Read Part 2
Read Part 3
The term “geek” applies to me because I am always wondering/tinkering with things that I don’t readily understand. Recently, I’ve become intrigued with “what’s under the covers” with SQL Server Indexes. Part 1 of this paper will dive down and look at the important items on each data page of a clustered index from the Sales.SalesOrderDetail table in the Adventurework2012 database. Part 2 will also dive down into the data pages of the same table/database of unique-nonclustered and nonclustered indexes. Both will try to ascertain how the SQL Server® optimizer might use them and also strive to gain some insight from a performance advantage.
This paper is not to replace or even compete with more technological index papers by Paul Randall or Kimberly Tripp (see references). Its purpose is mainly to try and understand how SQL Server implements indexes, their underlying structure, and where performance benefits might lie from a layman’s viewpoint.
The TSQL script used to evaluate the indexes and the discussion below can be copied from here; it is well-commented so that similar results can be obtained on the reader’s computer. I will note, however, that depending on SQL Server configuration and local computer memory, that specific page IDs may vary from that discussed here (however, the actual data values should remain constant).
Clustered Index
The Sales.SalesOrderDetail table in Adventureworks2012 was selected to work with. For this table, the clustered index and Primary Key are one in the same: PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID, where SalesOrderID and SalesOrderDetailID are the two columns specifying the Primary Key.
If we run the following TSQL:
SELECT *
FROM sys.sysindexes
WHERE [Name] IN ('PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID');
we get (indid is parameter indicating index id)
indid = 1 (which should always be the case for a Primary Key clustered index).
And then running
SELECT OBJECT_NAME(object_id), index_id, partition_id,allocated_page_page_id, is_iam_page,
page_type, page_type_desc, page_level, next_page_file_id, next_page_page_id,
previous_page_file_id, previous_page_page_id, is_page_compressed
FROM sys.dm_db_database_page_allocations (DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'), 1,1,'Detailed')
WHERE page_level IS NOT NULL
ORDER BY (page_level+page_type) DESC,allocated_page_page_id
where the 1 highlighted in yellow is indid (index id) and partial results are:
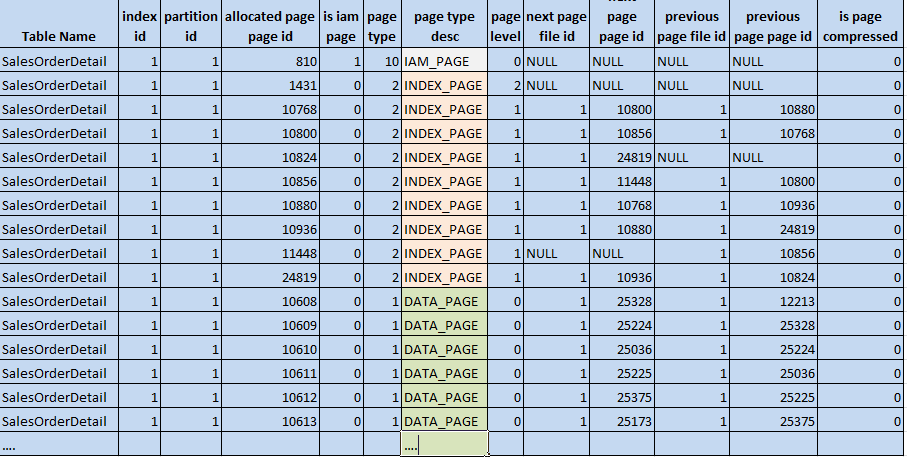
Figure 1: sys.dm_db_database_page_allocations results (© 2017 | ByrdNest Consulting)
where the first data row indicates the IAM (Index Allocation Map) page. An IAM page is used in SQL Server to track all data pages for a SQL Server index. I’m not going to discuss any more about this, except that it usually indicates the first (top) page of the B-tree. Page Level describes the level that page exists at (e.g., 0 = Leaf level or Heap level in non-b-tree, 1 = Intermediate Level of the index, >=2 Additional Intermediate level or if the highest level then the root node. In this case, the highest level is 2 and thus Page 1431 is the root node.
We can almost get the same data from
DBCC IND('AdventureWorks2012','Sales.SalesOrderDetail',1)
But the first query gives up the better data view (especially with the WHERE and ORDER BY clauses).
So now we have a starting point; let’s use the DBCC PAGE command to explore the various pages above.
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,810,3) WITH TABLERESULTS
GO
DBCC TRACEOFF(3604)
where page 810 is the IAM page. This yields a variety of information, but little about the data within the index. The TRACEON(3604) statement is to force the result set to SSMS result tab.
If we now look at the next allocated page id (1431) (root, level (2)):
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,1431,3) WITH TABLERESULTS
GO
DBCC TRACEOFF(3604)
From this we get two result sets: a header set (not of interest in this discussion) and a data set containing

Figure 2: Index Root Page (© 2017 | ByrdNest Consulting)
Where there are seven pages (ChildPageID) under the starting root node and represent the next intermediate page level. The KeyHashValue (while NULL here) is used for resource locking and a whole other discussion. The Primary Key columns (SalesOrderID & SalesOrderDetailID) are specified as boundaries for what index data lies in the next level down. The values for these columns represent the lower boundary for the PK data in the child pages. Looking at the (NULL, NULL) PK boundary data in the child page = 10824 would be for all rows having a SalesOrderID less than (and/or equal to) 50178 and a SalesOrderDetailID less than 30887. Observe that the child pages are not sequential or in order. Not sure how SQL Server assigns the pages, but it is not ascending order.
For purposes of this traversal, we will stay with index pages having a lower PK boundary of (NULL,NULL). So, going one level lower using
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,10824,3) WITH TABLERESULTS --note 2nd result set
GO
DBCC TRACEOFF(3604)
We get in the second result set (partial)

Figure 3: Index b-tree intermediate level (© 2017 | ByrdNest Consulting)
In this case, there were 252 child pages. Observe the second boundary (43668,85), which is the next boundary for when we traverse down to the leaf level in child page 10672.
Now looking at next level down (child page 10672) with
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,10672,3) WITH TABLERESULTS --
GO
DBCC TRACEOFF(3604)
We get a single result set partly shown below:

Figure 4: Leaf Level Index B-tree (partial results) (© 2017 | ByrdNest Consulting)
This is the leaf level of the clustered index and all the applicable table column data is here for that page. Note that the last value (43668,84) is just short of the next page boundary (43668,85), as noted above. For this page, there is header data then 84 rows of data stored within the data page. This row number may vary depending on variable length data types and the actual data within those columns and fill factor.
So, what did we learn?
- The width of the Primary Key will determine how many intermediate levels there will be to get to the leaf levels. This goes along with the industry standard of minimizing the width of the Primary Key.
- DBCC Page gives the capability to directly inspect the data within a SQL Server page and how they interlink.
Read Part 2
References (in no particular order or preference):
http://blog.matticus.net/2013/04/undocumented-sql-fun-with-dbcc-page.html
https://www.sqlskills.com/blogs/paul/category/indexes-from-every-angle/
[…] Part 1 […]