(Note: Thanks to my friend and colleague Russel McDonald, who contributed ideas to this post.)
Fragmentation is an element that has been critical to SQL Server performance for many years. In this post, I will explain fragmentation, what can be done about it, analyze the impacts of fragmentation and corrective actions on HDDs (hard disk drives) and SSDs (solid state disks).
Fragmentation is a condition of not having contiguous data. When your data is fragmented, scanning it requires more small random I/O operations than large sequential I/O operations and thus it will take longer to read. The sizes of I/O operations SQL Server typically uses when servicing T-SQL “SELECT” type commands are are 8k, 64k and multiples of 64k up to 512k. SQL Server prefers larger sequential I/Os when it has the luxury of leveraging them. Large scans can benefit from this, particularly on HDD (hard disk drive) storage where the physical rotation of the disk is a significant overhead. On SSD (solid state storage) it is less of an issue however having fewer actual I/Os is advantageous for an SSD thus when the pages are contiguous and SQL Server can leverage larger reads, it benefits from having fewer I/Os.
There are three types of fragmentation to consider.
- Logical fragmentation, when the pages are out of logical sequence.
-
Extent fragmentation, when the extents are not contiguous and SQL Server is unable to leverage read ahead, for example, reads up to 512k.*
- External fragmentation, where everything is in logical order according to SQL Server, but where the data physically resides on the disk is not contiguous.
*An Extent is eight (8) contiguous 8k pages.
We don’t usually concern ourselves with external fragmentation and I will not discuss it in this post but I did want to mention it as sometimes it is worth looking at. If you conclude that you have external fragmentation, you either need a third-party tool, like Diskeeper, that can resolve it with the database online or you have to create a new, freshly formatted volume and forklift the files into place one by one, which is an offline operation. External fragmentation is a significant concern for HDD storage because of the additional revolutions the disk must do to get to the data it needs. While it’s less of a concern for SSD storage because of the lack of rotational latency I suppose it could pose a problem so long as it caused multiple smaller reads as opposed to fewer larger reads. This would be a question for a Windows Server guru.
When data is contiguous, SQL Server can read the same amount of data in fewer, but larger I/O operations, which is usually faster. Because of this, SQL Server DBAs frequently perform one of three operations to address fragmentation.
- Reorg—A reorg will swap pages of a table in small transactions until all pages are in logical order. The result will not yield physically contiguous pages, only logically ordered pages. This operation leaves the underlying table/index available for update but will take longer than a reindex if the index has a lot of logical fragmentation i.e. the pages are out of order. One of the most important benefits of this operation is that its atomic transactions are small so you can stop the operation without rolling back much work. Thus you can get as much done as you have time, stop then resume later. Sometimes this is the best answer for an incredibly large index that cannot be rebuilt within a maintenance window.
- Offline Rebuild—This operation locks the underlying table/index leaving it unavailable for updates until the operation completes. As opposed to the reorg mentioned above, it does seek to make the pages physically contiguous and this is all or nothing. If you cancel it, everything rolls back.
- Online Rebuild–This operation locks the underlying table/index significantly less, leaving it available for updates during most of the operation. As opposed to the reorg mentioned above, it does seek to make the pages physically contiguous and this is all or nothing. If you cancel it, everything rolls back.
Sometimes it’s hard to visualize where your data really is on disk, how it is grows and moves during various operations. There are a few tools I will use to help you see what is going on. First and foremost is a tool called ProcMon, which you can use to observe the reads and writes SQL Server is performing as you operate upon the data. Another is the command, DBCC SHOWCONTIG, which gives you information about fragmentation. Finally, I will use the undocumented command DBCC IND which I came to know about thanks to Paul Randal. Using DBCC IND you can determine which pages of your data files your tables are comprised of.
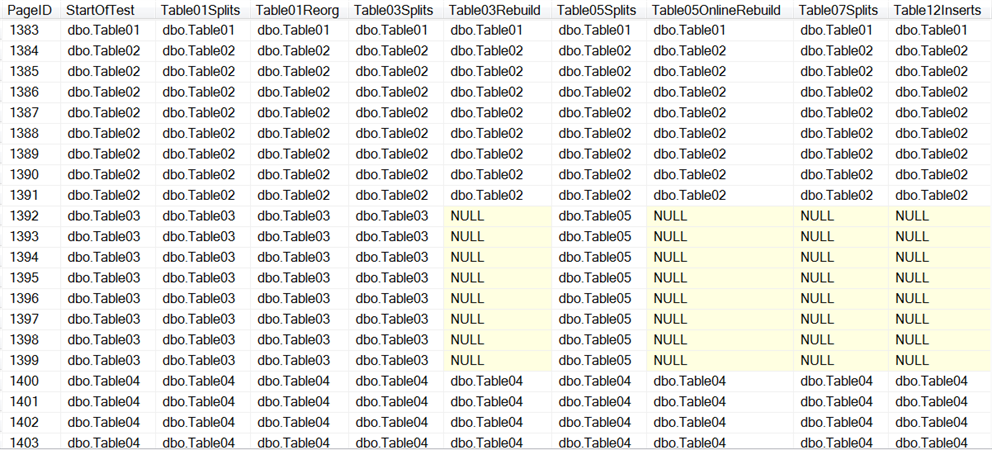
I’ll start by explaining the setup for this test. The first thing I did was create 10 tables. I populated each table with identical data and caused the extents of the table, to be striped such that on disk there was 8 pages of Table01, 8 pages of Table02, 8 pages of Table03 and so on through Table10. Then created and populated Table11 with the same data giving it contiguous extents in the data file. The following colorful bar is an attempt to help you visualize how the first 10 tables had their extents striped while Table 11 was fully contiguous. This is not illustrated to scale.
