Over last 18 months, I’ve given several SQL Saturday (and a PASS Virtual DBA) presentations on indexes. These presentations have evolved and I find it hard to complete the material I want to address in 60 minutes. But the more I dive into the material, the more I am learning.
Several times I have been asked about putting a second (or more) column into the SQL index definition as opposed to putting the second column in an INCLUDE clause—i.e., consider the following two (nonclustered, covering) index definitions:
CREATE NONCLUSTERED INDEX IX_Consumer_UpdateDate1 on dbo.Consumer(UpdateDate,CreateDate)
INCLUDE (FirstName,MiddleName,LastName,EmailAddress)
WITH (ONLINE = ON, DATA_COMPRESSION = ROW)
and
CREATE NONCLUSTERED INDEX IX_Consumer_UpdateDate2 on dbo.Consumer(UpdateDate)
INCLUDE (CreateDate,FirstName,MiddleName,LastName,EmailAddress)
WITH (ONLINE = ON, DATA_COMPRESSION = ROW)
** You should always consider ROW data_compression
and I’ve been asked which is better. Usually, I’ve given an off-the-wall answer, something about whether the second column is used for a range or needed to assert ascending properties. While preparing for my last SQL Saturday presentation (in Houston), I finally dove into exactly what was happening under the covers.
Consider the following SQL queries (I’m not at liberty to discuss the database this came from):
SELECT ConsumerID,
ISNULL(FirstName + ' ','') + ' ' + ISNULL(MiddleName + ' ','')
+ ' ' + ISNULL(LastName,'') AS FullName,
UpdateDate,
CreateDate
FROM dbo.Consumer WITH (INDEX(IX_Consumer_UpdateDate1))
WHERE COALESCE(UpdateDate,CreateDate) < DATEADD(dd,-450,GETUTCDATE());
SELECT ConsumerID,
ISNULL(FirstName + ' ','') + ' ' + ISNULL(MiddleName + ' ','')
+ ' ' + ISNULL(LastName,'') AS FullName,
UpdateDate,
CreateDate
FROM dbo.Consumer WITH (INDEX(IX_Consumer_UpdateDate2))
WHERE COALESCE(UpdateDate,CreateDate) < DATEADD(dd,-450,GETUTCDATE());
Both SQL queries produce identical query plans (except for index seek on respective index), but the second query came in with slightly less logical reads. Why? Because the intermediate leaves were only carrying UpdateDate and ConsumerID in index 2. With index 1, the intermediate leaves had to also include the CreateDate. For a large table, this may result in a fair amount of extra logical reads to traverse the B-Tree down to the leaf level.
In the example above, the Consumer table has 603,180,834 rows. The result set contained 1,003,486 rows. However, Logical page reads for Index 1 were 2,509,661, while for Index 2, they were 2,501,940—roughly 8,000 less logical reads (pages) for index 2. CPU cycles were 193,533 ms and 186,437 ms respectively—a seven-second reduction for index 2—probably also because of the fewer logical reads. Query cost for Index 1 and 2 was 2368.13. The Query plans were:
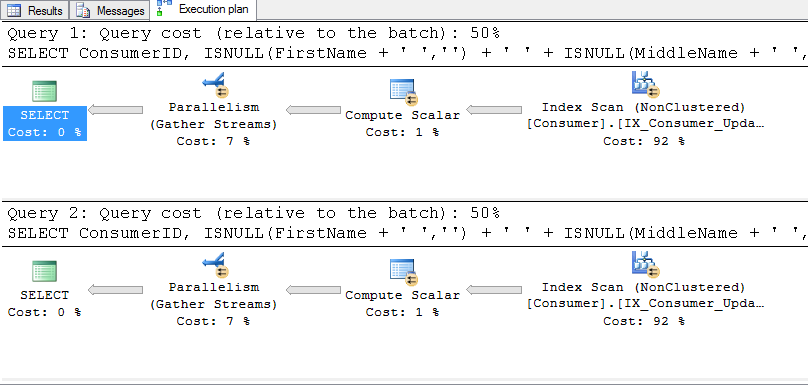
So, unless you have a very specific reason to include a second column in the index definition, you should consider including it in the INCLUDE clause (potentially less logical IO).
Questions about SQL indexing? Please ask!
Leave a Reply