At some point in your career as a data professional you are going to fill up an entire drive with data. It is not a question of “if,” but a matter of “when” this will happen.
When the files in question are SQL Server database files (data or log) then administrators reach for a familiar tool:
DBCC SHRINKDATAFILE()
This command allows for SQL Server to release unused space and shrink the size of the file allocated on disk. But it comes with a cost (link). In order to shrink the file down, SQL Server will move the data pages around on disk. This leads to internal fragmentation, which happens to be the main ingredient of the dish we like to call “poor performance.”
What is interesting to note here is that even if we drop a table to free up space the data file on disk does not decrease in size. Once SQL Server allocates space on disk there are only two ways to reclaim that space for the O/S.
- Create a new database, of a smaller defined size, and migrate your data (in the old days we called this a logical dump, more on that later)
- DBCC SHRINKDATAFILE()
Most data professionals reach for the second option. It’s easier than the first option.
Easier does not always mean better.
Let’s look at how you would shrink a Windows Azure SQL Database (WASD). We’ll create a quick sample database, migrate it to WASD, cause it to expand, free up space, and revert back to a smaller size. For on-premises version of SQL Server we know that this will result in fragmentation. What will the fragmentation look like for WASD?
To the sample code!
Let’s create a database in SQL 2012:
CREATE DATABASE [AzureShrink] GO
Next, let’s add a table. For quick examples like this I use sys.messages like this:
SELECT * INTO dbo.messages FROM sys.messages
Now we have a table with some data. Since we are going to deploy this to WASD, we need to create ourselves a clustered index:
CREATE CLUSTERED INDEX [CI_MessageID] ON [dbo].[messages] ( [message_id] ASC ) ON [PRIMARY] GO
OK, now let’s populate a bit more data. I want to create one table with about 400MB of data to start:
INSERT INTO dbo.messages SELECT * FROM sys.messages GO 5
Let’s have a look at the database size now, we will use sp_helpdb:
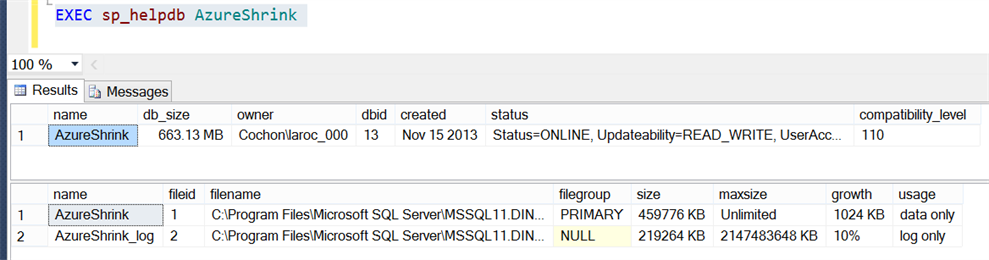
OK, the database size is 663MB, which is the sum of the data (459776 KB or 449 MB) and log (219264 KB or 214 MB) files.
Let’s get this published to Azure. I have a handful of options to migrate my data to WASD these days but in this case I’m going to use SSMS to publish directly to my WASD instance.
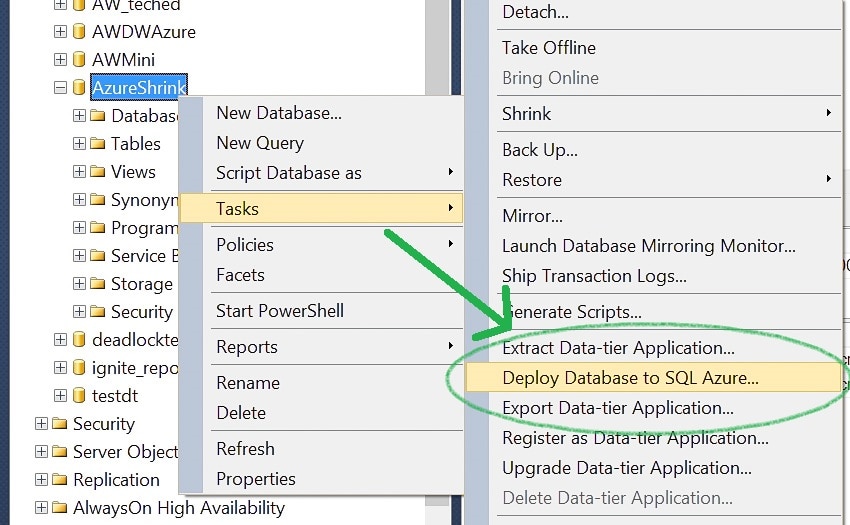
We will do the minimum size for right now, Web Edition and 1GB:
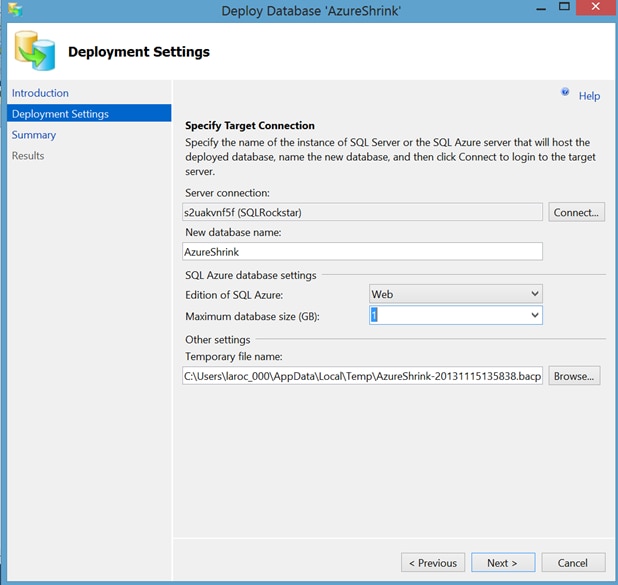
Success!