![]()
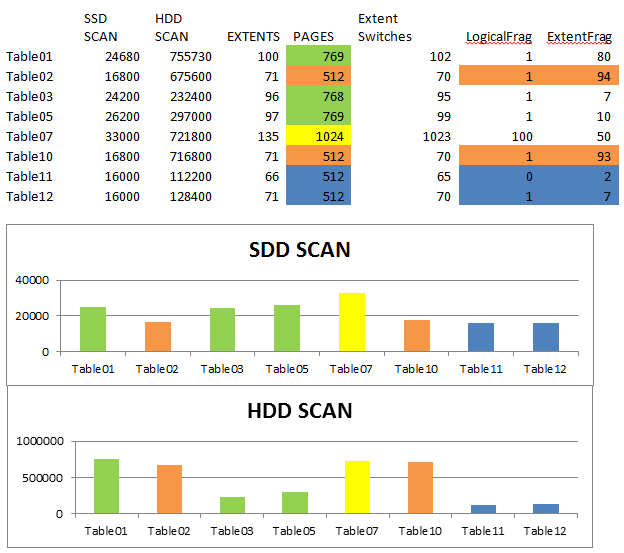
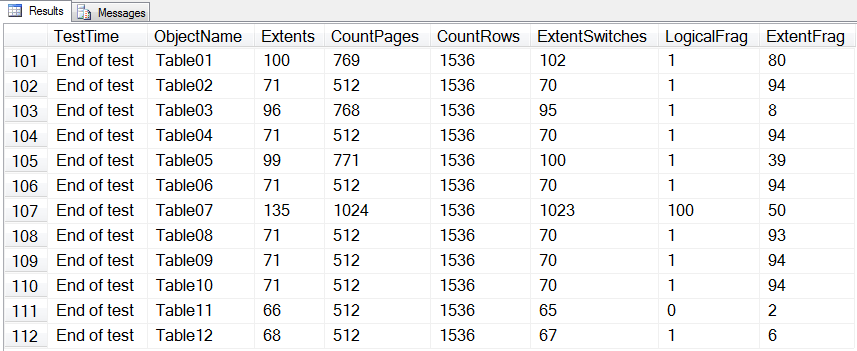
At this point, every table had 1536 rows, 512 pages and very low logical fragmentation. Tables 1-10 have 71 extents and very high extent fragmentation. Note: I am not referring to external fragmentation; I am saying that the extents, are fragmented. In fact, the extents for tables 1-10 are fully fragmented. There is not one that is adjacent. The pages however, are not fully fragmented as each extent contains 8 contiguous pages. Table 11 has 66 extents and low extent fragmentation.
After that was all set up, began causing page splits and testing one of each corrective actions. To cause the page splits I updated a row on each page to be larger so that it would no longer fit on the page on which it was created. Since the tables were designed so that each page contained 3 rows, expanding one row per page doubles the number of pages.
Here is the order of my operations in written English.
- Caused page splits in table 1 sending the page count from 512 to 1024.
- Performed a reorg on table 1 reducing the page count to 769.
- Caused page splits in table 3 sending the page count from 512 to 1024.
- Performed a rebuild on table 3 reducing the page count to 769.
- Caused page splits in table 5 sending the page count from 512 to 1024.
- Performed an online rebuild on table 5 reducing the page count to 772.
- Caused page splits in table 7 sending the page count from 512 to 1024.
- Built a 12th table with the same data in 512 pages in fully contiguous extents.
Before and after each step, I called a stored procedure I made that called DBCC IND and DBCC SHOWCONTIG for each table thus recording the contents of each page as well as the fragmentation statistics in between every step. I repeated this test on a hard disk drive and an SSD.
- 7200k RPM HDD connected to my computer via USB 2.0 as G
- SSD connected to my computer via e-SATA II as E
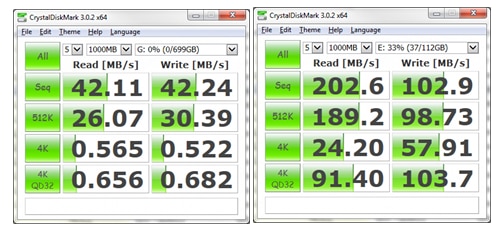
Following is a summary of the results. You can see in the results that fragmentation has less performance penalty on SSD than it does on traditional HDDs. Notice that tables 2 and 10, which are each in the condition that they were initially created, without having any rows expanded, have high extent fragmentation and low logical fragmentation. Table 7, which has more data, high logical and extent fragmentation, should perform worst in both cases and it does. Table 3 was fragmented then fixed up with an offline rebuild. It should perform the best between 1, 3 and 5. And it does, though the difference is substantially greater for the HDD than the SSD. With the SSD, there is little difference between the reorg on Table 1, offline rebuild on Table 3 and online rebuild on Table 5. This is due to the differences in their physical operations. SSDs do not have moving parts like HDDs; they do not suffer from rotational latency. They are inherently better at random access.
