The Oracle cost-based optimizer (CBO) displays the cost number for a query, or an estimate based on statistics and calculations. The cost number is the estimated number of physical I/O operations Oracle thinks it will have to find the requested data, based solely on statistics. Understanding how the CBO works can help improve your Oracle tuning efforts.
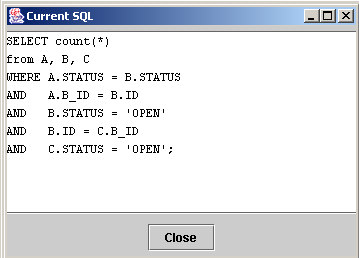
Example Cost Analysis of a Selected SQL Query
NOTE
I use the row numbers and find them useful, especially to see the intermediate result set sizes, and so on. A more accurate row count is in the SQL Trace, which is covered in my SQL Tuning course.
How the CBO has evolved
Notice how the CBO has evolved over the releases:
- If no statistics are present, CBO makes assumptions
- Oracle 10g+ uses CBO (even Dictionary SQL)
- Oracle 9i+ uses:
- CBO if any statistics exist
- CBO if hints exist
- CBO if accessing a partitioned objects
NOTE
I have noticed I have had to use fewer and fewer hints as the database progresses.
The CBO cost factor
Cost factor is an estimated number of physical I/O operations Oracle thinks it will have to do, based on statistics. Over time, the basic formula has evolved from just estimated physical I/O to includ additional statistics:
Cost=PHYS IO + Logical IO/1000 +NetIO*1.5
It assumes even distribution when using indexes (unless histograms are implemented). CBO costs out each Join to select a driving table.
Cost factors differ across releases as well:
- In general, the cost factor relies heavily on assumed multiblock read-aheads (MRAs)
- In 10g:
- index_fast_cull_scans considers number of leaf blocks
- takes into account high-water mark
- In 9i
- Cost reflects machine speed at performing multiblock reads, along with 8i
- In 8i
- Cost reflects number of multiblock reads based on statistics
Oracle arrives at the ‘cost’ number that appears in the explain plan according to some general principles:
- Selectivity (discussed with WHERE clause section)
- Clustering factor (discussed with Index section)
- Full table scan = num rows/MRA
- Fast Full Scan = num rows/MRA
- Unique Scae = 1
- Range Scan = (#leaf blocks +selectivity) * Clustering Factor
- Index-only scan =#leafblocks
The CBO relies heavily upon multi-block read ahead. Selectivity is related to the estimated row counts. Selectivity is computed as a percentage of the whole, unless a histogram exists; in this case, Oracle can get a better idea of cardinality. Note that Oracle assumes even data distribution unless there is a histogram on the predicate column.
Clustering Factor is the relationship of the Index leaf blocks and the table. The more the table is in the sequence of the index key column(s), the lower the clustering factor, and the more likely Oracle will use this index on a range scan.
Example query
The query shown below seems to have room for improvement.
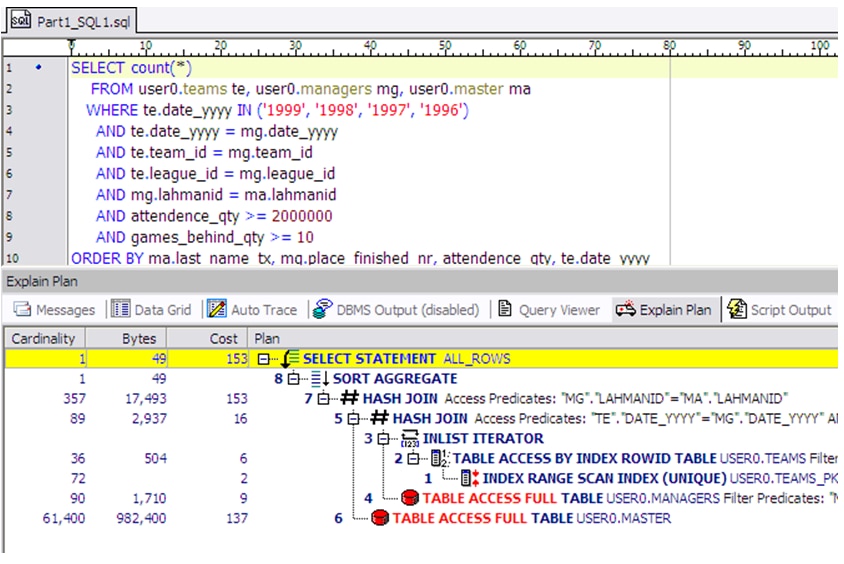
An example SQL Query Cost Analysis Showing Room for Improvement
Notice the first few steps have nice low numbers, then step 5 (very last line) is a full table scan on the master table. It gives the appearance of a missing index perhaps.
The CBO cardinality (rows) is useful to see if most of the rows were indeed eliminated first and the size of the intermediate result sets.
The CBO cost shows an estimated number of physical I/O operations. Dan uses this number mostly to see the size of range scans across indexes.
The cost number on the very first line is the cost of the query and it is this number that is compared with other permutations of this same query to see which one will be used. The first one with the lowest cost will be used. The CBO Trace (the 10053) will show the CBO decision process.
Nice post. I learn something nnew and challenging on sites I stumbleupon evfery day.
It’s always exciting to read articles from other writers and practice a little something from other web sites.