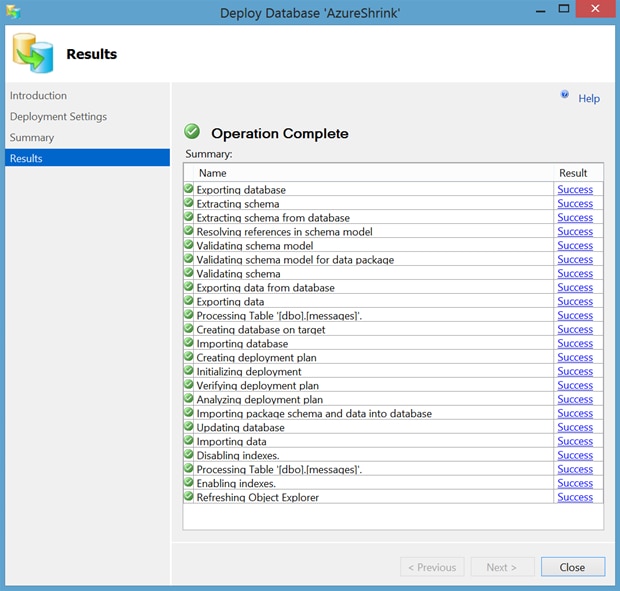
OK, let’s connect to the WASD using SSMS and verify the space using sp_helpdb:
Msg 2812, Level 16, State 62, Line 1 Could not find stored procedure 'sp_helpdb'.
Whoops. Looks like we need to do this differently. That’s OK, though I’m not about to yell at MSFT simply because my cheese has been moved. I’m a big boy, I know where to go to find my cheese. I will use the WASD manage database portal:
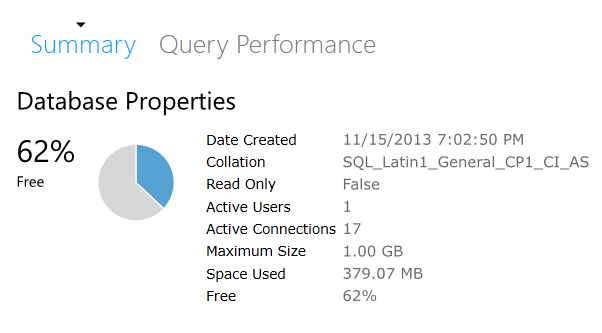
Well, that’s rather interesting. My database is only 379 MB? Why is that?
It’s because in WASD they don’t care about the size of your log, only the size of your data file.
The natural question is why 379 MB shown and not the original 449 MB? I suspect it is due to the nature of the BCP done by the deploy method from SSMS, and that there is less fragmentation on disk right now. This reminds me of the logical dumps I used to do in Sybase. A logical dump would output your data to flat files, allowing you to do a restore into a new database that was created with a smaller size. This was how you shrank a database before SQL Server came along and gave us one button to fix all our space problems.
In fact, let’s go check the fragmentation on each table, both WASD and on-premises. This is what I see for the original table:

And this is what I see against the WASD instance:
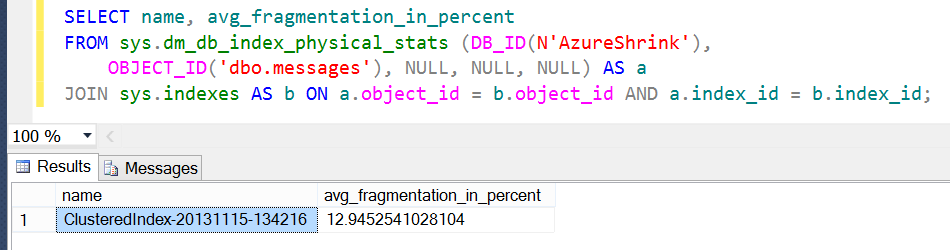
Very different results. You can see that the deploy process did not bring along the additional fragmentation. This is responsible for the roughly 70 MB difference in the size of the data file.
