Read Part 1
Read Part 2
This was originally intended to be a two-part blog, but I keep finding other areas to explore. Shortly after completing Part 2, I realized that perhaps I should traverse a row compressed index to see how the SQL Server® structures it. Then, the other night, I gave a presentation to our local user’s group on Parts 1, 2, and a row compressed index traversal when I realized that I really needed another example of when the Primary Key and the Clustered Index are not the same. This blog will address those areas as well as present a summary of all the results from Part 1, 2, and 3.
This is a continuation of Climbing the SQL Server Index B-tree. In Part 1, we dove down into the SQL Server pages for a Clustered Index in the Sales.SalesOrderDetail table in the AdventureWorks2012 database. In Part 2, we examined the data pages of the same table/database for unique non-clustered and non-clustered indexes. Part 3 addresses the structure of a row compressed index, as well as the use case when the Primary Key and Clustered Index are not the same. We do this to try and ascertain how SQL Server optimizers might use them and strive to gain some insight from a performance advantage.
These blogs are not intended to replace or even compete with more technological index papers by Paul Randall or Kimberly Tripp (see references). Its purpose is to try and understand how SQL Server implements indexes, their underlying structure, and where performance benefits might lie from a layman’s viewpoint. However, this blog series is at the intermediate level; some knowledge of TSQL and Indexes is assumed.
The TSQL script used to evaluate the indexes and the discussion below can be copied from this post.
It is well commented so that the reader’s computer can obtain similar results (this script applies only to Part 3). I will note, however, that depending on SQL Server configuration and local computer memory, specific page ids may vary from those discussed here. (However, the actual data values should remain constant.)
Row Compressed Non-Clustered Covering Index
The analysis below will use the same non-clustered index as in Part 2 but with the Data_Compression option as shown below:
CREATE NONCLUSTERED INDEX IDX_SalesOrderDetail_ModifiedDate3
ON Sales.SalesOrderDetail(ModifiedDate)
INCLUDE (CarrierTrackingNumber,OrderQty, ProductID)
WITH (DATA_COMPRESSION = ROW)
We get the index id (indid) from
SELECT ID,Name,Dpages,reserved,used,rowcnt,indid
FROM sys.sysindexes
WHERE [Name] IN ('IDX_SalesOrderDetail_ModifiedDate3');
GO
--indid = 5
Looking at the index contents:
SELECT OBJECT_NAME(object_id), index_id, partition_id,allocated_page_page_id,
is_iam_page, page_type, page_type_desc, page_level,next_page_file_id,next_page_page_id,previous_page_file_id,
previous_page_page_id, is_page_compressed
FROM sys.dm_db_database_page_allocations (DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'), 5,1,'Detailed')
WHERE page_level IS NOT NULL
--AND page_level = 0
ORDER BY (page_level+page_type) DESC,allocated_page_page_id
We get
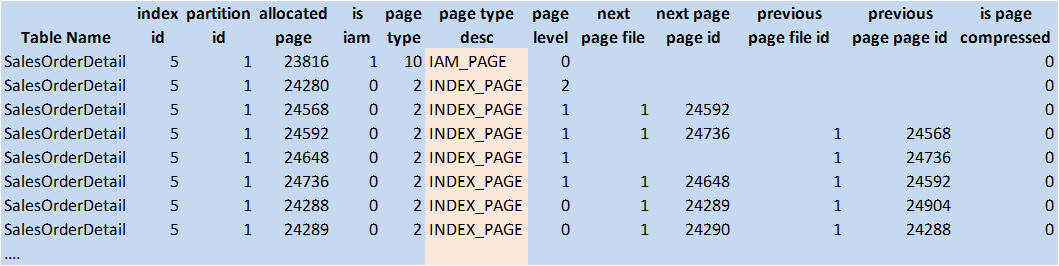
Figure 1: sys.dm_db_database_page_allocations results unique index (© 2017 | ByrdNest Consulting)
There is one page at level 2 (24280, root), 4 intermediate level pages at level 1, and 480 pages at level 0 (not counting iam_page). If we now look at the root page with
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,24280,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
The second result set looks like

Figure 2: Root node nonclustered index (© 2017 | ByrdNest Consulting)
The four rows above represent the page boundaries for the intermediate nodes. If we traverse down the (NULL,NULL,NULL) boundary (24568) with
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,24568,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
We get

