There are many myths and incorrect information shared online about the SQL Server table variable, and it would be easy for a SQL Server developer to assume that, based on the misinformation, using a table variable instead of a temporary table was a good idea. Using table variable is in fact easy, but there are things a developer should know before making such a decision. In this article, we will debunk some of the myths about table variable using real-world examples.
First, let’s understand how to use a table variable. It is very simple, as shown below:
DECLARE @Employees TABLE ( EmployeeID INT, FirstName VARCHAR(30), LastName VARCHAR(30), Gender CHAR(1) )
Then we can use this to insert data, select data and use them as tables.
Transaction scope and lifetime
Just like any local variable we create with a DECLARE statement, a table variable is also scoped to the stored procedure, batch, or user-defined function. On the other hand, temporary tables are only available to the current connection to the database for the current user. They are dropped when the connection is closed. Whenever there is a rollback of a transaction, it does not affect the table variables. As we can see in the output of the query below – even after a rollback, we are still seeing data in table variable whereas data in temporary table is cleaned up.
SET NOCOUNT ON DECLARE @Employee TABLE(Id INT) CREATE TABLE #Employee (Id INT) BEGIN TRAN INSERT #Employee VALUES(1),(2) INSERT @Employee VALUES(1),(2) /*Both have 2 rows*/ SELECT Id AS '#Table_ID' FROM #Employee SELECT Id AS '@Table_ID' FROM @Employee ROLLBACK PRINT 'AFTER ROLLBACK' PRINT '===============' /*Only table variable now has rows*/ SELECT Id AS '#Table_ID' FROM #Employee SELECT Id AS '@Table_ID' FROM @Employee DROP TABLE #Employee
Here is the output:

Table variables are accessible only within the batch or scope in which they are declared.
SET NOCOUNT ON DECLARE @Employee TABLE(Id INT) CREATE TABLE #Employee (Id INT) INSERT #Employee VALUES(1),(2) INSERT @Employee VALUES(1),(2) /*Both have 2 rows*/ SELECT Id AS '#Table_ID' FROM #Employee SELECT Id AS '@Table_ID' FROM @Employee GO -- GO is a default batch separator in SSMS SELECT Id AS '#Table_ID' FROM #Employee SELECT Id AS '@Table_ID' FROM @Employee -- this would fail as it’s in new batch
The example above would result in this error message:
Msg 1087, Level 15, State 2, Line 19 Must declare the table variable "@Employee"
Statistics and indexes
Table variables do not allow ALTER to the definition after they are declared. And prior to SQL Server 2014, they don’t allow non-clustered indexes to be created.
We also need to keep in mind that the estimation of the number of rows might be way off as compared to actual data in the table.
Here is the script which you can run to see the effect.
USE tempdb
GO
IF OBJECT_ID('PermanentEmployeeTable') IS NOT NULL
DROP TABLE PermanentEmployeeTable
GO
CREATE TABLE PermanentEmployeeTable (EmployeeID INT)
GO
CREATE INDEX idx_PermanentEmployeeTable ON PermanentEmployeeTable (EmployeeID)
GO
--insert 100000 rows into the PermanentEmployeeTable table
SET NOCOUNT ON
BEGIN TRANSACTION
DECLARE @loop INT
SET @loop = 0
WHILE @loop < 100000
BEGIN
INSERT INTO PermanentEmployeeTable
VALUES (@loop)
SET @loop = @loop + 1
END
COMMIT TRANSACTION
GO
--update stats with fullscan
UPDATE STATISTICS PermanentEmployeeTable WITH FULLSCAN
SET NOCOUNT ON
DECLARE @EmployeeTableVariable TABLE (EmployeeID INT)
BEGIN TRANSACTION
DECLARE @loop INT
SET @loop = 0
WHILE @loop < 100000
BEGIN
INSERT INTO @EmployeeTableVariable
VALUES (@loop)
SET @loop = @loop + 1
END
COMMIT TRANSACTION
SET STATISTICS PROFILE ON
SELECT *
FROM @EmployeeTableVariable tv
INNER JOIN PermanentEmployeeTable t ON tv.EmployeeID = t.EmployeeID
GO
SET STATISTICS PROFILE OFF
If we look at the query plan, we can see that the table variable has an estimation of only one row which is causing nested loop join for huge rows.

The problem shown above can be solved using option recompile in last statement as shown below.
SELECT * FROM @EmployeeTableVariable tv INNER JOIN PermanentEmployeeTable t ON tv.EmployeeID = t.EmployeeID OPTION (RECOMPILE)
This would cause the query optimizer to recompile the statement during run time and then it can look into the rows in the table variable.
This is another myth about table variable: if table variables have smaller sets of data, then they would be only memory resident. This information is not correct, and here’s the quick proof.
DECLARE @TableVariable TABLE(Column1 INT) INSERT INTO @TableVariable VALUES(1),(2) SELECT sys.fn_PhysLocFormatter(%%physloc%%) AS [File:Page:Slot] FROM @TableVariable
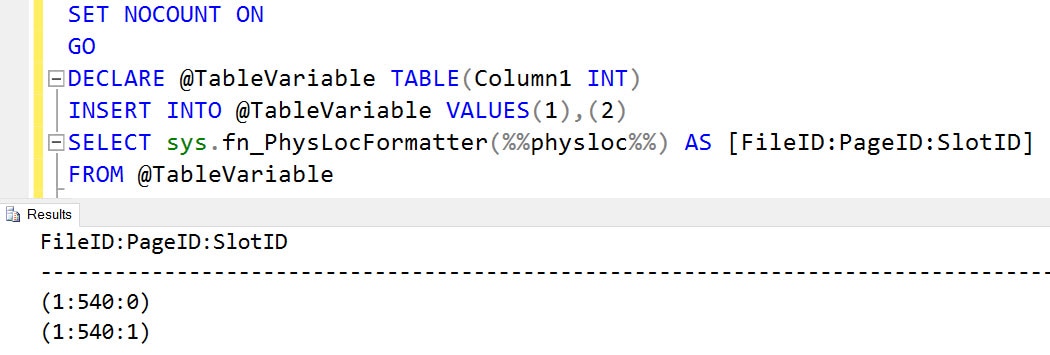
We can see here the location of the table variable. Both rows are stored in a physical page 540 in fileID 1. Along with the storage, it is also important to note that they have entries in transaction log file of tempdb system database.
It’s generally said that the performance of stored procedures may improve by using table variables, but whether this is the case with you or not, can’t easily be forecasted.
Leave a Reply