OK, let’s push some additional data into our WASD instance and nudge it over the 1GB size limit. I’ll do this the easy way, let’s just create a copy of the existing table:
SELECT * INTO dbo.messages2 FROM dbo.messages
Whoops:
Msg 40510, Level 16, State 1, Line 1 Statement 'SELECT INTO' is not supported in this version of SQL Server.
OK, let’s try something else then. One method would be for me to create a new table:
CREATE TABLE [dbo].[messages2]( [message_id] [int] NOT NULL, [language_id] [smallint] NOT NULL, [severity] [tinyint] NULL, [is_event_logged] [bit] NOT NULL, [text] [nvarchar](2048) NOT NULL ) GO CREATE CLUSTERED INDEX [CI_MessageID] ON [dbo].[messages2] ( [message_id] ASC ) ON [PRIMARY] GO
Now, let’s insert some data! I’ll loop through six times:
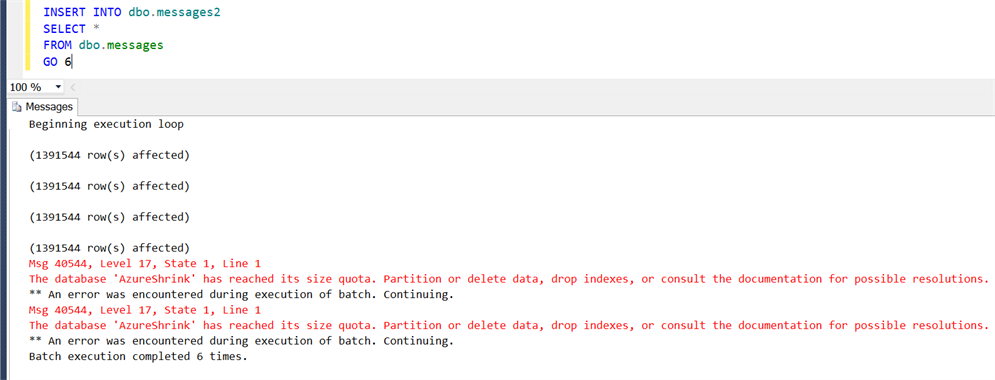
Whoops…I seem to have overshot the mark there. Wonder how full we are now?
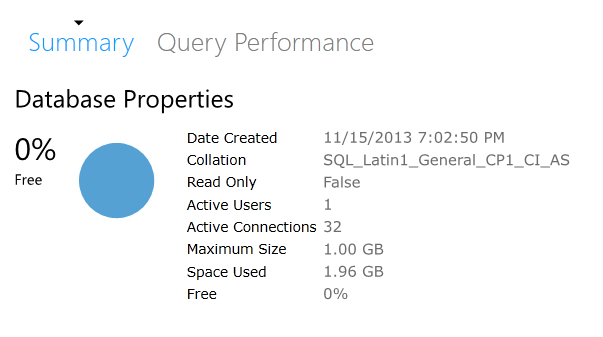
OK, so my database has a max of 1GB and now has 1.96GB. Can I insert ANYTHING at this point?

Nope.