Figure 3: Intermediate node nonclustered index (© 2017 | ByrdNest Consulting)
Looking at Figure 3, we have the index key (ModifiedDate) plus the Clustered Index Keys SalesOrderID and SalesOrderDetailID. If we continue to traverse the NULL boundary, we need to look at ChildPageID = 24512. Note the second boundary at (2005-07-01,43681,206). Since we are at level 1, the next level will contain the row data for the index.
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,24512,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
Yields (second result set at leaf level):
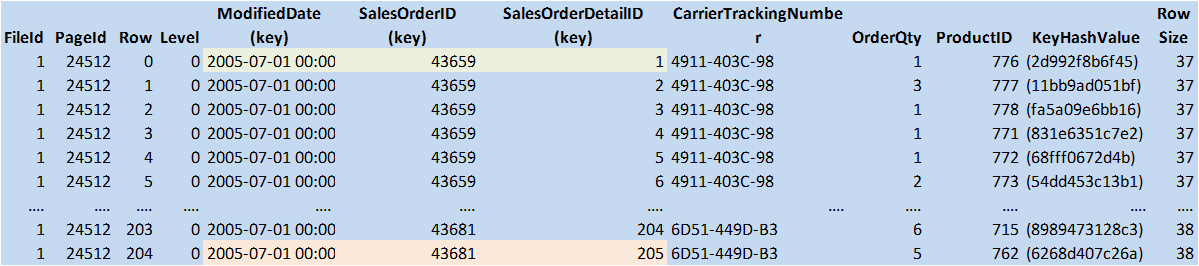
Figure 4: Row Compressed Non-Clustered Index (© 2017 | ByrdNest Consulting)
First row of data is for SalesOrderDetailID = 1, which is lowest data value matching the NULL boundary. Note that the last row is SalesOrderDetailID = 205, which is one less than the previous result. Interesting that the result set does not show effect of row compression, but the row size = 37 or 38. The same index without compression (Part 2) had a row size of 54. The effect of compression from 54 to 37/38 does allow more rows to be compressed into the data page, hence less logical reads. This translates that with no compression, there were 144 rows in the first data page. Now with row compression, there are 205 rows.
Primary Key and Clustered Index not the same
Since the original Primary Key was based on SalesOrderID and SalesOrderDetailID (which is an identity column) we can easily break the Primary Key (PK) and Clustered Index (CI) up by
--Drop Original PK (clustered index and PK the same)
ALTER TABLE Sales.SalesOrderDetail DROP CONSTRAINT PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID;
GO
--Add Non-clustered PK
ALTER TABLE Sales.SalesOrderDetail ADD CONSTRAINT PK_SalesOrderDetail_SalesOrderDetailID PRIMARY KEY NONCLUSTERED (SalesOrderDetailID);
GO
--Add Clustered Index
CREATE CLUSTERED INDEX CIDX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID ON Sales.SalesOrderDetail(SalesOrderID,SalesOrderDetailID);
GO
This makes the Primary Key based only on SalesOrderDetailID and the Clustered Index is as before (SalesOrderID, SalesOrderDetailID). Note the Nonclustered option in the PK definition.
So, let’s now see how the Primary Key index is structured.
SELECT *
FROM sys.sysindexes
WHERE [Name] IN ('PK_SalesOrderDetail_SalesOrderDetailID');
GO
--indid = 6
Looking at the index contents:
SELECT OBJECT_NAME(object_id), index_id, partition_id,allocated_page_page_id,
is_iam_page, page_type,
page_type_desc,
page_level,next_page_file_id,next_page_page_id,previous_page_file_id,
previous_page_page_id, is_page_compressed
FROM sys.dm_db_database_page_allocations (DB_ID(), OBJECT_ID('Sales.SalesOrderDetail'), 6,1,'Detailed')
WHERE page_level IS NOT NULL
ORDER BY (page_level+page_type) DESC,allocated_page_page_id
We get