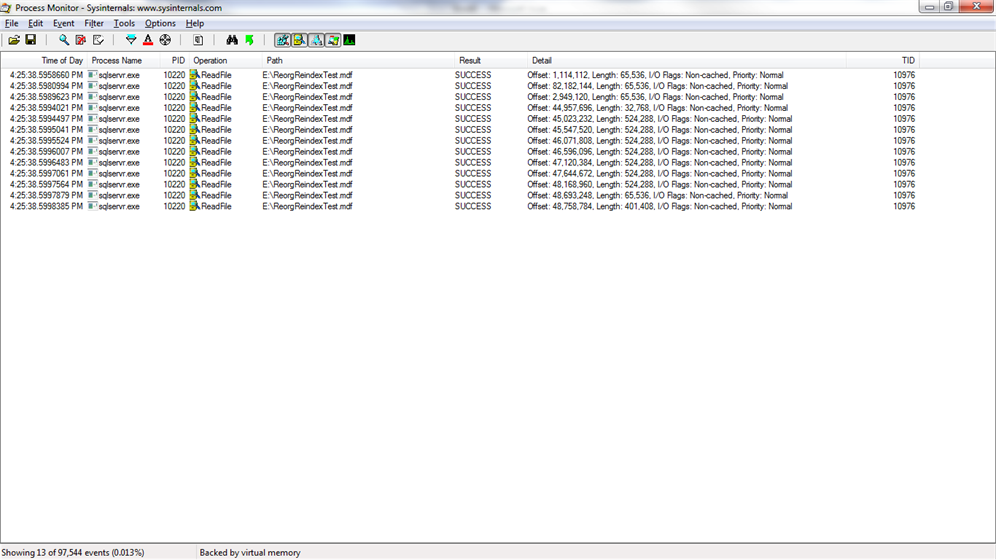
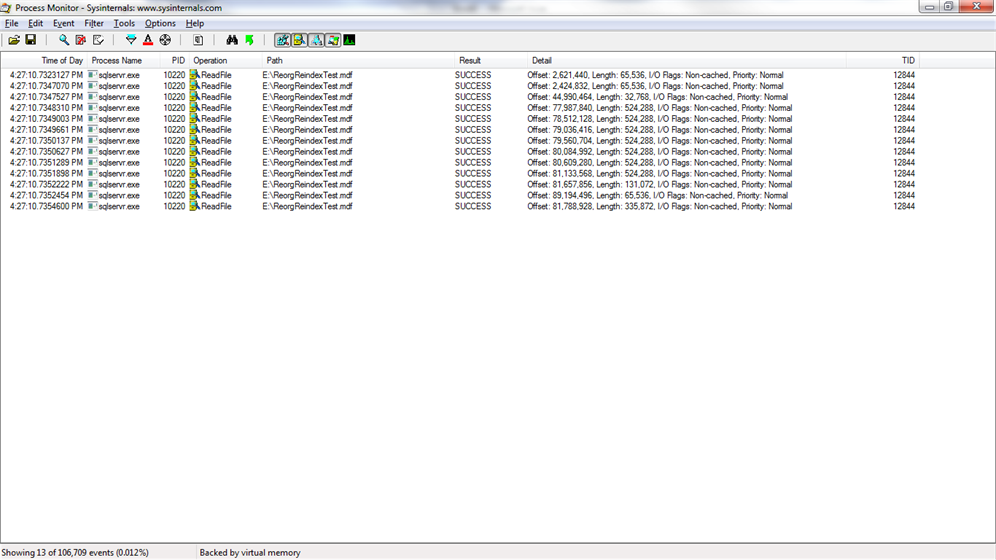
Perhaps the most interesting observation is between tables 2 and 7. Notice the differences between SSD and HDD with tables 2 and 7. Table 7 has twice the number of pages as table 2 thus SQL Server has to read twice the number of pages even though they have the same number of rows and the actual data in table 7 is not twice as much as in table 2. On the SSD, table 7 took almost twice as long to scan as table 2 on the SSD. On the HDD, there was a much less difference in scan time between tables 2 and 7. The reason is clear when you see the ProcMon results further down. The additional 512 pages of table 7, created when the page splits occurred, were written in contiguous extents at the end of the file. Table 2 had 67 I/Os while table 7 had 85 I/Os. That’s twice the data in only 27% more I/Os. So all of table 2 was 64k reads for 512 pages while for table 7, almost half of the 1024 pages read were sequentially scanned which is a big benefit for an HDD but doesn’t matter much for an SSD. For an SSD, having more pages to read is a greater penalty while for an HDD, having more I/Os is a greater penalty.
It helps to see what SQL Server is asking of the disk storage subsystem. To do this, we use Procmon. I’ve set up my procmon to monitor SQL Server reads and writes in the specific database file upon which I am operating.