If you get this error message then you will need to alter the maxsize of the database in order to continue inserting data. This can be done through the portal:
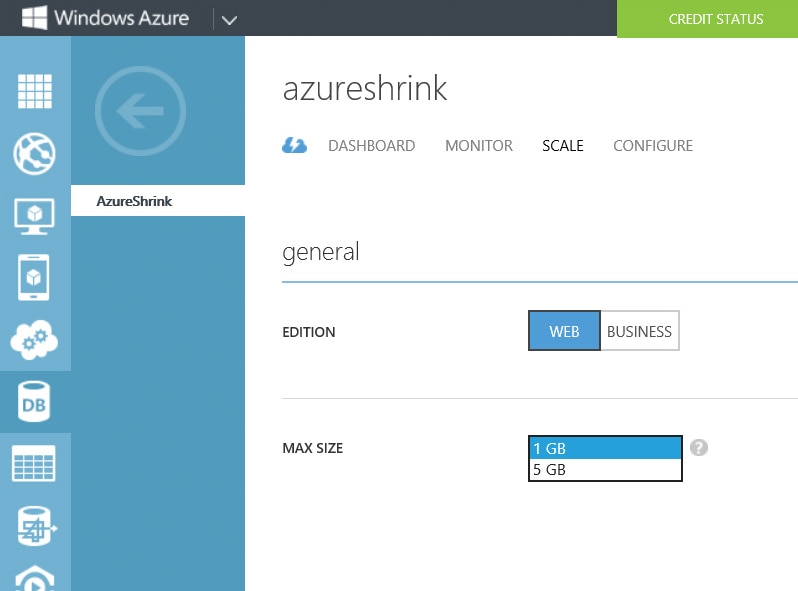
I can also issue the following statement:
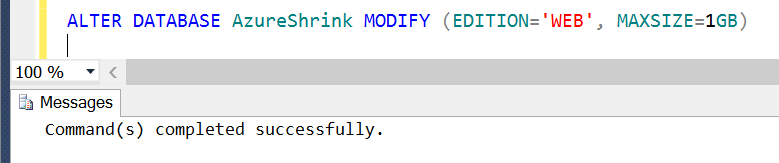
ALTER DATABASE AzureShrink MODIFY (EDITION='WEB', MAXSIZE=5GB)
And now we have some free space:
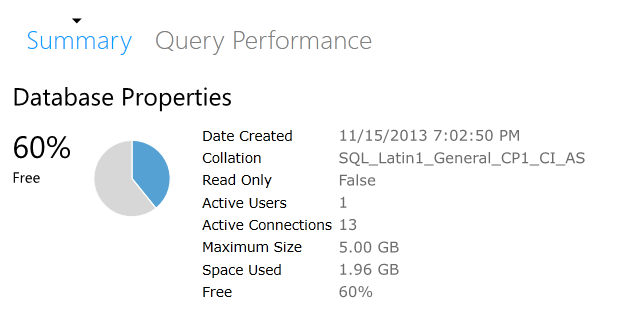
And I can insert data again–YEAH, YUMMY DATA! [Note, it may take up to 15 minutes for you to be able to insert data while WASD makes certain your ALTER DATABASE changes have been replicated.]
So, now we are at the place where a traditional DBA has found themselves many times before: the need to reclaim space by shrinking a database
We know what happens when you shrink a database in an on-premises version of SQL Server: fragmentation. What about for WASD? What happens then?
Nothing happens, because you can’t shrink.
That’s right. You’ve read this far and I’ve kicked you to the curb by telling you that there is no shrink option in WASD. If you want to shrink your database you need to truncate some data, or drop some tables.
Go ahead and try to issue the following:
DBCC SHRINKDATABASE(N'AzureShrink' ) GO
You will get this:
Msg 40518, Level 16, State 1, Line 1 DBCC command 'SHRINKDATABASE' is not supported in this version of SQL Server.
Remember that in WASD you pay for two things: storage and egress. Just because you have defined a max size of your WASD to be 5GB doesn’t mean you pay for all 5GB, you only pay for the space you are using. Likewise, you only pay for egress when your data leaves the data center.
So if you need to shrink, then you need to delete some data from your tables. In our case, we can drop the table we just created:
DROP TABLE dbo.messages2
That gives us this for space now:
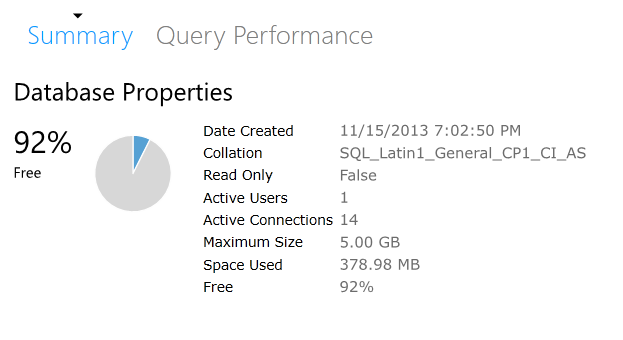
If you are still concerned about have the 5GB max size, then simply issue another ALTER DATABASE:
And, as a sanity check, what should the fragmentation be in the table we didn’t touch (dbo.messages)? It should be the same as before, right?
Indeed:

That looks familiar, right? Slight difference is due to my inserting a row into the table as a test after we had increased the max size to 5GB.
So, shrinking a database in WASD does NOT lead to fragmentation in the same way as the on-premises version of SQL Server. This is because the DBCC SHRINKFILE command is not available. As a result, you need to manually truncate data and not rely on a DBCC command to move files around for you and then free up space.
?
DBCC SHRINKFILE () exists today in Azure SQL Database. This blog post comes up first when searching obvious search terms. Care to update?