Figure 5: PK Index page data (© 2017 | ByrdNest Consulting)
Interesting! Only one page at level 1 and this is the root page. Because there is just a single column in the PK definition, SQL Server is able to pack all the rows into 215 data pages with just a root node as a pointer (no intermediate levels). Looking at the root page (30896)
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,30896,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
With result set of
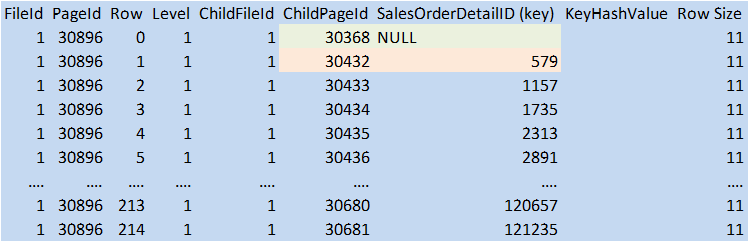
The result mirrors the 215 data pages from previous query. Interestingly, the PK is used to traverse the tree, not the CI (same type results when we looked at the unique index in Part 2). If we traverse the NULL boundary page (30368):
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,30368,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
We get (second result set):
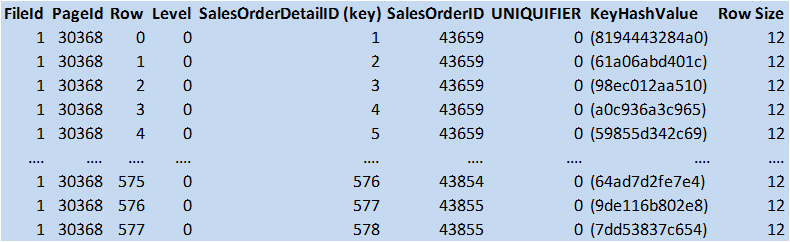
Figure 6: PK Data Page (© 2017 | ByrdNest Consulting)
Interestingly, SalesOrderID shows up in the data set as well as a new column UNIQUIFIER. This is because the pointer from the index has to point back to the CI. Since we didn’t specify the CI as being unique, SQL Server helps us by adding the UNIQUIFIER column to the CI. The UNIQUIFIER column is zero for all rows since the SalesOrderDetailID provided uniqueness. Let’s go back now and look at the CI as we defined it (not unique).
SELECT *
FROM sys.sysindexes
WHERE [Name] IN ('CIDX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID');
--indid = 1
Looking at the index contents (indid = 1)
SELECT OBJECT_NAME(object_id), index_id, partition_id,allocated_page_page_id,
is_iam_page, page_type,page_type_desc,page_level,next_page_file_id,
next_page_page_id,previous_page_file_id,previous_page_page_id,is_page_compressed
FROM sys.dm_db_database_page_allocations (DB_ID(),
OBJECT_ID('Sales.SalesOrderDetail'), 1,1,'Detailed')
WHERE page_level IS NOT NULL
ORDER BY (page_level+page_type) DESC,allocated_page_page_id
We get

Figure 7: Clustered Index Structure (© 2017 | ByrdNest Consulting)
Root level page is 52 (level 2) with 7 intermediate level pages (level 1) and 1315 leaf level pages (level 0). Looking at the root page (528):
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,528,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
GO
We get
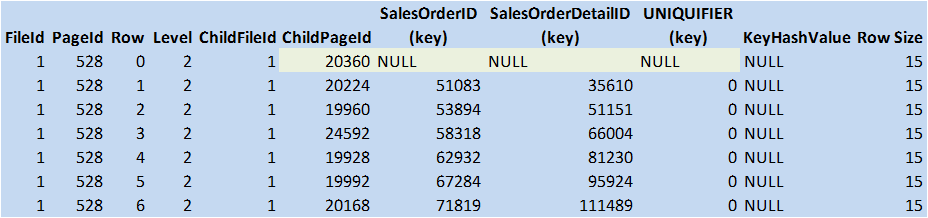
Figure 8: Clustered Index Root Level (© 2017 | ByrdNest Consulting)
Note the additional column for UNIQUIFER. Traversing down the (NULL,NULL,NULL) boundary
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,20360,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
We get

