SQL Server allows the creation of multiple non-clustered indexes, with a maximum of 999 in the SQL 2008 release (compared to 249 in 2005 release); the only limitation is that the “Index Name” must be unique for the schema. This could mean that some indexes might actually be duplicates of each other in all but their name, also known as exact duplicate indexes. If this happens, it can waste precious SQL Server resources and generate unnecessary overhead, causing poor database performance.
What do duplicate indexes look like?
For a quick example, I’ll use a copy of the community sample database “AdventureWorks2008” or “AdventureWork2012” to review the index definitions for this database, as shown in Figure 1 below:
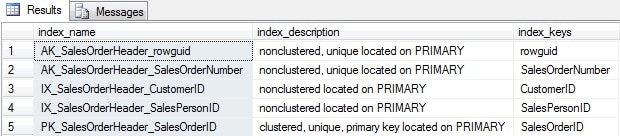
Figure 1: sp_helpindex ‘Sales.SalesOrderHeader’
In this example, [index_name] all have different values, and each of the four non-clustered indexes also has a different [index_keys] value, so there are no duplicates for this table.
If I scripted out the [AK_SalesOrderHeader_SalesOrderNumber] index and tried to create it again on the Sales.SalesOrderHeader table, I wouldn’t succeed and would instead have the following error:
Msg 1913, Level 16, State 1, Line 2 The operation failed because an index or statistics with name 'AK_SalesOrderHeader_SalesOrderNumber' already exists on table 'Sales.SalesOrderHeader'.
However, if I simply change the index name, say to [AK_SalesOrderHeader_SalesOrderNum], and then run the code to create the index, I would succeed. The table now has two indexes which are exact duplicate indexes. (Note that there are other types of duplicate indexes, but in this article, I am only looking at the exact duplicate indexes, that is indexes that have the same definition but a different name; in this example, we have[AK_SalesOrderHeader_SalesOrderNumber] and the newly created [AK_SalesOrderHeader_SalesOrderNum] as seen in Figure 2 below).
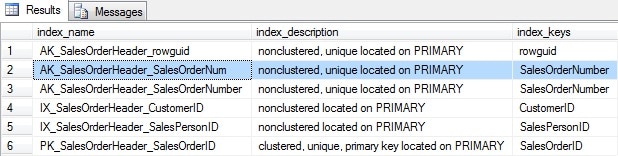
Figure 2: sp_helpindex ‘Sales.SalesOrderHeader’
How do duplicate indexes affect SQL Server?
To understand how this affects SQL Server, I can look at one of the Index Dynamic Management Views (DMV’s) to review index usage; I am especially interested in the metric ‘Total Reads.’
sp_helpindex 'Sales.SalesOrderHeader';
SELECT
sch.name + '.' + tbl.name AS [Table Name],
ind.name AS [Index Name],
ind.index_id AS [Index_id],
ind.type_desc,
ISNULL(user_seeks + user_scans
+ user_lookups,0) AS [Total Reads
ISNULL(user_updates,0) AS [Total Writes],
ius.last_user_seek,
ius.last_user_scan ,
ius.last_user_lookup,
(ps.reserved_page_count*8.0)/1024 AS [SpaceUsed_MB]
FROM sys.indexes AS ind
FULL OUTER JOIN sys.dm_db_index_usage_stats AS ius
ON ius.object_id = ind.object_id
AND ius.index_id = ind.index_id
AND ius.database_id = db_id()
AND objectproperty(ius.object_id,'IsUserTable') = 1
INNER JOIN sys.tables AS tbl
ON ind.object_id = tbl.object_id
INNER JOIN sys.schemas AS sch
ON tbl.schema_id = sch.schema_id
LEFT OUTER JOIN sys.dm_db_partition_stats AS ps
ON ind.index_id = ps.index_id
AND ind.object_id = ps.object_id
WHERE ius.object_id = object_id('sales.SalesOrderHeader')
ORDER BY [Table Name], [index name]

Figure 4:
Interesting! I now have six indexes (one clustered and five non-clustered, one of which is the new ‘exact duplicate’ index).
