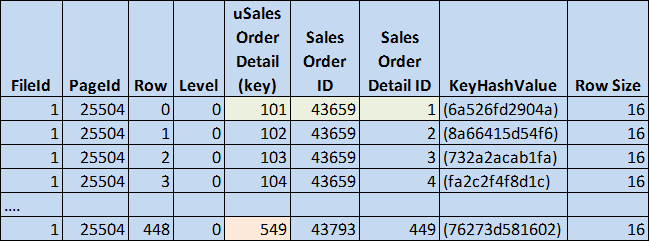
Figure 3: Leaf Level for b-tree unique index (© 2017 | ByrdNest Consulting)
And we can see that the last uSalesOrderDetail is 549 (one less than next boundary). Also note that the Primary Keys SalesOrderID and SalesOrderDetailID are retained to point back to the actual table (Primary Key).
NonClustered Index
Consider the following NonClustered Index (covering):
CREATE NONCLUSTERED INDEX IDX_SalesOrderDetail_ModifiedDate
ON Sales.SalesOrderDetail(ModifiedDate)
INCLUDE (CarrierTrackingNumber,OrderQty, ProductID)
Running
SELECT ID,Name,Dpages,reserved,used,rowcnt,indid
FROM sys.sysindexes
WHERE [Name] IN ('IDX_SalesOrderDetail_ModifiedDate');
Yields an indid (index id) = 8
Looking at the index contents:
SELECT OBJECT_NAME(object_id), index_id, partition_id,allocated_page_page_id, is_iam_page,
page_type, page_type_desc, page_level, next_page_file_id, next_page_page_id,
previous_page_file_id, previous_page_page_id, is_page_compressed
FROM sys.dm_db_database_page_allocations (DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'), 8,1,'Detailed')
WHERE page_level IS NOT NULL
ORDER BY (page_level+page_type) DESC,allocated_page_page_id
We get (partial result):
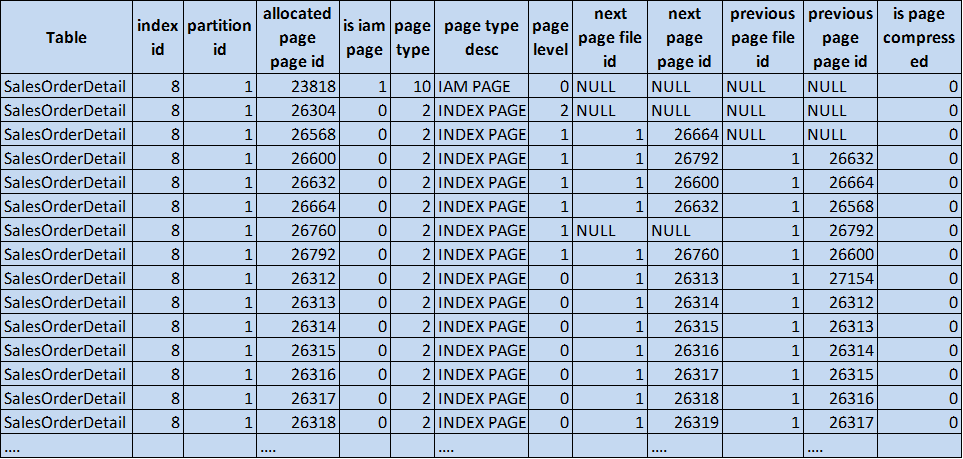
Figure 4: sys.dm_db_database_page_allocations results nonclustered index (© 2017 | ByrdNest Consulting)
Note that now there is the root node at level 2 and six intermediate nodes at level 1, before getting to the leaf nodes at level 0. You might ask why are there so many more intermediate nodes than in the unique index above. Let’s look at the root node on page 26,304:
–Intermediate Level 2
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,26304,3) WITH TABLERESULTS
GO
DBCC TRACEOFF(3604)
GO
Yielding in the second result set:

Figure 5: Root node nonclustered index (© 2017 | ByrdNest Consulting)
There are eight intermediate node values indicated below the root node. Note that the page contains not only the ModifiedDate column but also the Primary Key columns of SalesOrderID and SalesOrderDetailID. The Primary Keys are needed to maintain the uniqueness of each row in the index, as well as pointing back to the clustered index. Traversing down the right (NULL,NULL,NULL) boundary as before, we now look at page 26568 with:
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,26568,3) WITH TABLERESULTS
GO
DBCC TRACEOFF(3604)
yielding (second result set, 282 rows)
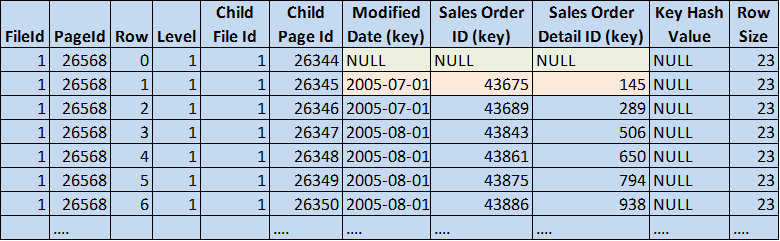
Figure 6: Intermediate node nonclustered index (© 2017 | ByrdNest Consulting)
Continuing our (NULL,NULL,NULL) boundary traversal:
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,26344,3) WITH TABLERESULTS
GO
DBCC TRACEOFF(3604)
And looking at the second result set (leaf level), we get:

Figure 7: Leaf level nonclustered index index (© 2017 | ByrdNest Consulting)
Note that the last row here is just under the boundary for (2005-07-01,43675,145). There are 144 rows here in this leaf node, while there were only 84 in the clustered index.
