One of the keys of administration in an Oracle RAC environment is understanding how redo and rollback are managed. The key here is realizing that each individual instance requires its own independent set of redo logs, and secondly, its own undo tablespace. Generally speaking, redo and undo are handled on a per-instance basis. Therefore, if an Oracle RAC database comprises three instances, each instance must have two groups of redo logs, one set for each instance, for a minimum of six online redo log groups. Each instance can, of course, have more, but just as with a regular instance, two is the minimum. In the case of the undo tablespace, each instance also must have its own undo tablespace. These files still must reside on the shared drive.
Redo logs and instance recovery
Instance recovery occurs when an instance goes down abruptly, either via a SHUTDOWN ABORT, a killing of a background process, or a crash of a node or the instance itself. After an ungraceful shutdown, it is necessary for the database to go through the process of rolling forward all information in the redo logs and rolling back any transactions that had not yet been committed. This process is known as instance recovery and is usually automatically performed by the SMON process.
In an Oracle RAC environment, the redo logs must be accessible from all instances for the purpose of performing instance recovery of a single instance or of multiple instances. Should instance recovery be required because a node goes down ungracefully (whatever the reason), one of the remaining instances must have access to the online redo logs belonging to the node that went down to perform the instance recovery. Thus, even though the instance is down, the data in the redo logs is accessible and can be rolled forward by a surviving instance, with any uncommitted transactions being rolled back. This happens immediately in an Oracle RAC environment, without the need to wait for the downed instance to come back online.
Here is an example of what you may see in the alert log of the instance performing instance recovery:
Sun Jun 13 12:32:54 2010
Instance recovery: looking for dead threads
Beginning instance recovery of 1 threads
Started redo scan
Sun Jun 13 12:33:10 2010
Completed redo scan
read 1918 KB redo, 103 data blocks need recovery
Started redo application at
Thread 1: logseq 11, block 2374
Recovery of Online Redo Log: Thread 1 Group 1 Seq 11 Reading mem 0
Mem# 0: +DATA/orcl/onlinelog/group_1.262.721568027
Mem# 1: +FLASH/orcl/onlinelog/group_1.258.721568047
Completed redo application of 0.44MB
Completed instance recovery at
Thread 1: logseq 11, block 6211, scn 1538116
95 data blocks read, 124 data blocks written, 1918 redo k-bytes read
The fact that instance recovery is done by a remaining node in the cluster means that when the crashed instance is restarted, no instance recovery is needed on that instance, because it will have already been done. If multiple instances go down, online instance recovery can still occur as long as at least one instance survives. If all instances go down, crash recovery is performed by the first instance to start up.
Redo logs and media recovery
Media recovery differs from instance recovery in that it cannot be done automatically—it requires manual intervention, and it may also require the application of archived redo logs from all instances. If it is necessary to perform media recovery on some or all of the database files, you must do this from a single node/instance. If you are recovering the entire database, all other instances must be shut down, and then you can mount the database on the node from which you have chosen to do recovery. If you are recovering a single file (or set of files) that does not impact the entire database, all instances can be open, but the file(s) that needs to be recovered must be offline and will therefore be inaccessible. The node that performs the media recovery must have read access to all archived redo logs that have been generated from all nodes.
Redo threads
As discussed, each instance is assigned a thread number, starting at 1, and the thread number for that instance should not change. The thread number is defined by the SPFILE parameter <sid>.THREAD=n, where n is the thread number for that instance. Thus, when a redo log group is created, it is assigned to a given instance using the thread number, like so:
alter database add logfile thread 2 group 5 '/ocfs/oradata/grid/grid/redo02_05.log' size 100m;
This example is a database on an OCFS drive.
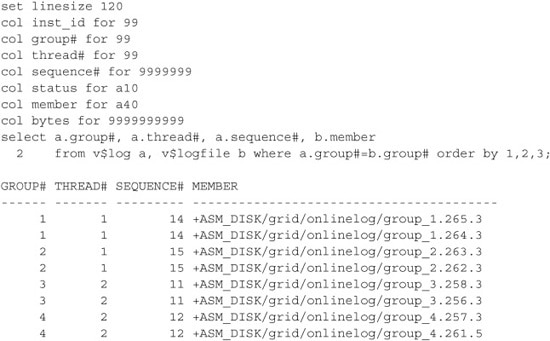
A query similar to the following can be used to view the online redo logs, their groups, and their threads. This example is on a cluster using ASM:
Leave a Reply