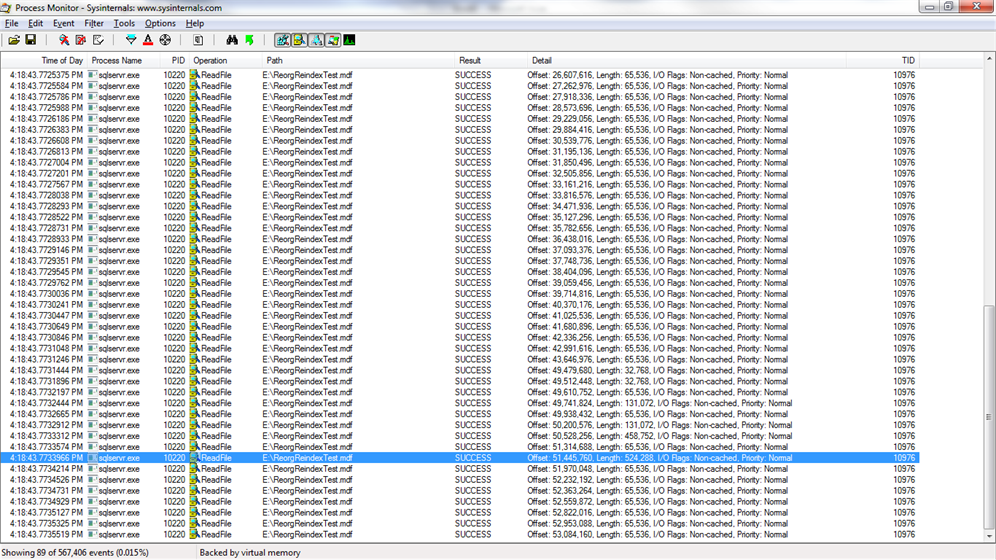
When I execute a scan against Table01 I see lots of 64k extent reads and a very small number of read aheads up to 512k because the reorg operation didn’t strive to achieve many contiguous extents.
When I execute a scan against Table02, I don’t see any reads larger than 64k because the largest contiguous unit in this table is an extent. This is just as I expected because I caused the data to stripe extents when I wrote it and I did nothing to fix it up.
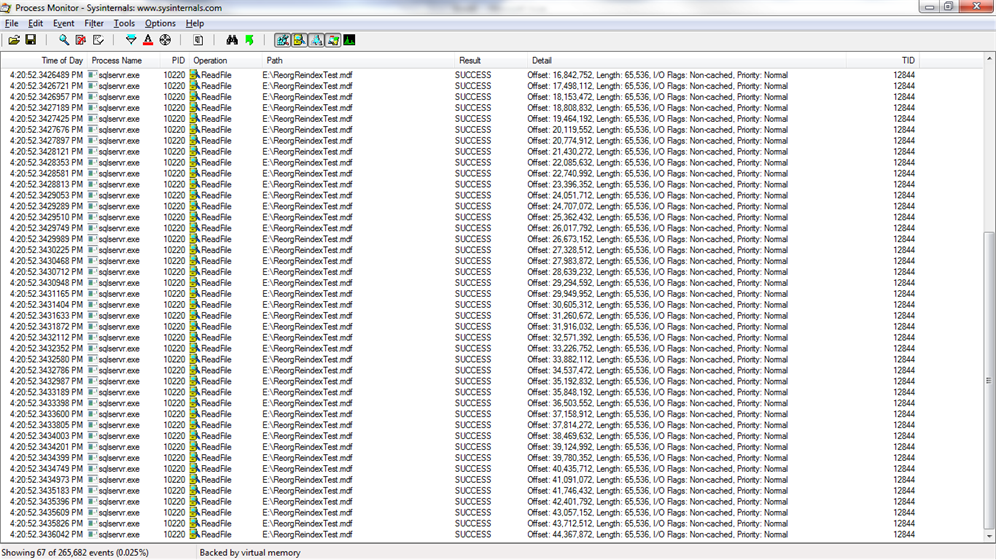
When I execute a scan against Table03 and Table 05, I see a lot of read aheads up to 512k because there are several contiguous extents as a result of the rebuild operations.
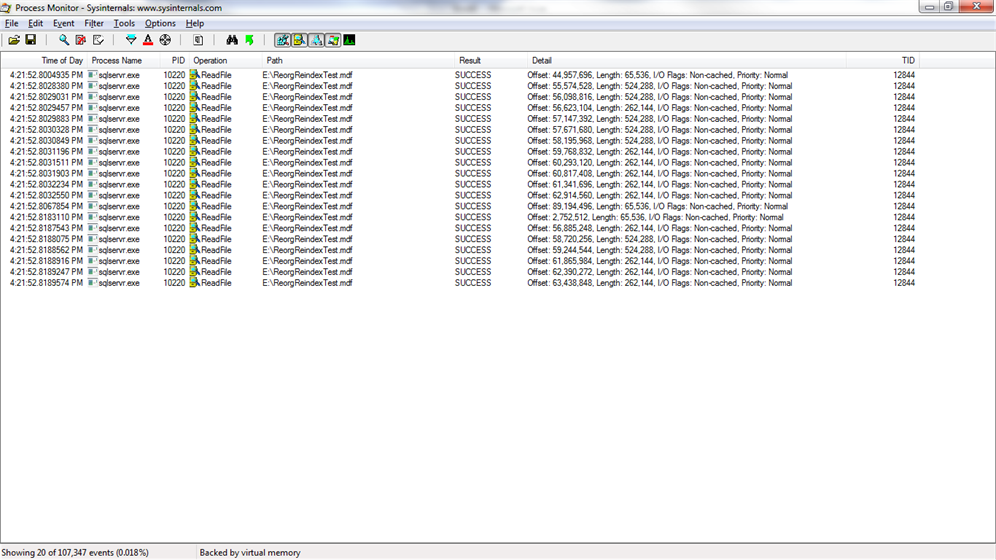
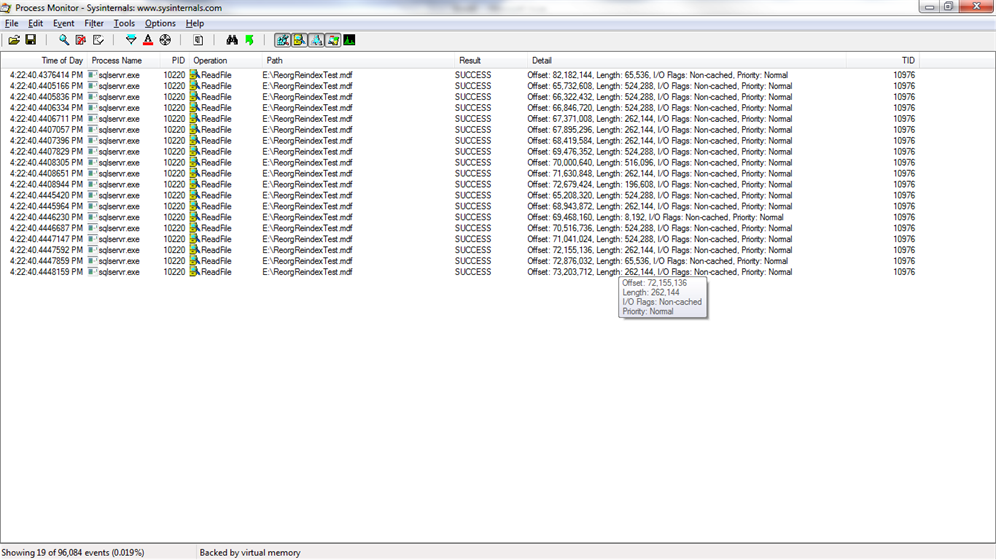
When I execute a scan against Table07, I see mostly 64k reads but there are some 512k read aheads toward the end of the file, past file offsets of 73 million. Those pages were written after the page split.
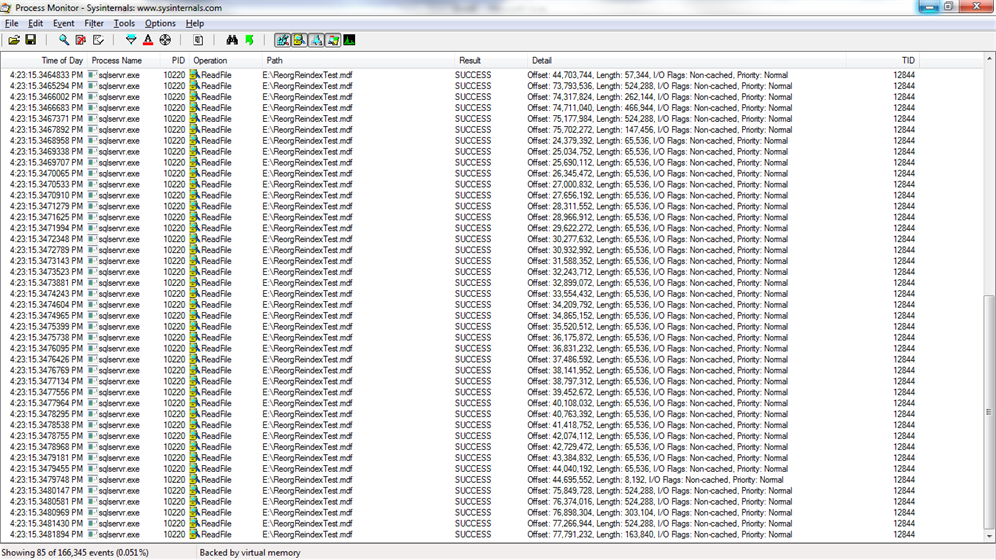
When I execute a scan against Table11 and Table12, I see a lot of contiguous 512k read aheads because they were written to disk sequentially and never fragmented.
The script below includes my work and some result sets you can explore, including one that will show you what table occupies each page in the database.
set nocount on
CREATE DATABASE [ReorgReindexTest] ON PRIMARY
( NAME = N'ReorgReindexTest', FILENAME = N'e:ReorgReindexTest.mdf' , SIZE = 4096KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'ReorgReindexTest_log', FILENAME = N'e:ReorgReindexTest_log.ldf' , SIZE = 4096KB , FILEGROWTH = 1024KB )
GO
ALTER DATABASE [ReorgReindexTest] SET COMPATIBILITY_LEVEL = 100
ALTER DATABASE [ReorgReindexTest] SET ANSI_NULL_DEFAULT OFF
ALTER DATABASE [ReorgReindexTest] SET ANSI_NULLS OFF
ALTER DATABASE [ReorgReindexTest] SET ANSI_PADDING OFF
ALTER DATABASE [ReorgReindexTest] SET ANSI_WARNINGS OFF
ALTER DATABASE [ReorgReindexTest] SET ARITHABORT OFF
ALTER DATABASE [ReorgReindexTest] SET AUTO_CLOSE OFF
ALTER DATABASE [ReorgReindexTest] SET AUTO_CREATE_STATISTICS ON
ALTER DATABASE [ReorgReindexTest] SET AUTO_SHRINK OFF
ALTER DATABASE [ReorgReindexTest] SET AUTO_UPDATE_STATISTICS ON
ALTER DATABASE [ReorgReindexTest] SET CURSOR_CLOSE_ON_COMMIT OFF
ALTER DATABASE [ReorgReindexTest] SET CURSOR_DEFAULT GLOBAL
ALTER DATABASE [ReorgReindexTest] SET CONCAT_NULL_YIELDS_NULL OFF
ALTER DATABASE [ReorgReindexTest] SET NUMERIC_ROUNDABORT OFF
ALTER DATABASE [ReorgReindexTest] SET QUOTED_IDENTIFIER OFF
ALTER DATABASE [ReorgReindexTest] SET RECURSIVE_TRIGGERS OFF
ALTER DATABASE [ReorgReindexTest] SET DISABLE_BROKER
ALTER DATABASE [ReorgReindexTest] SET AUTO_UPDATE_STATISTICS_ASYNC OFF
ALTER DATABASE [ReorgReindexTest] SET DATE_CORRELATION_OPTIMIZATION OFF
ALTER DATABASE [ReorgReindexTest] SET PARAMETERIZATION SIMPLE
ALTER DATABASE [ReorgReindexTest] SET READ_WRITE
ALTER DATABASE [ReorgReindexTest] SET RECOVERY FULL
ALTER DATABASE [ReorgReindexTest] SET MULTI_USER
ALTER DATABASE [ReorgReindexTest] SET PAGE_VERIFY CHECKSUM
GO
USE [ReorgReindexTest]
GO
IF NOT EXISTS (SELECT name FROM sys.filegroups WHERE is_default=1 AND name = N'PRIMARY') ALTER DATABASE [ReorgReindexTest] MODIFY FILEGROUP [PRIMARY] DEFAULT
GO
--------------------------------------------------------------------------
-- Create global temp tables and proc that logs page locations for all tables
--------------------------------------------------------------------------
IF OBJECT_ID('tempdb..##DbccIndResults') IS NOT NULL
drop table ##DbccIndResults
go
IF OBJECT_ID('tempdb..##fraglist') IS NOT NULL
drop table ##fraglist
go
if exists( select * from sysobjects where name = 'LogPagesInTables_sp' )