Which of the duplicate indexes will SQL Engine use?
Now I want to issue a query that uses the [index_keys] column for “SalesorderNumber.” Of course, I have two indexes that could be used to help return the result doing an index seek, but for now, I’m interested in just one row.
So which of the two indexes will SQL Engine decide to use: the original index or the recently added ‘duplicate’ index? What reason will that decision be based on?
Here is the same query:
SELECT * from sales.SalesOrderHeader where SalesOrderNumber = 'SO44000'
If I immediately re-run the query to return the index usage data, I see that the newly added index and it shows that it now has one READ on it, but still zero reads for the original index, as seen in Figure 5 below.
Figure 5:
Maybe this is because the new index has more recent statistics? Let’s see if that is true:
DBCC SHOW_STATISTICS ('AdventureWorks2012.Sales.SalesOrderHeader',
'AK_SalesOrderHeader_SalesOrderNumber') WITH STAT_HEADER JOIN DENSITY_VECTOR
DBCC SHOW_STATISTICS ('AdventureWorks2012.Sales.SalesOrderHeader',
'AK_SalesOrderHeader_SalesOrderNum') WITH STAT_HEADER JOIN DENSITY_VECTOR
Examining these results, I can see that the newly created index has the most recent statistics for that table | Column ‘SalesOrderNumber’ so is the reason for choosing that index over the existing one.
If I reissue the query, say four more times, and find the total number of reads is (as expected) now five, I could manually perform an update to the statistics of the original index using the following syntax:
UPDATE STATISTICS Sales.SalesOrderHeader AK_SalesOrderHeader_SalesOrderNumber;
Would it still continue to use the newly created index? In this case, yes. As the query plan is now cached for the new index that was added, I would also need to make this query plan invalidate in some way or even remove it from the plan cache. So does this work?
For this example, I’ll clear the proc-cache for this query, and I could also clear all plans from the cache:
/* dbcc freeproccache {plan_handle} Clears all plans if not also supplied with a plan_handle */
select decp.usecounts, decp.size_in_bytes, dest.text, decp.plan_handle, deqp.query_plan
from sys.dm_exec_cached_plans decp
cross apply sys.dm_exec_sql_text(decp.plan_handle) dest
cross apply sys.dm_exec_query_plan(decp.plan_handle) deqp
where dest.text like 'Select * from sales.SalesOrderHeader where SalesOrderNumber = ''SO44000''';
dbcc freeproccache (0x0600090070286C0A40616699000000000000000000000000);
go
In fact, the new plan also chooses the newly created index. This is because other index metadata is newer than the original index, so in most cases, I’ll continue to update the original index for each DML operation; in fact, I may never ever use this index again because the new index will likely be chosen each time. If I did drop this extra ‘exact duplicate’ index I created or even the original one, this would solve the problem.
USE [AdventureWorks2012] GO IF EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'[Sales].[SalesOrderHeader]') AND name = N'AK_SalesOrderHeader_SalesOrderNum') DROP INDEX [AK_SalesOrderHeader_SalesOrderNum] ON [Sales].[SalesOrderHeader] WITH ( ONLINE = OFF ) GO
Now I can confirm that I’m using the original index with a quick run of the query and a review of the index usage stats.
Great article Neil. Our tool, Aireforge Studio, will check for duplicate, overlapping, missing and redundant indexes from the Advise module. You can download the free trial from http://www.aireforge.com.
See you at SQLBits.
Excellent information on your blog, thank you for taking the time to share with us. Amazing insight you have on this, it’s nice to find a website that details so much information about different artists.
Hi – So if I summise this correctly and to answer your actual question in your title. No there is no such performance issue when having a duplicate index defined on a table?
Hi Glen,
Actually, the overhead of maintaining unused duplicate indexes can cause performance issues (not to mention the additional storage taken).