Figure 9: Intermediate Level 1 CI (© 2017 | ByrdNest Consulting)
Now let’s look at the leaf level for PageID = 19856:
DBCC TRACEON(3604)
DBCC PAGE('AdventureWorks2012',1,19856,3) WITH TABLERESULTS
DBCC TRACEOFF(3604)
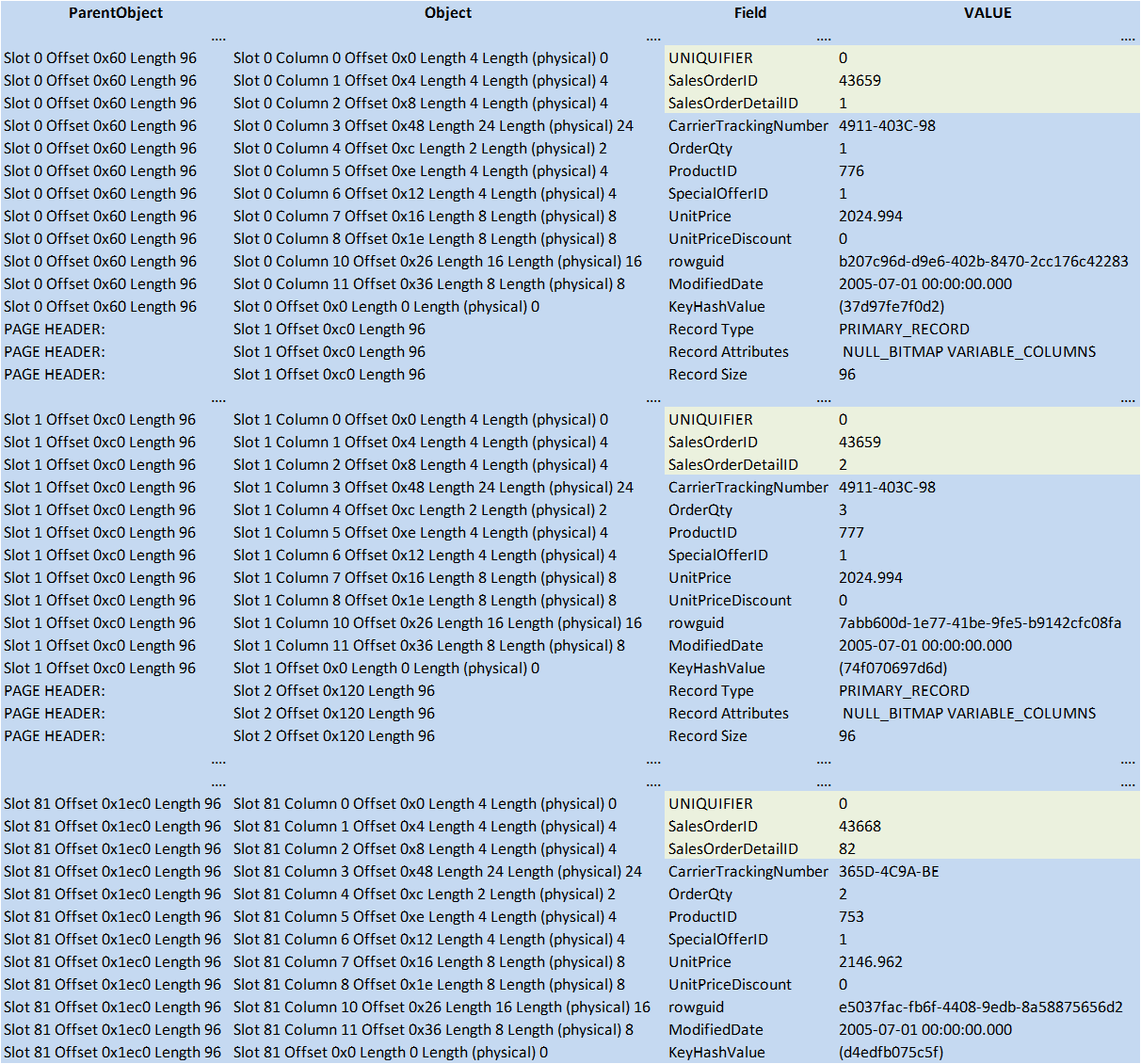
Figure 10: CI Data Page (© 2017 | ByrdNest Consulting)
Resulting in 82 data rows in first leaf page and UNIQUIFIER = 0 for all rows.
Non-Clustered Covering Index (as in Part 2)
If we now go back and look at the non-clustered covering index with row compression as discussed above:
SELECT ID,Name,Dpages,reserved,used,rowcnt,indid
FROM sys.sysindexes
WHERE [Name] IN ('IDX_SalesOrderDetail_ModifiedDate3');
--indid = 5
The index id remains 5 even with the changes in PK and CI. Then, looking at the index structure (same code as before), we get

