Using hash indexes requires the use of hash clusters. When you create a cluster or hash cluster, you define a cluster key. The cluster key tells Oracle how to store the tables in the cluster. When data is stored, all the rows relating to the cluster key are stored in the same database blocks, regardless of what table they belong to. With the data being stored in the same database blocks, using the hash index for an exact match in a WHERE clause enables Oracle to access the data by performing one hash function and one I/O—as opposed to accessing the data by using a b-tree index with a binary height of three, where potentially four I/Os would need to be performed to retrieve the data.
As shown in Figiure 1, the query is an equivalence query, matching the hashed column to an exact value. Oracle can quickly use that value to determine where the row is physically stored, based on the hashing function.
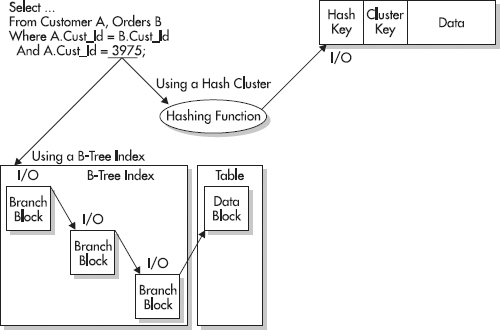
Figure 1. Using hash indexes
Hash indexes can potentially be the fastest way to access data in the database, but they do come with their drawbacks. The number of distinct values for the cluster key needs to be known before creating the hash cluster. This value needs to be specified at the time of creation. Underestimating the number of distinct values can cause collisions (two cluster key values with the same hash value) within the cluster, which are very costly. Collisions cause overflow buffers to be used to store the additional rows, thus causing additional I/O. If the number of distinct hash values has been underestimated, the cluster will need to be re-created to alter the value. An ALTER CLUSTER command cannot change the number of HASHKEYS.
Hash clusters have a tendency to waste space. If it is not possible to determine how much space is required to hold all of the rows for a given cluster key, space may be wasted. If it is not possible to allocate additional space within the cluster for future growth, then hash clusters may not be the best option.
If the application often performs full table scans on the clustered table(s), hash clusters may not be the appropriate option. Because of the amount of empty space within the cluster to allow for future growth, full table scans can be very resource-intensive.
Caution should be taken before implementing hash clusters. Revise the application fully to ensure that enough information is known about the tables and data before implementing this option. Generally, hashing is best for static data with primarily sequential values.
TIP
Hash indexes are most useful when the limiting condition specifies an exact value rather than a range of values.
[…] Hash Indexes […]