drop proc LogPagesInTables_sp
go
create proc LogPagesInTables_sp
@Label varchar(100)= 'Test Label'
as
IF OBJECT_ID('tempdb..##DbccIndResults') IS NULL
create table ##DbccIndResults (
CallName varchar(100) ,
PageFID int , PagePID bigint , IAMFID int , IAMPID int , ObjectID bigint , IndexID int ,
PartitionNumber int , PartitionID bigint , iam_chain_type varchar(50) , PageType int ,
IndexLevel int , NextPageFID bigint , NextPagePID bigint , PrevPageFID bigint , PrevPagePID bigint
)
IF OBJECT_ID('tempdb..##fraglist') IS NULL
CREATE TABLE ##fraglist(id int identity(1,1),TestTime varchar(255),ObjectName CHAR (255),ObjectId INT,IndexName CHAR (255),IndexId INT,Lvl INT,CountPages INT,CountRows INT,MinRecSize INT,MaxRecSize INT,AvgRecSize INT,ForRecCount INT,Extents INT,ExtentSwitches INT,AvgFreeBytes INT,AvgPageDensity INT,ScanDensity DECIMAL,BestCount INT,ActualCount INT,LogicalFrag DECIMAL,ExtentFrag DECIMAL)
declare @sc as sysname , @ob as sysname , @sql as varchar(8000)
declare objcsr cursor for select distinct s.name , o.name
from sys.objects o
inner join sys.schemas s on s.schema_id = o.schema_id
where o.type in ( 'U' , 'IT' )
open objcsr
while 1=1 begin
fetch next from objcsr into @sc , @ob
set @sql = 'insert ##DbccIndResults ( PageFID , PagePID , IAMFID , IAMPID , ObjectID , IndexID , PartitionNumber , PartitionID , iam_chain_type , PageType , IndexLevel , NextPageFID , NextPagePID , PrevPageFID , PrevPagePID )'+
'exec(''DBCC IND ('''''+DB_NAME()+''''', '''''+@sc + '.' + @ob+''''', 1) with no_infomsgs;'' )'+
'update ##DbccIndResults set CallName = '''+@sc + '.' + @ob+': '+@Label +'.'' where CallName is null'
--print @sql
exec(@sql)
set @sql = 'INSERT INTO ##fraglist(ObjectName,ObjectId,IndexName,IndexId,Lvl,CountPages,CountRows,MinRecSize,MaxRecSize,AvgRecSize,ForRecCount,Extents,ExtentSwitches,AvgFreeBytes,AvgPageDensity,ScanDensity,BestCount,ActualCount,LogicalFrag,ExtentFrag)'+
'EXEC (''DBCC SHOWCONTIG ('''''+DB_NAME()+'.'+@sc + '.' + @ob+''''') WITH TABLERESULTS, NO_INFOMSGS'')'+
'UPDATE ##fraglist set TestTime = '''+@Label +''' where TestTime is null'
--print @sql
exec(@sql)
if @@FETCH_STATUS <> 0 break
end -- while 1=1
close objcsr
deallocate objcsr
go
--------------------------------------------------------------------------
-- Create 10 tables
--------------------------------------------------------------------------
create table Table01 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t01pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table02 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t02pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table03 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t03pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table04 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t04pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table05 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t05pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table06 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t06pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table07 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t07pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table08 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t08pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table09 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t09pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
create table Table10 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t10pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
--------------------------------------------------------------------------
-- Interweave full extent after full extent into 10 tables