Figure 11: Non-clustered Index Structure (© 2017 | ByrdNest Consulting)
Where there is the root page at Level 2, 214 index pages at Level 1, and 497 (excluding the IAM_Page). Looking at the first leaf page (26984), we get
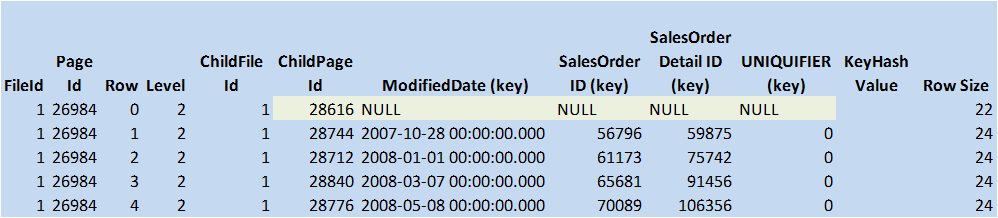
Figure 12: Non-clustered Root Page (© 2017 | ByrdNest Consulting)
There are only five boundaries at the root level (2). Just as before with the CI, the UNIQUIFIER is still being carried along (because we didn’t specify unique!) Traversing the (NULL,NULL,NULL) boundary (Page 28616) we see

Figure 13: Non-Clustered Intermediate node (© 2017 | ByrdNest Consulting)
with 269 page boundaries. Still traversing the (NULL,NULL,NULL) boundary (Page 28456) to the leaf level:

Figure 14: Non-clustered Leaf node (© 2017 | ByrdNest Consulting)
with 200 data rows in the first leaf. From the first example, there were 205 data rows in the first leaf node. Obviously, having to carry along the UNIQUIFIER takes additional space within all the index pages.
If we go back and re-specify the Clustered Index to be UNIQUE
IF EXISTS (SELECT 1 FROM sys.indexes WHERE name =
'CIDX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID')
DROP INDEX CIDX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID ON
Sales.SalesOrderDetail;
GO
CREATE UNIQUE CLUSTERED INDEX CIDX_SalesOrderDetail_SalesOrderID_SalesOrderDetailID
ON Sales.SalesOrderDetail(SalesOrderID,SalesOrderDetailID);
GO
We get essentially the same results we saw in the Part 1 traversal of the Clustered Index.
Summary
Results were as expected, except I was surprised by forgetting to specify UNIQUE for the clustered index when splitting it apart from the Primary Key. A summary chart for Parts 1, 2, and 3 is shown below:

Figure 15: Index Summary (© 2017 | ByrdNest Consulting)
The more I study this chart, the more it reinforces all the lessons I’ve learned over the years working with SQL Server indexes. Some of the more obvious points are (in no particular order or priority):
- Indexes do cost storage space and increased maintenance for data modification statements (inserts, deletes, updates).
- Splitting the Primary Key and Clustered Index do cost more storage than when the same.
- And may cost additional if you forget to specify the Clustered Index as unique.
- Row Compression does help reduce storage as well as logical reads.
- The b-tree traversal is a very effective way to quickly get to individual rows (mainly because of the exponential growth within the intermediate levels, i.e., even for very large indexes (rows), there will be very few levels needed to get down to an individual row).
- Keeping index definitions narrow really helps to compact an index b-tree.
- While covering indexes are great for query performance, you should still remember that included row width can/will affect logical reads. Keep number of columns and column width to a minimum.
- If computed columns are included within an index definition, that data will be persisted within the index.
- Although not specifically covered in this paper, be aware of duplicate or near-duplicated indexes suggested by the query optimizer. 99.99% of the time, you should not have the same first column in an index as another index.
- Also, not specifically covered in this paper: make sure first column in index definition is selective. Rarely will the optimizer use an index that results in a result set more than 5% of the total data in that table; e.g., an index based on gender does not have enough selectivity.
This excursion through the various indexes was a continuous learning experience for me. I hope it has been same for you. I welcome any questions.
Leave a Reply