I am blessed to have traveled quite a bit. I make it a point to keep traveling with family at least two ro three times in a year. The best way to learn new cultures, befriend new people and explore new places can happen only when we move out of our comfort zone. I personally felt my daughter needs to get this exposure in her early age. This is the best way to find your feet and learn to make friendships with strangers in an environment which is completely new.
These explorations don’t just stop in my personal life; my exploration with product technologies are a natural extension. In this article, I will share some interesting observations I made when working with VARCHAR datatypes inside SQL Server. I am sure some of these are known to you, but a refresher like these are a great way to learn the internals of SQL Server.
Pitfall 1: Understanding Fixed length data usage
The first pitis around how is data stored for a single character data usage. Assume we need to create a column to store Gender (M, F, U). Now there are multiple options but the most common way to store this is using it as VARCHAR(1) or as CHAR(1). The general rule of thumb always says to use a fixed length datatype when we know the length is always a constant. Have you ever thought about the reason? Why is this the case? In the next section, let me show you know this can impact the way data is stored.
USE TEMPDB
GO
CREATE TABLE SmallVariableStringSizes
(
Varchar1Col varchar(1)
)
GO
SET NOCOUNT ON
INSERT SmallVariableStringSizes VALUES ('a')
GO 100000
— Next, deal with the fixed size allocation
CREATE TABLE SmallFixedStringSizes
(
Char1Col char(1)
)
GO
SET NOCOUNT ON
INSERT SmallFixedStringSizes VALUES ('a')
GO 100000
In the above code we have created two tables with a single column and let us compare the average record size in bytes for each of the table.
SELECT avg_record_size_in_bytes, page_count, * FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('SmallVariableStringSizes'), NULL, NULL, 'detailed')
SELECT avg_record_size_in_bytes, page_count, * FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('SmallFixedStringSizes'), NULL, NULL, 'detailed')
GO
On my laptop, the value looks like:
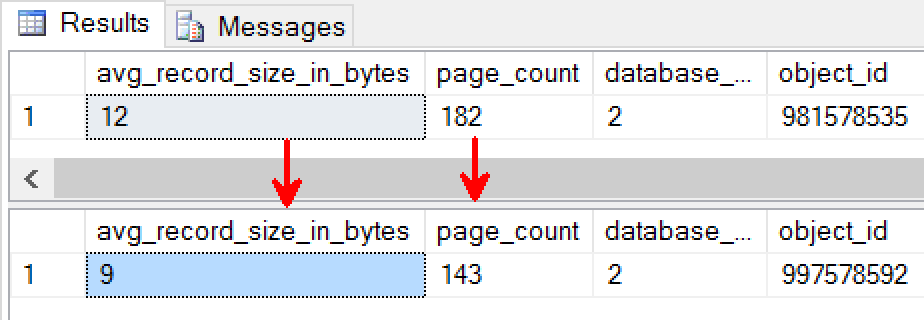
As you can see the Fixed String size is smaller and the number of pages used to store the same amount of data is also ~20% lesser. This means quite a bit and the difference is apparent.
How can this be bridged? To solve this, you can see how the overhead is removed if we use a compression on top of our variable length datatypes.
CREATE CLUSTERED INDEX CL_SmallVariableStringSizes ON SmallVariableStringSizes(Varchar1Col) with (data_compression = row) GO
Pitfall 2: Understanding default size
This is one of the most common mistakes that developers make when working with databases. They don’t understand how datatypes behave in standard usage patterns. Let us take two options of usage for VARCHAR datatypes as shown below, what is the expected output?
USE TEMPDB
GO
DECLARE @Pinal VARCHAR;
SET @Pinal = REPLICATE('a', 255);
SELECT LEN(@Pinal);
SELECT LEN(CAST(REPLICATE('a', 255) AS VARCHAR));
Ideally, in this case, we expect this to be the same value as part of output. You will be surprised because the output is:
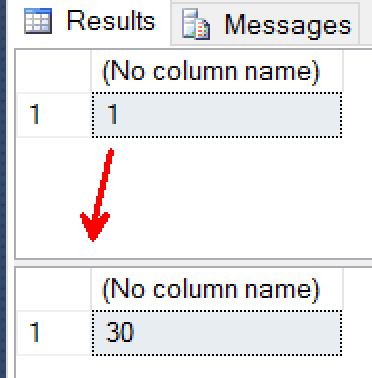
Were you aware of this pitfall? The default for usage of declarative VARCHAR datatype is 1 character while when used inside a CAST operator is 30 characters.
Conclusion
These are two of the most common mistakes one can make when designing and modeling data using VARCHAR datatypes inside SQL Server. Hopefully, these examples will give you a starting point to consider when coding . Learning and exploring SQL Server behaviors is something I strongly suggest you do regularly. Learn, share and be aware of these pitfalls.
Leave a Reply