--------------------------------------------------------------------------
declare @RowLimit bigint
, @LoopNum bigint
, @sql varchar(8000)
select @RowLimit = 10*64*8*3 -- 10 tables * 64 extents * 8 pages * 3 rows
, @LoopNum = 0
BEGIN TRANSACTION
while @LoopNum < @RowLimit begin
-- Table = (@LoopNum/3%10)+1
-- DataSet = (@LoopNum%3)+1
if (@LoopNum%3)+1 in ( 1 , 3 )
set @sql = 'insert Table'+right('0'+CONVERT(varchar(2),(@LoopNum/3%10)+1),2)+' ( id , DataSetNum , data ) values ( '+CONVERT(varchar(100),@LoopNum)+' , 1 , REPLICATE(''A'', 3000) )'
if (@LoopNum%3)+1 = 2
set @sql = 'insert Table'+right('0'+CONVERT(varchar(2),(@LoopNum/3%10)+1),2)+' ( id , DataSetNum , data ) values ( '+CONVERT(varchar(100),@LoopNum)+' , 2 , REPLICATE(''A'', 1000) )'
--print @sql
exec(@sql)
set @LoopNum = @LoopNum + 1
end -- while @LoopNum < @RowLimit
COMMIT TRANSACTION
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
--------------------------------------------------------------------------
-- Create & insert the 11th table fully contiguous
--------------------------------------------------------------------------
create table Table11 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t11pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
go
declare @RowLimit bigint
, @LoopNum bigint
, @sql varchar(8000)
select @RowLimit = 1*64*8*3 -- 1 table * 64 extents * 8 pages * 3 rows
, @LoopNum = 0
BEGIN TRANSACTION
while @LoopNum < @RowLimit begin
-- insert Table11 ( id , DataSetNum , data ) values ( @LoopNum , 100*RAND() , @data )
if (@LoopNum%3)+1 in ( 1 , 3 )
set @sql = 'insert Table11 ( id , DataSetNum , data ) values ( '+CONVERT(varchar(100),@LoopNum)+' , 1 , REPLICATE(''A'', 3000) )'
if (@LoopNum%3)+1 = 2
set @sql = 'insert Table11 ( id , DataSetNum , data ) values ( '+CONVERT(varchar(100),@LoopNum)+' , 2 , REPLICATE(''A'', 1000) )'
--print @sql
exec(@sql)
set @LoopNum = @LoopNum + 1
end -- while @LoopNum < @RowLimit
COMMIT TRANSACTION
--------------------------------------------------------------------------
-- Log the initial pages consumed by the 11 tables created
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'Start of test'
--------------------------------------------------------------------------
-- Cause Page Split in Table01
--------------------------------------------------------------------------
update Table01
set data = REPLICATE('B', 3000)
where DataSetNum = 2
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table01 page splits'
--------------------------------------------------------------------------
-- ReOrg Table01
--------------------------------------------------------------------------
ALTER INDEX ALL ON Table01 REORGANIZE ;
go
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table01 reorg'
--------------------------------------------------------------------------
-- Cause Page Split in Table03
--------------------------------------------------------------------------
update Table03
set data = REPLICATE('B', 3000)
where DataSetNum = 2
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table03 page splits'
--------------------------------------------------------------------------
-- Rebuild Table03
--------------------------------------------------------------------------
ALTER INDEX ALL ON Table03 REBUILD ;
go
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table03 rebuild'
--------------------------------------------------------------------------
-- Cause Page Split in Table05
--------------------------------------------------------------------------
update Table05
set data = REPLICATE('B', 3000)
where DataSetNum = 2
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table05 page splits'