For fun, let’s look at the following non-clustered index:
CREATE NONCLUSTERED INDEX IDX_SalesOrderDetail_ModifiedDate2 on
Sales.SalesOrderDetail(ModifiedDate)
INCLUDE (CarrierTrackingNumber,OrderQty, ProductID,
SpecialOfferID,UnitPrice,UnitPriceDiscount,LineTotal,rowguid)
This is a covering index I would almost never use—it includes all columns in the original table, plus a computed column.
If we do the same type drill down as above, we get the following results at the first leaf node:
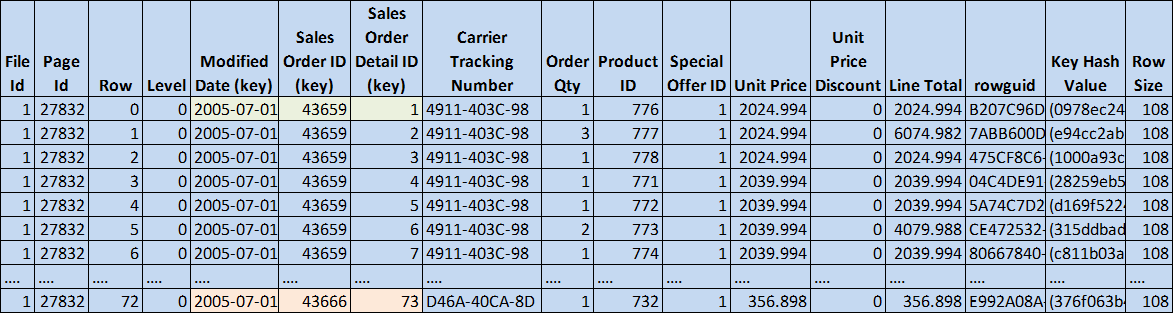
Figure 8: Leaf node full covering nonclustered index index (© 2017 | ByrdNest Consulting)
Hmmm, note that the LineTotal (a computed, non-persisted column) is included in the covering index. Also, there are only 73 rows per page as opposed to 84 rows per page in the clustered index. Part of this is due to the LineTotal column being included, but I think there is something else that is also contributing (I couldn’t make the column sizes add up exactly).
So what did we learn?
- Unique nonclustered indexes are possibly more efficient, since the Primary Key does not have to be included in the intermediate levels.
- While covering indexes really can help with performance, they do come with a cost. The INCLUDE columns cause more data to be stored per row, thus less number of rows in a leaf data page.
- In a nonclustered index, the total width of the Primary Key will affect how many pages (and possibly levels) are needed to traverse from the root level to the leaf level. The narrower the width, the more data (and boundaries) can be stored per page.
- Although indexes can usually help performance, they do come with a cost—both in additional memory and DML (data modification language) operations. Most likely an insert, update, or delete will not only affect the clustered index, but also may cause additional index maintenance on one or more of the existing indexes.
References (in no particular order or preference):
http://blog.matticus.net/2013/04/undocumented-sql-fun-with-dbcc-page.html
https://www.sqlskills.com/blogs/paul/category/indexes-from-every-angle/
[…] Read Part 2 […]