--------------------------------------------------------------------------
-- Rebuild Table05
--------------------------------------------------------------------------
ALTER INDEX ALL ON Table05 REBUILD WITH ( ONLINE = ON );
go
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table05 online rebuild'
--------------------------------------------------------------------------
-- Cause Page Split in Table07
--------------------------------------------------------------------------
update Table07
set data = REPLICATE('B', 3000)
where DataSetNum = 2
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table07 page splits'
--------------------------------------------------------------------------
-- Insert the 12th table fully contiguous
--------------------------------------------------------------------------
create table Table12 (
id int not null ,
DataSetNum smallint ,
data varchar(8000) ,
constraint t12pk primary key clustered (id) with ( FILLFACTOR = 100, PAD_INDEX = OFF )
)
declare @RowLimit bigint
, @LoopNum bigint
, @sql varchar(8000)
select @RowLimit = 1*64*8*3 -- 1 table * 64 extents * 8 pages * 3 rows
, @LoopNum = 0
BEGIN TRANSACTION
while @LoopNum < @RowLimit begin
-- insert Table11 ( id , DataSetNum , data ) values ( @LoopNum , 100*RAND() , @data )
if (@LoopNum%3)+1 in ( 1 , 3 )
set @sql = 'insert Table12 ( id , DataSetNum , data ) values ( '+CONVERT(varchar(100),@LoopNum)+' , 1 , REPLICATE(''A'', 3000) )'
if (@LoopNum%3)+1 = 2
set @sql = 'insert Table12 ( id , DataSetNum , data ) values ( '+CONVERT(varchar(100),@LoopNum)+' , 2 , REPLICATE(''A'', 1000) )'
--print @sql
exec(@sql)
set @LoopNum = @LoopNum + 1
end -- while @LoopNum < @RowLimit
COMMIT TRANSACTION
--------------------------------------------------------------------------
-- Record all page locations
--------------------------------------------------------------------------
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
go
exec LogPagesInTables_sp 'After Table12 inserts'
exec LogPagesInTables_sp 'End of test'
--------------------------------------------------------------------------
--------------------------------------------------------------------------
--------------------------------------------------------------------------
-- Analyze Data Change Over Time
--------------------------------------------------------------------------
--------------------------------------------------------------------------
--------------------------------------------------------------------------
---------------------------------------------
-- See how fragmentation changed
---------------------------------------------
select TestTime , ObjectName , Extents , CountPages , CountRows , ExtentSwitches , LogicalFrag, ExtentFrag
from ##fraglist
order by id
---------------------------------------------
-- See how pages moved
---------------------------------------------
IF OBJECT_ID('dbo.PageNumbers') IS NULL begin
create table PageNumbers ( PageID int , constraint pnpk primary key clustered (pageid))
declare @curpageid int
set @curpageid = 0
while @curpageid < 65536 begin
set @curpageid = @curpageid + 1
insert PageNumbers ( PageID ) values ( @curpageid )
end -- while
end
select pn.PageID
, left(sot.CallName,11) as StartOfTest
, left(t1s.CallName,11) as Table01Splits
, left(t1r.CallName,11) as Table01Reorg
, left(t3s.CallName,11) as Table03Splits
, left(t3r.CallName,11) as Table03Rebuild
, left(t5s.CallName,11) as Table05Splits
, left(t5r.CallName,11) as Table05OnlineRebuild
, left(t7s.CallName,11) as Table07Splits
, left(eot.CallName,11) as Table12Inserts
from PageNumbers pn
left join ##DbccIndResults sot on sot.pagepid = pn.PageID
and sot.CallName like '%Start of test.'
left join ##DbccIndResults t1s on t1s.pagepid = pn.PageID
and t1s.CallName like '%After Table01 page splits.'
left join ##DbccIndResults t1r on t1r.pagepid = pn.PageID
and t1r.CallName like '%After Table01 reorg.'
left join ##DbccIndResults t3s on t3s.pagepid = pn.PageID
and t3s.CallName like '%After Table03 page splits.'
left join ##DbccIndResults t3r on t3r.pagepid = pn.PageID
and t3r.CallName like '%After Table03 rebuild.'
left join ##DbccIndResults t5s on t5s.pagepid = pn.PageID
and t5s.CallName like '%After Table05 page splits.'
left join ##DbccIndResults t5r on t5r.pagepid = pn.PageID
and t5r.CallName like '%After Table05 online rebuild.'
left join ##DbccIndResults t7s on t7s.pagepid = pn.PageID
and t7s.CallName like '%After Table07 page splits.'
left join ##DbccIndResults eot on eot.pagepid = pn.PageID
and eot.CallName like '%After Table12 inserts.'
where pn.PageID <= ( select MAX(pagepid) from ##DbccIndResults )
order by pn.pageid --PagePID
---------------------------------------------
-- Test Scan Times (output to messages pane)
---------------------------------------------
declare @starttime datetime , @sumtime int, @loopnum int , @ct int , @passes int
select @loopnum = 0
, @sumtime = 0
, @passes = 100
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table01 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table01: striped extents, fragmented then reorganized'
waitfor delay '00:00:10'
select @loopnum = 0
, @sumtime = 0
, @passes = 5
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table02 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table02: striped extents, never fragmented'
waitfor delay '00:00:10'
select @loopnum = 0
, @sumtime = 0
, @passes = 5
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table03 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table03: striped extents, fragmented then rebuilt'
waitfor delay '00:00:10'
select @loopnum = 0
, @sumtime = 0
, @passes = 5
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table05 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table05: striped extents, fragmented then rebuilt with online=true'
waitfor delay '00:00:10'
select @loopnum = 0
, @sumtime = 0
, @passes = 5
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table07 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table07: striped extents then fragmented'
waitfor delay '00:00:10'
select @loopnum = 0
, @sumtime = 0
, @passes = 5
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table10 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table10: striped extents, never fragmented'
waitfor delay '00:00:10'
select @loopnum = 0
, @sumtime = 0
, @passes = 5
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table11 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table11: fully contiguous'
waitfor delay '00:00:10'
select @loopnum = 0
, @sumtime = 0
, @passes = 5
while @loopnum < @passes begin
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
set @starttime = GETDATE()
select @ct= count(*) from ReorgReindexTest.dbo.table12 where data like 'abc'
set @sumtime = @sumtime + DATEDIFF(mcs,@starttime,getdate())
set @loopnum = @loopnum + 1
end -- while
print convert( varchar(10), @sumtime/@passes ) + ' - Table12: fully contiguous'
/*
-- Using this section one at a time while monitoring with procmon, we can see the difference
-- in the individual I/Os SQL Serer issues to the disk.
-- run these 2 commands to ensure SQL Serer is not holding pages in cache.
checkpoint 1
dbcc dropcleanbuffers with no_infomsgs
-- start procmon
select count(*) from ReorgReindexTest.dbo.table01 where data like 'abc'
select count(*) from ReorgReindexTest.dbo.table02 where data like 'abc'
select count(*) from ReorgReindexTest.dbo.table03 where data like 'abc'
select count(*) from ReorgReindexTest.dbo.table05 where data like 'abc'
select count(*) from ReorgReindexTest.dbo.table07 where data like 'abc'
select count(*) from ReorgReindexTest.dbo.table11 where data like 'abc'
select count(*) from ReorgReindexTest.dbo.table12 where data like 'abc'
*/
Leave a Reply